Spark RDD/Core 编程 API入门系列 之rdd案例(map、filter、flatMap、groupByKey、reduceByKey、join、cogroupy等)(四)
声明:
大数据中,最重要的算子操作是:join !!!
典型的transformation和action


val nums = sc.parallelize(1 to 10) //根据集合创建RDD
map适用于
package com.zhouls.spark.cores
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by Administrator on 2016/9/27.
*/
object Transformations {
def main(args: Array[String]) {
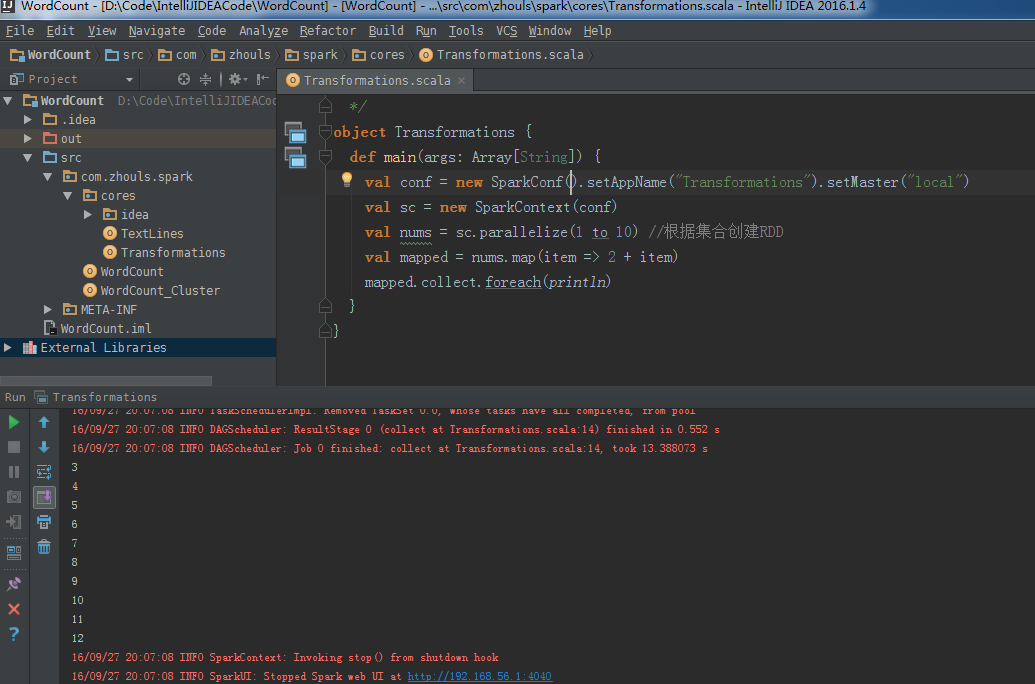
val conf = new SparkConf().setAppName("Transformations").setMaster("local")
val sc = new SparkContext(conf)
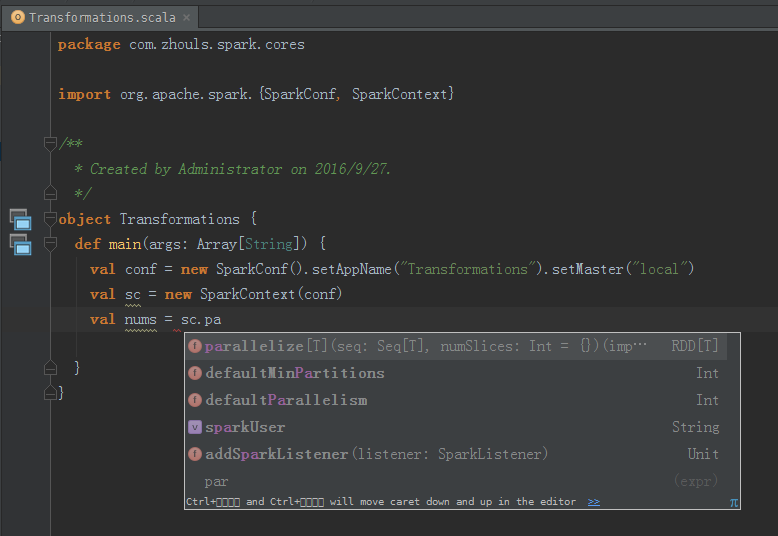
val nums = sc.parallelize(1 to 10) //根据集合创建RDD
