机器学习算法(优化)之一:梯度下降算法、随机梯度下降(应用于线性回归、Logistic回归等等)
本文介绍了机器学习中基本的优化算法—梯度下降算法和随机梯度下降算法,以及实际应用到线性回归、Logistic回归、矩阵分解推荐算法等ML中。
梯度下降算法基本公式
常见的符号说明和损失函数
X :所有样本的特征向量组成的矩阵
x(i) 是第i个样本包含的所有特征组成的向量x(i)=(x(i)1,x(i)2...,x(i)n)
y(i) 第i个样本的label,每个样本只有一个label,y(i)是标量(一个数值)
hθ(x(i)) :拟合函数,机器学习中可以用多种类型的拟合函数
θ 是函数变量,是多个变量的向量 θ=[θ1,θ2,...]
|hθ(xi)−y(i)| :拟合绝对误差
求解的目标是使得所有样本点(m个)平均误差最小,即:
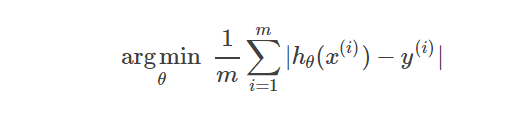
或者平方误差最小,即:
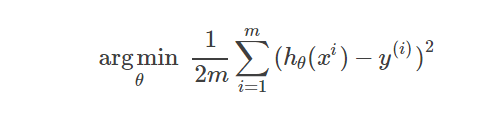
argmin表示使目标函数取最小值时的变量值(即θ)值。
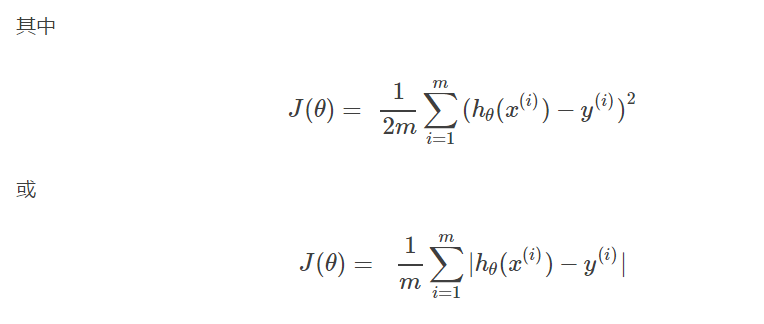
都被称为损失函数(Cost Function)
J(θ)不只是上面两种形式,不同的机器学习算法可以定义各种其它形式。
梯度下降迭代公式
为了求解θ=[θ1,θ2,...]的值,可以先对其赋一组初值,然后改变θ的值,使得J(θ)最小。函数J(θ)在其负梯度方向下降最快,所以只要使得每个参数θ按函数负梯度方向改变,则J(θ)能最快找到最小值。即

这就是梯度下降算法的迭代公式,其中α表示步长,即往每次下降最快的方向走多远。
线性回归
以多变量线性回归为例:
拟合函数如下:

Logistic回归
代价函数:
以Sigmoid函数(Logistic函数)为例说明:
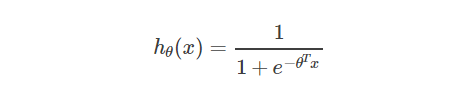

为什么这么定义代价函数呢?我自己通俗理解是,求导后形式简洁,而且:
y=0,hθ(x)范围为[0,0.5),越接近0.5,代价越高: 
由上图可以看出:−log(1−hθ(x(i)))可以很好衡量某一个样本的代价。
y=1时,hθ(x)范围为(0.5,1],越接近0.5,代价越高: 
同样由上图可以看到:−loghθ(x(i))可以很好衡量某一个样本的代价。
迭代更新公式:
求导过程蛮复杂的,直接给出结果吧:

