Ternary weight networks
Introduction
这两天看了一下这篇文章,我就这里分享一下,不过我还是只记录一下跟别人blog上没有,或者自己的想法(ps: 因为有时候翻blog时候发现每篇都一样还是挺烦的= =) 。为了不重复前人的工作,我post一个不小心翻到的博客权值简化(1):三值神经网络(Ternary Weight Networks),整个论文内容及实现都讲的很全面了,可以翻阅一下,我也借鉴一下。
文中主要工作的点在三个方面:
- 增加了网络的表达力(expressive ability)。在{1,0,1}基础上增加了 \(\alpha\) 作为scaled factor;
- 压缩模型大小。当然主要是weight的压缩。比起FPWN(full precision weight network)有16~32x的提升,但是BPWN(binary precision weight network)的2x大小(ps:当然在TWN的caffe代码里面,都由float double类型存储,因为这需要在应该上方面来实现);
- 减少计算需求。主要相比于BPWN增多了0,当然这方面也需硬件来获得提升,在该caffe代码里面并没有;
Ternary Quantization
在我的理解看来,文中最核心的内容是:将有约束的并且两变量之间互相依赖的优化问题,逐步拆分最后用具有先验的统计方法来近视解决。
最初的优化问题:

将\(W^{t}\)的约束具体化为:
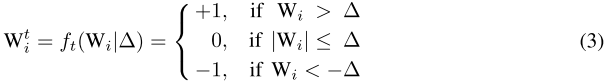
并将其带入公式(1),将\(W^{t*}\)的优化转化为\(\Delta^*\)的优化:
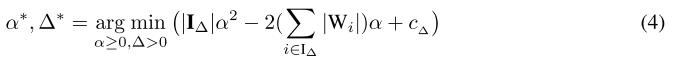
然后对公式(4)中的\(\alpha\)求偏导,得到:

因为\(\alpha\)和\(\Delta\)相互依赖,将(5)代入(4)消去\(\alpha\):

但问题来了,公式(6)依然没法求,而文中就根据先验知识,假设\(W_i\)服从\(N(0,\sigma^2)\)分布,近视的\(\Delta^*\)为\(0.6\sigma\)(\(0.6\sigma\)等于\(0.75E(|W|)\))。因此作者采用粗暴的方法,把\(\Delta^*\)设为\(\Delta^*\approx0.7E(|W|)\approx\frac{n}{0.7}\sum_{i=1}^n|W_i|\)
//caffe-twns
//blob.cpp
template <typename Dtype>
void Blob<Dtype>::set_delta(){
float scale_factor = TERNARY_DELTA * 1.0 / 10; //delta = 0.7
Dtype delta = (Dtype) scale_factor * this->asum_data() / this->count(); // 0.7*(E|W_i|)/num
delta = (delta <= 100) ? delta : 100;
delta = (delta >= -100) ? delta : -100;
this->delta_ = delta;
}
template <typename Dtype>
void Blob<Dtype>::set_delta(Dtype delta){
delta = (delta <= 100) ? delta : 100;
delta = (delta >= -100) ? delta : -100;
this->delta_ = delta;
}
Implement
我借用一张图

步骤3~5,其中第5步代码在上面:
template <typename Dtype>
void Blob<Dtype>::ternarize_data(Phase phase){
if(phase == RUN){
// if(DEBUG) print_head();
//LOG(INFO) << "RUN phase...";
// caffe_sleep(3);
return; // do nothing for the running phase
}else if(phase == TRAIN){
//LOG(INFO) << "TRAIN phase ...";
// caffe_sleep(3);
}else{
//LOG(INFO) << "TEST phase ...";
// caffe_sleep(3);
}
// const Dtype delta = 0; // default value;
// const Dtype delta = (Dtype) 0.8 * this->asum_data() / this->count();
this->set_delta(); //defualt 0.7*(E|W_i|)/num or set by user
const Dtype delta = this->get_delta();
Dtype alpha = 1;
if (!data_) { return; }
switch (data_->head()) {
case SyncedMemory::HEAD_AT_CPU:
{
caffe_cpu_ternary<Dtype>(this->count(), delta, this->cpu_data(), this->mutable_cpu_binary()); //quantized weight to ternary
alpha = caffe_cpu_dot(this->count(), this->cpu_binary(), this->cpu_data()); //scale-alpha: (E |W_i|) i belong to I_delta
alpha /= caffe_cpu_dot(this->count(), this->cpu_binary(), this->cpu_binary()); //(1/num_binary)*alpha
caffe_cpu_scale(this->count(), alpha, this->cpu_binary(), this->mutable_cpu_binary());
// this->set_alpha(alpha);
}