val mapped = nums.map(item => 2 + item)
mapped.collect.foreach(println)
}
}
map源码
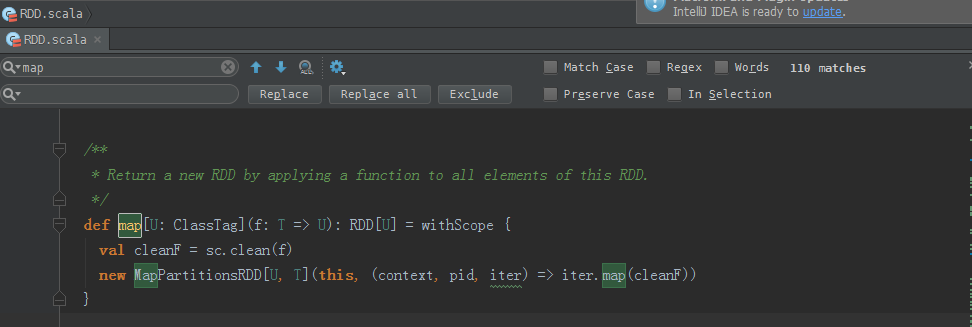
/**
* Return a new RDD by applying a function to all elements of this RDD.
*/
def map[U: ClassTag](f: T => U): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.map(cleanF))
}
filter适用于
package com.zhouls.spark.cores
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by Administrator on 2016/9/27.
*/
object Transformations {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("Transformations").setMaster("local")
val sc = new SparkContext(conf)
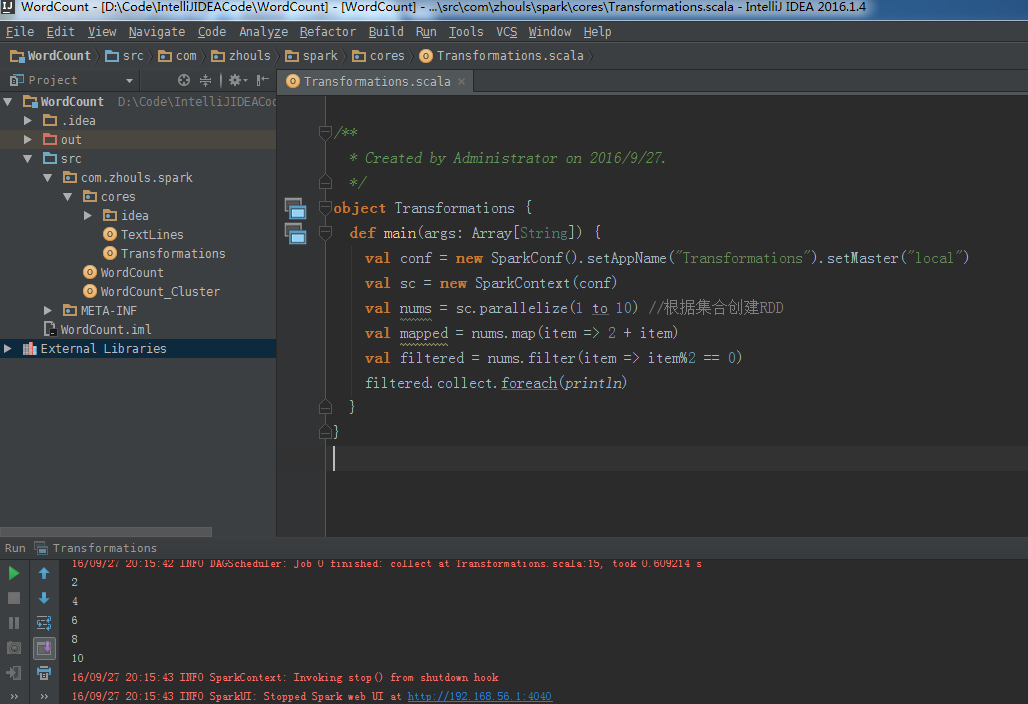