和线性回归中最后给的更新迭代公式是一模一样的,这也就理解了为什么代价函数设计时比较复杂,还套了log,敢情是为了这??
总之logisitc回归和线性回归最终使用的是一模一样的优化算法。
还可将这个公式写成用向量来表达的形式:
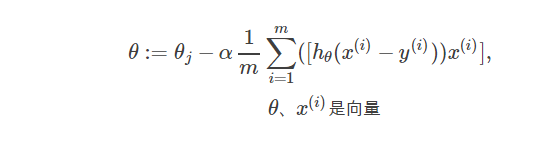
矩阵分解的推荐算法
可以参考我转载的另一篇文章: http://www.cnblogs.com/kobedeshow/p/3651833.html?utm_source=tuicool&utm_medium=referral
随机梯度下降(SGD)
stochastic gradient descent
从梯度上升算法公式可以看出,每次更新回归系数θ时都需要遍历整个数据集。该方法在处理100个左右的数据集尚可,但是如果有数十亿的样本和成千万的特征,这种方法的计算复杂度就太高了。一种改进的方法是一次仅用一个样本点来更新回归系数。由于可以在新样本到来时,对分类器进行增量更新,因此是一个“在线学习”算法,而梯度下降算法一次处理所有的数据被称为“批处理”。更新公式如下:
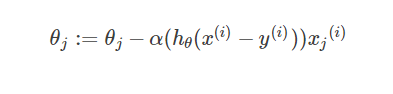
参考文献
(1)Stanford机器学习—第三讲. 逻辑回归和过拟合问题的解决 logistic Regression & Regularization
http://blog.csdn.net/abcjennifer/article/details/7716281?locationNum=2
(2)机器学习入门:线性回归及梯度下降
http://blog.csdn.net/xiazdong/article/details/7950084
(3)梯度下降深入浅出
http://binhua.info/machinelearning/%E6%A2%AF%E5%BA%A6%E4%B8%8B%E9%99%8D%E6%B7%B1%E5%85%A5%E6%B5%85%E5%87%BA
机器学习算法(优化)之一:梯度下降算法、随机梯度下降(应用于线性回归、Logistic回归等等)的更多相关文章
- Andrew Ng机器学习算法入门(四):阶梯下降算法
梯度降级算法简介 之前如果需要求出最佳的线性回归模型,就需要求出代价函数的最小值.在上一篇文章中,求解的问题比较简单,只有一个简单的参数.梯度降级算法就可以用来求出代价函数最小值. 梯度降级算法的在维 ...
- 机器学习之线性回归---logistic回归---softmax回归
在本节中,我们介绍Softmax回归模型,该模型是logistic回归模型在多分类问题上的推广,在多分类问题中,类标签 可以取两个以上的值. Softmax回归模型对于诸如MNIST手写数字分类等问题 ...
- NN优化方法对照:梯度下降、随机梯度下降和批量梯度下降
1.前言 这几种方法呢都是在求最优解中常常出现的方法,主要是应用迭代的思想来逼近.在梯度下降算法中.都是环绕下面这个式子展开: 当中在上面的式子中hθ(x)代表.输入为x的时候的其当时θ參数下的输出值 ...
- 监督学习:随机梯度下降算法(sgd)和批梯度下降算法(bgd)
线性回归 首先要明白什么是回归.回归的目的是通过几个已知数据来预测另一个数值型数据的目标值. 假设特征和结果满足线性关系,即满足一个计算公式h(x),这个公式的自变量就是已知的数据x,函数值h(x)就 ...
- 监督学习——随机梯度下降算法(sgd)和批梯度下降算法(bgd)
线性回归 首先要明白什么是回归.回归的目的是通过几个已知数据来预测另一个数值型数据的目标值. 假设特征和结果满足线性关系,即满足一个计算公式h(x),这个公式的自变量就是已知的数据x,函数值h(x)就 ...
- Logistic回归Cost函数和J(θ)的推导(二)----梯度下降算法求解最小值
前言 在上一篇随笔里,我们讲了Logistic回归cost函数的推导过程.接下来的算法求解使用如下的cost函数形式: 简单回顾一下几个变量的含义: 表1 cost函数解释 x(i) 每个样本数据点在 ...
- 1. 批量梯度下降法BGD 2. 随机梯度下降法SGD 3. 小批量梯度下降法MBGD
排版也是醉了见原文:http://www.cnblogs.com/maybe2030/p/5089753.html 在应用机器学习算法时,我们通常采用梯度下降法来对采用的算法进行训练.其实,常用的梯度 ...
- sklearn中实现随机梯度下降法(多元线性回归)
sklearn中实现随机梯度下降法 随机梯度下降法是一种根据模拟退火的原理对损失函数进行最小化的一种计算方式,在sklearn中主要用于多元线性回归算法中,是一种比较高效的最优化方法,其中的梯度下降系 ...
- 机器学习之Logistic 回归算法
1 Logistic 回归算法的原理 1.1 需要的数学基础 我在看机器学习实战时对其中的代码非常费解,说好的利用偏导数求最值怎么代码中没有体现啊,就一个简单的式子:θ= θ - α Σ [( hθ( ...
随机推荐
- scanner, BufferedReader, InputStreamReader 区别及特殊字符的输入
1. Scanner是一个可以使用正则表达式来分析基本类型和字符串的简单文本扫描器!也就是控制台应用程序最为常用的文本输入方式!Scanner取得输入数据的依据是空格符:如按下空格键,Tab键或者En ...
- 【BZOJ】1668: [Usaco2006 Oct]Cow Pie Treasures 馅饼里的财富(dp)
http://www.lydsy.com/JudgeOnline/problem.php?id=1668 裸dp.. f[i][j]表示i行j列最大能拿到 f[i][j]=max(f[i+1][j-1 ...
- Python3创建RIDE桌面快捷方式的另一种方法
今天尝试了一下Python3下安装Robot Framework,但是原来的Python2下创建ride快捷方式的方法都不奏效,启动不了ride.于是,转为VBS脚本的方式来间接创建快捷方式.毕竟,每 ...
- Linux性能分析top iostat vmstat free
最近看到一大牛的分析报告,才知道笔者认识这4个命令是多么肤浅,其实要读懂内存的信息,是要一些功力的.1.top VIRT 虚拟内存总量,VIRT=SWAP+RESSWAP ...
- 《C++ Primer Plus》学习笔记 2.1.1 main()函数
main()函数的基本结构如下: int main() { statements ; } 这几行代码构成了函数定义(function definition),该定义由两部分组成: 第一行int mai ...
- 折腾deeplin系统
1.双系统失败记录 多系统启动问题 先安装完deepin,发现再安装windows怎么都起不起来,哪怕他们已经安装在不同的盘 (体现再Windows7通过ghost位于另外一个盘,但就是没有启动项) ...
- 160524、Linux下如何启动、关闭Oracle以及打开关闭监听
1. linux下启动oraclesu - oraclesqlplus /nologconn /as sysdbastartupexitlsnrctl startexit2. linux下关闭orac ...
- HDU 4605 Magic Ball Game(可持续化线段树,树状数组,离散化)
Magic Ball Game Time Limit: 10000/5000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others) ...
- 论OI中无穷大(INF)的取值
水 为什么我的Floyd会输出负数啊? 为什么我的代码写对了却全都爆零了啊? 那么很可能是你的INF取大/小了! 那么inf到底应该取什么值呢? 首先,inf应该要比一般的题目中出现的数据要大,但是又 ...
- 2017 Multi-University Training Contest - Team 6—HDU6098&&HDU6106&&HDU6103
HDU6098 Inversion 题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=6098 题目意思:题目很短,给出一个数组,下标从1开始,现在输出一个 ...