return;
case SyncedMemory::HEAD_AT_GPU:
case SyncedMemory::SYNCED:
#ifndef CPU_ONLY
{
caffe_gpu_ternary<Dtype>(this->count(), delta, this->gpu_data(), this->mutable_gpu_binary());
Dtype* pa = new Dtype(0);
caffe_gpu_dot(this->count(), this->gpu_binary(), this->gpu_data(), pa);
Dtype* pb = new Dtype(0);
caffe_gpu_dot(this->count(), this->gpu_binary(), this->gpu_binary(), pb);
alpha = (*pa) / ((*pb) + 1e-6);
this->set_alpha(alpha);
caffe_gpu_scale(this->count(), alpha, this->gpu_binary(), this->mutable_gpu_binary());
// this->set_alpha((Dtype)1);
// LOG(INFO) << "alpha = " << alpha;
// caffe_sleep(3);
}
return;
#else
NO_GPU;
#endif
case SyncedMemory::UNINITIALIZED:
return;
default:
LOG(FATAL) << "Unknown SyncedMemory head state: " << data_->head();
}
}
步骤6~7,其中在第6步作者在caffe-twns直接采用传统caffe的方法,而$Z=XW\approx X(\alpha W^t)=(\alpha X)\bigoplus W^t $更偏向与在硬件加速的优化(因为本身在caffe-twns的ternary就采用float或者double,并且用blas或cudnn加速也无法直接跳过0值):
//conv_layer.cpp
template <typename Dtype>
void ConvolutionLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
// const Dtype* weight = this->blobs_[0]->cpu_data();
if(BINARY){
this->blobs_[0]->binarize_data();
}
if(TERNARY){
this->blobs_[0]->ternarize_data(this->phase_); //quantized from blob[0] to ternary sand stored in cpu_binary()
/*
Dtype alpha = (Dtype) this->blobs_[0]->get_alpha();
for(int i=0; i<bottom.size(); i++){
Blob<Dtype>* blob = bottom[i];
caffe_cpu_scale(blob->count(), alpha, blob->cpu_data(), blob->mutable_cpu_data());
}
*/
}
const Dtype* weight = (BINARY || TERNARY) ? this->blobs_[0]->cpu_binary() : this->blobs_[0]->cpu_data();
...
}
步骤11~19,weight的Update是在full precision上,而计算gradient则是用ternary weight:
//conv_layer.cpp
template <typename Dtype>
void ConvolutionLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom) {
const Dtype* weight = this->blobs_[0]->cpu_data();
Dtype* weight_diff = this->blobs_[0]->mutable_cpu_diff();
for (int i = 0; i < top.size(); ++i) {
...
if (this->param_propagate_down_[0] || propagate_down[i]) {
for (int n = 0; n < this->num_; ++n) {
// gradient w.r.t. weight. Note that we will accumulate diffs.
if (this->param_propagate_down_[0]) {
this->weight_cpu_gemm(bottom_data + n * this->bottom_dim_,
top_diff + n * this->top_dim_, weight_diff);
}
// gradient w.r.t. bottom data, if necessary.
if (propagate_down[i]) {
this->backward_cpu_gemm(top_diff + n * this->top_dim_, weight,
bottom_diff + n * this->bottom_dim_);
}
}
}
}
}
Ternary weight networks的更多相关文章
- 论文翻译:Ternary Weight Networks
目录 Abstract 1 Introduction 1.1 Binary weight networks and model compression 2 Ternary weight network ...
- [综述]Deep Compression/Acceleration深度压缩/加速/量化
Survey Recent Advances in Efficient Computation of Deep Convolutional Neural Networks, [arxiv '18] A ...