val nums = sc.parallelize(1 to 10) //根据集合创建RDD
val mapped = nums.map(item => 2 + item)
val filtered = nums.filter(item => item%2 == 0)
filtered.collect.foreach(println)
}
}
filter源码
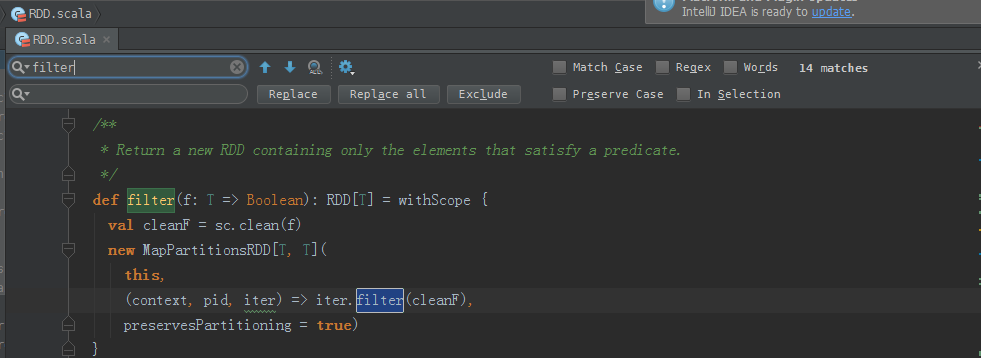
/**
* Return a new RDD containing only the elements that satisfy a predicate.
*/
def filter(f: T => Boolean): RDD[T] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[T, T](
this,
(context, pid, iter) => iter.filter(cleanF),
preservesPartitioning = true)
}
flatMap适用于
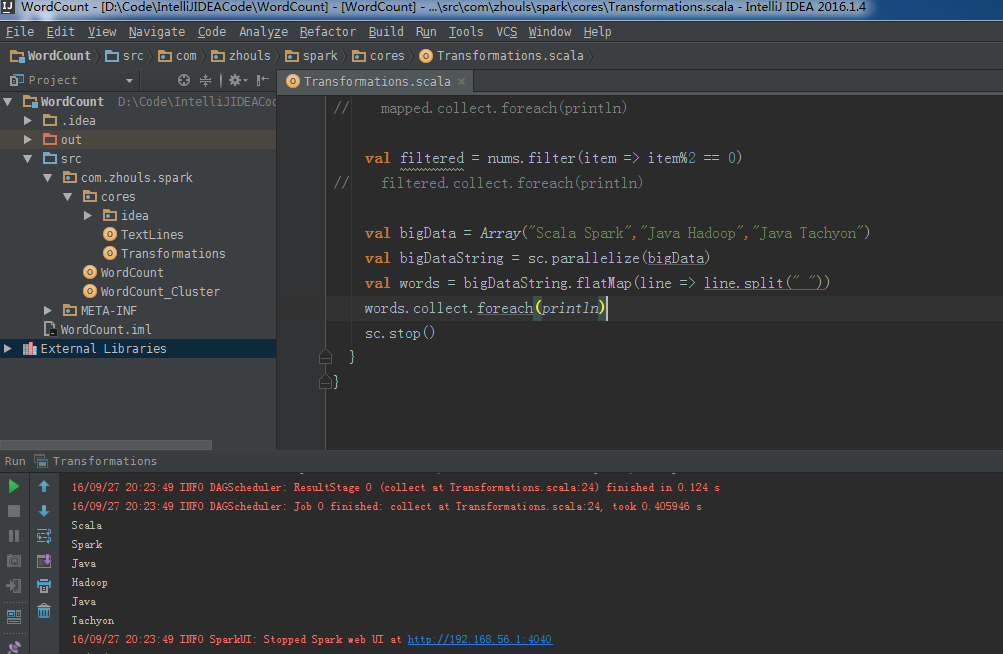
package com.zhouls.spark.cores
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by Administrator on 2016/9/27.
