拓扑排序(一)之 C语言详解
本章介绍图的拓扑排序。和以往一样,本文会先对拓扑排序的理论知识进行介绍,然后给出C语言的实现。后续再分别给出C++和Java版本的实现。
目录
1. 拓扑排序介绍
2. 拓扑排序的算法图解
3. 拓扑排序的代码说明
4. 拓扑排序的完整源码和测试程序转载请注明出处:http://www.cnblogs.com/skywang12345/
更多内容:数据结构与算法系列 目录
拓扑排序介绍
拓扑排序(Topological Order)是指,将一个有向无环图(Directed Acyclic Graph简称DAG)进行排序进而得到一个有序的线性序列。
这样说,可能理解起来比较抽象。下面通过简单的例子进行说明!
例如,一个项目包括A、B、C、D四个子部分来完成,并且A依赖于B和D,C依赖于D。现在要制定一个计划,写出A、B、C、D的执行顺序。这时,就可以利用到拓扑排序,它就是用来确定事物发生的顺序的。
在拓扑排序中,如果存在一条从顶点A到顶点B的路径,那么在排序结果中B出现在A的后面。
拓扑排序的算法图解
拓扑排序算法的基本步骤:
1. 构造一个队列Q(queue) 和 拓扑排序的结果队列T(topological);
2. 把所有没有依赖顶点的节点放入Q;
3. 当Q还有顶点的时候,执行下面步骤:
3.1 从Q中取出一个顶点n(将n从Q中删掉),并放入T(将n加入到结果集中);
3.2 对n每一个邻接点m(n是起点,m是终点);
3.2.1 去掉边<n,m>;
3.2.2 如果m没有依赖顶点,则把m放入Q;
注:顶点A没有依赖顶点,是指不存在以A为终点的边。
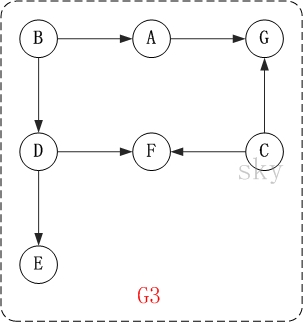
以上图为例,来对拓扑排序进行演示。

第1步:将B和C加入到排序结果中。
顶点B和顶点C都是没有依赖顶点,因此将C和C加入到结果集T中。假设ABCDEFG按顺序存储,因此先访问B,再访问C。访问B之后,去掉边<B,A>和<B,D>,并将A和D加入到队列Q中。同样的,去掉边<C,F>和<C,G>,并将F和G加入到Q中。
(01) 将B加入到排序结果中,然后去掉边<B,A>和<B,D>;此时,由于A和D没有依赖顶点,因此并将A和D加入到队列Q中。
(02) 将C加入到排序结果中,然后去掉边<C,F>和<C,G>;此时,由于F有依赖顶点D,G有依赖顶点A,因此不对F和G进行处理。
第2步:将A,D依次加入到排序结果中。
第1步访问之后,A,D都是没有依赖顶点的,根据存储顺序,先访问A,然后访问D。访问之后,删除顶点A和顶点D的出边。
第3步:将E,F,G依次加入到排序结果中。
因此访问顺序是:B -> C -> A -> D -> E -> F -> G
拓扑排序的代码说明
拓扑排序是对有向无向图的排序。下面以邻接表实现的有向图来对拓扑排序进行说明。
1. 基本定义
// 邻接表中表对应的链表的顶点
typedef struct _ENode
{
int ivex; // 该边所指向的顶点的位置
struct _ENode *next_edge; // 指向下一条弧的指针
}ENode, *PENode;
// 邻接表中表的顶点
typedef struct _VNode
{
char data; // 顶点信息
ENode *first_edge; // 指向第一条依附该顶点的弧
}VNode;
// 邻接表
typedef struct _LGraph
{
int vexnum; // 图的顶点的数目
int edgnum; // 图的边的数目
VNode vexs[MAX];
}LGraph;
(01) LGraph是邻接表对应的结构体。 vexnum是顶点数,edgnum是边数;vexs则是保存顶点信息的一维数组。
(02) VNode是邻接表顶点对应的结构体。 data是顶点所包含的数据,而firstedge是该顶点所包含链表的表头指针。
(03) ENode是邻接表顶点所包含的链表的节点对应的结构体。 ivex是该节点所对应的顶点在vexs中的索引,而nextedge是指向下一个节点的。
2. 拓扑排序
/*
* 拓扑排序
*
* 参数说明:
* G -- 邻接表表示的有向图
* 返回值:
* -1 -- 失败(由于内存不足等原因导致)
* 0 -- 成功排序,并输入结果
* 1 -- 失败(该有向图是有环的)
*/
int topological_sort(LGraph G)