- zz神经网络模型量化方法简介
神经网络模型量化方法简介 https://chenrudan.github.io/blog/2018/10/02/networkquantization.html 2018-10-02 本文主要梳理了 ...
- deeplearning模型量化实战
deeplearning模型量化实战 MegEngine 提供从训练到部署完整的量化支持,包括量化感知训练以及训练后量化,凭借"训练推理一体"的特性,MegEngine更能保证量化 ...
- Understanding the Effective Receptive Field in Deep Convolutional Neural Networks
Understanding the Effective Receptive Field in Deep Convolutional Neural Networks 理解深度卷积神经网络中的有效感受野 ...
- [C6] Andrew Ng - Convolutional Neural Networks
About this Course This course will teach you how to build convolutional neural networks and apply it ...
- [CS231n-CNN] Training Neural Networks Part 1 : activation functions, weight initialization, gradient flow, batch normalization | babysitting the learning process, hyperparameter optimization
课程主页:http://cs231n.stanford.edu/ Introduction to neural networks -Training Neural Network ________ ...
- 【转】Artificial Neurons and Single-Layer Neural Networks
原文:written by Sebastian Raschka on March 14, 2015 中文版译文:伯乐在线 - atmanic 翻译,toolate 校稿 This article of ...
- 一天一经典Reducing the Dimensionality of Data with Neural Networks [Science2006]
别看本文没有几页纸,本着把经典的文多读几遍的想法,把它彩印出来看,没想到效果很好,比在屏幕上看着舒服.若用蓝色的笔圈出重点,这篇文章中几乎要全蓝.字字珠玑. Reducing the Dimensio ...
随机推荐
- JVM 专题五:类加载子系统(三)补充内容
3. 补充内容 3.1 在jvm中表示两个class对象是否为同一个类的两个必要条件 类的完整类名必须一致,包括包名. 加载这个类的ClassLoader(指ClassLoader实例对象)必须相同 ...
- Java并发编程实践
最近阅读了<Java并发编程实践>这本书,总结了一下几个相关的知识点. 线程安全 当多个线程访问某个类时,不管运行时环境采用何种调度方式或者这些线程将如何交替执行,并且在主调代码中不需要任 ...
- 也来谈谈python编码
一.coding:utf-8 让我们先来看一个示例,源码文件是utf-8格式: print('你好 python') 当使用python2执行该程序时会收到一下报错: File "./hel ...
- 02-flask项目创建及debug模式的开启
一.flask文件的创建 打开pycharm,选择flask文件,选择相关配置,需要配置的有虚拟环境,flask文件名.如下图所示: 新建的flask文件如下所示: static:用来存放静态文件,包 ...
- 软件测试中的微信小程序怎么测试?
1.没有需求文档时,如何测试小程序?现在大多数公司的开发模式是:敏捷模式(用户故事) ,即以什么身份做什么事情会出现什么样的结果.那实际测试过程中,没有需求文档时,测试可以采用以下方式更好的完成测试工 ...
- GPO - Disabling Task Manager Access
Create a GPO to disable Task Manager Access to normal users. Add an exception to Domain Admins.
- SpringBoot2.x入门:使用MyBatis
这是公众号<Throwable文摘>发布的第25篇原创文章,收录于专辑<SpringBoot2.x入门>. 前提 这篇文章是<SpringBoot2.x入门>专辑的 ...
- Python基础知识点:多进程的应用讲解
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:东哥IT笔记 现在很多CPU都支持多核,甚至是手机都已经开始支持多核 ...
- python读取hdfs上的parquet文件方式
在使用python做大数据和机器学习处理过程中,首先需要读取hdfs数据,对于常用格式数据一般比较容易读取,parquet略微特殊.从hdfs上使用python获取parquet格式数据的方法(当然也 ...
- 关于C# winform唤起本地已安装应用程序(测试win10,win7可用)
想要唤起本地已安装应用程序,我想到的有三种可行的方法: 第一种就是打开本地的快捷方式(有的应用可能没有快捷方式,但这种方法效率最高,可配合其他方法使用),快捷方式分为本地桌面快捷方式和开始菜单中的快捷 ...