*/
object Transformations {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("Transformations").setMaster("local")
val sc = new SparkContext(conf)
val nums = sc.parallelize(1 to 10) //根据集合创建RDD
val mapped = nums.map(item => 2 + item)
// mapped.collect.foreach(println)
val filtered = nums.filter(item => item%2 == 0)
// filtered.collect.foreach(println)
val bigData = Array("Scala Spark","Java Hadoop","Java Tachyon")
val bigDataString = sc.parallelize(bigData)
val words = bigDataString.flatMap(line => line.split(" "))
words.collect.foreach(println)
sc.stop()
}
}
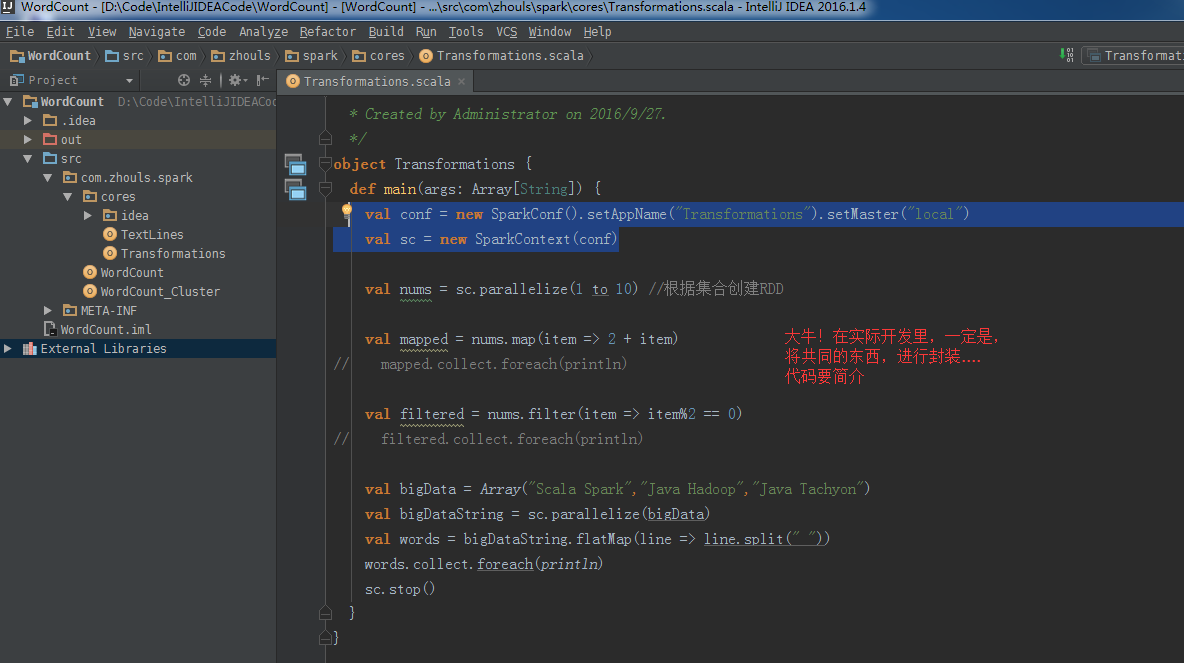
flatMap源码
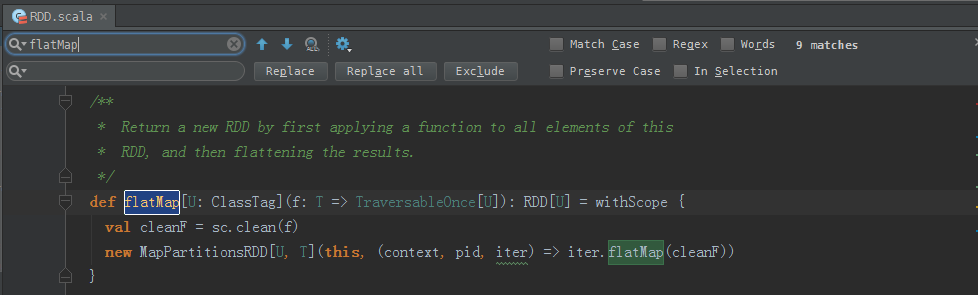
/**
* Return a new RDD by first applying a function to all elements of this
* RDD, and then flattening the results.