{
int i,j;
int index = 0;
int head = 0; // 辅助队列的头
int rear = 0; // 辅助队列的尾
int *queue; // 辅组队列
int *ins; // 入度数组
char *tops; // 拓扑排序结果数组,记录每个节点的排序后的序号。
int num = G.vexnum;
ENode *node;
ins = (int *)malloc(num*sizeof(int)); // 入度数组
tops = (char *)malloc(num*sizeof(char));// 拓扑排序结果数组
queue = (int *)malloc(num*sizeof(int)); // 辅助队列
assert(ins!=NULL && tops!=NULL && queue!=NULL);
memset(ins, 0, num*sizeof(int));
memset(tops, 0, num*sizeof(char));
memset(queue, 0, num*sizeof(int));
// 统计每个顶点的入度数
for(i = 0; i < num; i++)
{
node = G.vexs[i].first_edge;
while (node != NULL)
{
ins[node->ivex]++;
node = node->next_edge;
}
}
// 将所有入度为0的顶点入队列
for(i = 0; i < num; i ++)
if(ins[i] == 0)
queue[rear++] = i; // 入队列
while (head != rear) // 队列非空
{
j = queue[head++]; // 出队列。j是顶点的序号
tops[index++] = G.vexs[j].data; // 将该顶点添加到tops中,tops是排序结果
node = G.vexs[j].first_edge; // 获取以该顶点为起点的出边队列
// 将与"node"关联的节点的入度减1;
// 若减1之后,该节点的入度为0;则将该节点添加到队列中。
while(node != NULL)
{
// 将节点(序号为node->ivex)的入度减1。
ins[node->ivex]--;
// 若节点的入度为0,则将其"入队列"
if( ins[node->ivex] == 0)
queue[rear++] = node->ivex; // 入队列
node = node->next_edge;
}
}
if(index != G.vexnum)
{
printf("Graph has a cycle\n");
free(queue);
free(ins);
free(tops);
return 1;
}
// 打印拓扑排序结果
printf("== TopSort: ");
for(i = 0; i < num; i ++)
printf("%c ", tops[i]);
printf("\n");
free(queue);
free(ins);
free(tops);
return 0;
}
说明:
(01) queue的作用就是用来存储没有依赖顶点的顶点。它与前面所说的Q相对应。
(02) tops的作用就是用来存储排序结果。它与前面所说的T相对应。
拓扑排序的完整源码和测试程序
拓扑排序(一)之 C语言详解的更多相关文章
- 原来Github上的README.md文件这么有意思——Markdown语言详解(sublime text2 版本)
一直想学习 Markdown 语言,想起以前读的一篇 赵凯强 的 博客 <原来Github上的README.md文件这么有意思——Markdown语言详解>,该篇博主 使用的是Mac系统, ...
- python 排序算法总结及实例详解
python 排序算法总结及实例详解 这篇文章主要介绍了python排序算法总结及实例详解的相关资料,需要的朋友可以参考下 总结了一下常见集中排序的算法 排序算法总结及实例详解"> 归 ...
- Java Web----EL(表达式语言)详解
Java Web中的EL(表达式语言)详解 表达式语言(Expression Language)简称EL,它是JSP2.0中引入的一个新内容.通过EL可以简化在JSP开发中对对象的引用,从而规范页面 ...