*/
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.flatMap(cleanF))
}
成为大牛,必写的写法 ->
groupByKey适用于
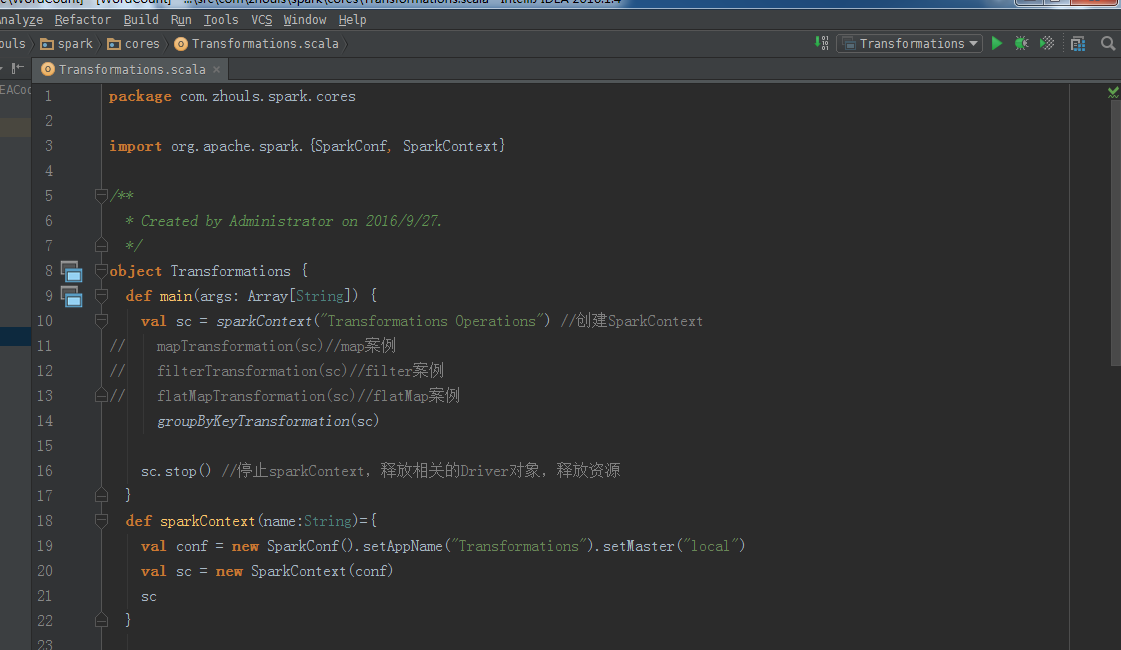
package com.zhouls.spark.cores
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by Administrator on 2016/9/27.
*/
object Transformations {
def main(args: Array[String]) {
val sc = sparkContext("Transformations Operations") //创建SparkContext
// mapTransformation(sc)//map案例
// filterTransformation(sc)//filter案例
// flatMapTransformation(sc)//flatMap案例
groupByKeyTransformation(sc)
sc.stop() //停止sparkContext,释放相关的Driver对象,释放资源
}
def sparkContext(name:String)={
val conf = new SparkConf().setAppName("Transformations").setMaster("local")
val sc = new SparkContext(conf)
sc
}
def mapTransformation(sc:SparkContext){
val nums = sc.parallelize(1 to 10) //根据集合创建RDD
val mapped = nums.map(item => 2 * item) //map适用于任何类型的元素且对其作用的集合中的每一个元素循环遍历并调用其作为参数的函数对每一个遍历的元素进行具体化处理
mapped.collect.foreach(println)//收集计算结果并通过foreach循环打印
}
def filterTransformation(sc:SparkContext){
val nums = sc.parallelize(1 to 20) //根据集合创建RDD
val filtered = nums.filter(item => item%2 == 0)//根据filter中作为参数的函数Boolean来判断符合条件的元素,并基于这些元素构成新的MapPartitionsRDD。
filtered.collect.foreach(println)//收集计算结果并通过foreach循环打印
}
def flatMapTransformation(sc:SparkContext){
val bigData = Array("Scala Spark","Java Hadoop","Java Tachyon")//实例化字符串类型的Array
val bigDataString = sc.parallelize(bigData)//创建以字符串为元素类型的MapPartitionsRDD
val words = bigDataString.flatMap(line => line.split(" "))//首先是通过传入的作为参数的函数来作用于RDD的每个字符串进行单词切分(是以集合的方式存在的),然后把切分后的结果合并成一个大的集合,是{Scala Spark Java Hadoop Java Tachyon}
words.collect.foreach(println)//收集计算结果并通过foreach循环打印
}
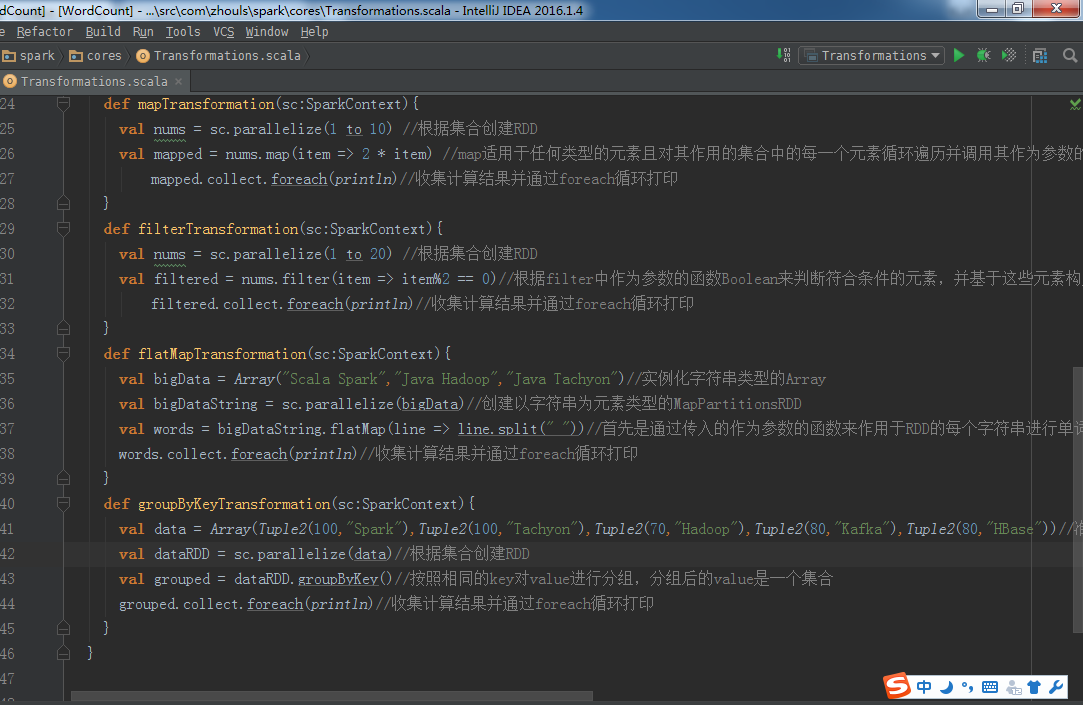
def groupByKeyTransformation(sc:SparkContext){
val data = Array(Tuple2(100,"Spark"),Tuple2(100,"Tachyon"),Tuple2(70,"Hadoop"),Tuple2(80,"Kafka"),Tuple2(80,"HBase"))
val dataRDD = sc.parallelize(data)
val grouped = dataRDD.groupByKey()
grouped.collect.foreach(println)//收集计算结果并通过foreach循环打印
}
}
groupByKey源码
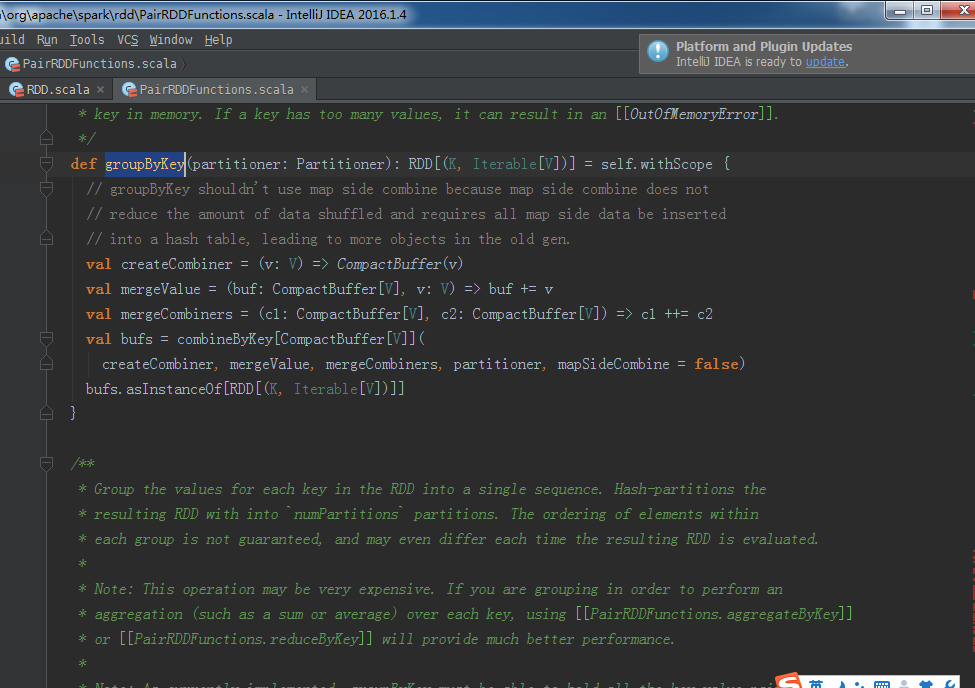
**
* Group the values for each key in the RDD into a single sequence. Allows controlling the
* partitioning of the resulting key-value pair RDD by passing a Partitioner.
* The ordering of elements within each group is not guaranteed, and may even differ
* each time the resulting RDD is evaluated.
*
* Note: This operation may be very expensive. If you are grouping in order to perform an
* aggregation (such as a sum or average) over each key, using [[PairRDDFunctions.aggregateByKey]]
* or [[PairRDDFunctions.reduceByKey]] will provide much better performance.
*
* Note: As currently implemented, groupByKey must be able to hold all the key-value pairs for any
* key in memory. If a key has too many values, it can result in an [[OutOfMemoryError]].