- Prim算法(一)之 C语言详解
本章介绍普里姆算法.和以往一样,本文会先对普里姆算法的理论论知识进行介绍,然后给出C语言的实现.后续再分别给出C++和Java版本的实现. 目录 1. 普里姆算法介绍 2. 普里姆算法图解 3. 普里 ...
- Kruskal算法(一)之 C语言详解
本章介绍克鲁斯卡尔算法.和以往一样,本文会先对克鲁斯卡尔算法的理论论知识进行介绍,然后给出C语言的实现.后续再分别给出C++和Java版本的实现. 目录 1. 最小生成树 2. 克鲁斯卡尔算法介绍 3 ...
- Django 模版语言详解
一.简介 模版是纯文本文件.它可以产生任何基于文本的的格式(HTML,XML,CSV等等). 模版包括在使用时会被值替换掉的 变量,和控制模版逻辑的 标签. 例: {% extends "b ...
- Fluter基础巩固之Dart语言详解<一>
在上一篇https://www.cnblogs.com/webor2006/p/11367345.html中咱们已经搭建好了Flutter的开发环境了,而Flutter的开发语言是选用的dart,那么 ...
- 大牛针对零基础入门c语言详解指针(超详细)
C语言指针说难不难但是说容易又是最容易出错的地方,因此不管是你要做什么只要用到C指针你就跳不过,今天咱们就以 十九个例子来给大家简单的分析一下指针的应用,最后会有C语言视频资料提供给大家更加深入的参考 ...
- SQL语言详解
SQL 1. 概述 Structured Query Language 结构化查询语言 结构化查询语言(Structured Query Language)简称SQL,是一种数据库查询和程序设计语言, ...
随机推荐
- oracle表空间不足时的处理方法
由于数据文件路径下的空间不足或表空间不足时,需要更换或扩展或新增表空间时,以下简单介绍下几种处理方式(数据文件/opt/oracle/oradata/testdb.dbf,原大小为100M) 一.扩大 ...
- mysql 按时间段统计(年,季度,月,天,时)
按年汇总,统计: select sum(mymoney) as totalmoney, count(*) as sheets from mytable group by date_format(col ...
- Linux磁盘管理
本系列的博客来自于:http://www.92csz.com/study/linux/ 在此,感谢原作者提供的入门知识 这个系列的博客的目的在于将比较常用的liunx命令从作者的文章中摘录下来,供自己 ...
- PAT/图形输出习题集
B1027. 打印沙漏 (20) Description: 本题要求你写个程序把给定的符号打印成沙漏的形状.例如给定17个"*",要求按下列格式打印 ***** *** * *** ...
- 奇妙的动态代理:EF中返回的对象为什么序列化失败
今天有如鹏的学生遇到一个问题:把一个对象保存到Session中(进程外Session)后,Web服务器重启,当从Session读取这个对象的时候报错,提示是一个“T_Users”后面跟着一大串数字的类 ...
- 创建动态WCF服务(无配置文件)
public class WCFServer { ServiceHost host = null; public WCFServer(string addressurl, string tcpurl, ...
- mvvm的优势
之前在项目中有个功能,是根据数据模型生成页面,然后页面变动之后,再同步到数据模型之中. 当时用的jquery写的,一点一点的控制,整个功能写下来.测试,花了很长时间,而且还担心出bug. 现在用mvv ...
- Spring AOP在函数接口调用性能分析及其日志处理方面的应用
面向切面编程可以实现在不修改原来代码的情况下,增加我们所需的业务处理逻辑,比如:添加日志.本文AOP实例是基于Aspect Around注解实现的,我们需要在调用API函数的时候,统计函数调用的具体信 ...
- PSP个人耗时
PSP2.1 Personal Software Process Stage Time(min) Planing 计划 20 #Estimate #估计这个任务需要多长时间 180 Developi ...
- WPF 编辑状态切换
有时候DataGrid编辑的时候一个属性需要根据别的属性呈现不同的编辑状态.这就需要一个做一个状态切换.比如地址是1的时候,读写类型是读写.只读.只写.地址是2的时候,就只读.状态栏切换为TextBo ...