*/
def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])] = self.withScope {
// groupByKey shouldn't use map side combine because map side combine does not
// reduce the amount of data shuffled and requires all map side data be inserted
// into a hash table, leading to more objects in the old gen.
val createCombiner = (v: V) => CompactBuffer(v)
val mergeValue = (buf: CompactBuffer[V], v: V) => buf += v
val mergeCombiners = (c1: CompactBuffer[V], c2: CompactBuffer[V]) => c1 ++= c2
val bufs = combineByKey[CompactBuffer[V]](
createCombiner, mergeValue, mergeCombiners, partitioner, mapSideCombine = false)
bufs.asInstanceOf[RDD[(K, Iterable[V])]]
} /**
* Group the values for each key in the RDD into a single sequence. Hash-partitions the
* resulting RDD with into `numPartitions` partitions. The ordering of elements within
* each group is not guaranteed, and may even differ each time the resulting RDD is evaluated.
*
* Note: This operation may be very expensive. If you are grouping in order to perform an
* aggregation (such as a sum or average) over each key, using [[PairRDDFunctions.aggregateByKey]]
* or [[PairRDDFunctions.reduceByKey]] will provide much better performance.
*
* Note: As currently implemented, groupByKey must be able to hold all the key-value pairs for any
* key in memory. If a key has too many values, it can result in an [[OutOfMemoryError]].
*/
def groupByKey(numPartitions: Int): RDD[(K, Iterable[V])] = self.withScope {
groupByKey(new HashPartitioner(numPartitions))
}
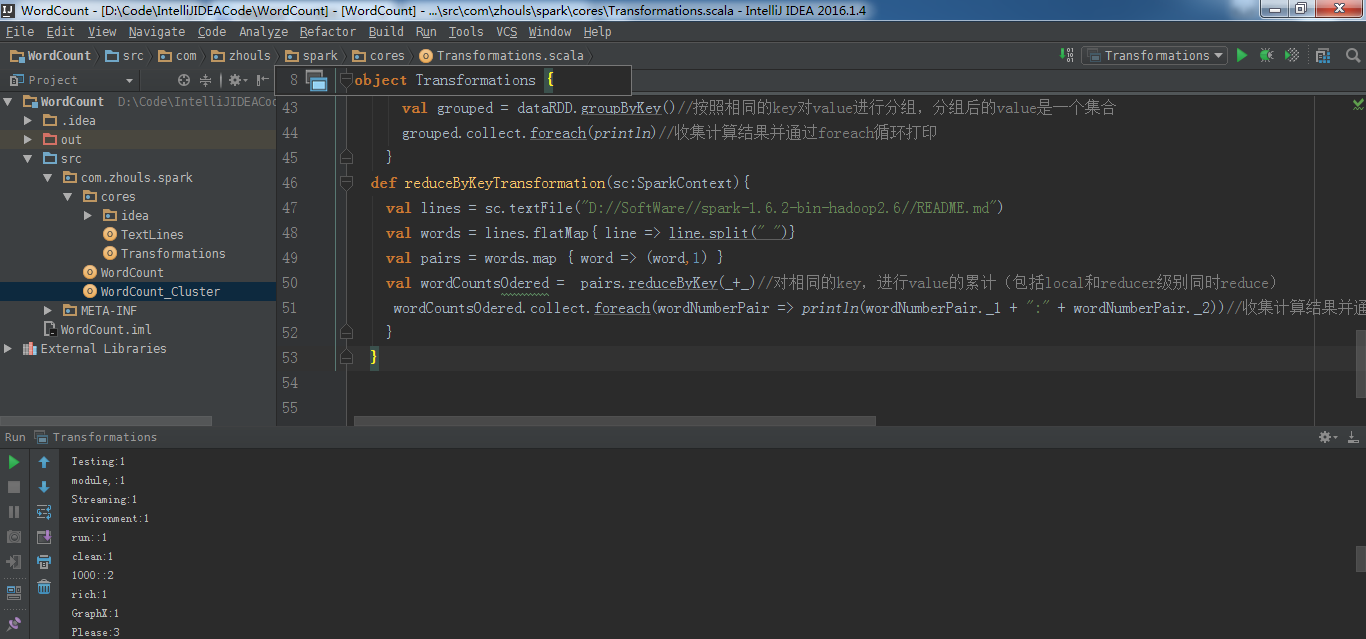
reduceByKey适用于
package com.zhouls.spark.cores
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by Administrator on 2016/9/27.
*/
object Transformations {
def main(args: Array[String]) {
val sc = sparkContext("Transformations Operations") //创建SparkContext
// mapTransformation(sc)//map案例
// filterTransformation(sc)//filter案例
// flatMapTransformation(sc)//flatMap案例
// groupByKeyTransformation(sc)//groupByKey案例
reduceByKeyTransformation(sc)//reduceByKey案例
sc.stop() //停止sparkContext,释放相关的Driver对象,释放资源
}
def sparkContext(name:String)={
val conf = new SparkConf().setAppName("Transformations").setMaster("local")
val sc = new SparkContext(conf)
sc
}
def mapTransformation(sc:SparkContext){
val nums = sc.parallelize(1 to 10) //根据集合创建RDD
val mapped = nums.map(item => 2 * item) //map适用于任何类型的元素且对其作用的集合中的每一个元素循环遍历并调用其作为参数的函数对每一个遍历的元素进行具体化处理
mapped.collect.foreach(println)//收集计算结果并通过foreach循环打印
}
def filterTransformation(sc:SparkContext){
val nums = sc.parallelize(1 to 20) //根据集合创建RDD
val filtered = nums.filter(item => item%2 == 0)//根据filter中作为参数的函数Boolean来判断符合条件的元素,并基于这些元素构成新的MapPartitionsRDD。
filtered.collect.foreach(println)//收集计算结果并通过foreach循环打印
}
def flatMapTransformation(sc:SparkContext){
val bigData = Array("Scala Spark","Java Hadoop","Java Tachyon")//实例化字符串类型的Array
val bigDataString = sc.parallelize(bigData)//创建以字符串为元素类型的MapPartitionsRDD
val words = bigDataString.flatMap(line => line.split(" "))//首先是通过传入的作为参数的函数来作用于RDD的每个字符串进行单词切分(是以集合的方式存在的),然后把切分后的结果合并成一个大的集合,是{Scala Spark Java Hadoop Java Tachyon}
words.collect.foreach(println)//收集计算结果并通过foreach循环打印
}
def groupByKeyTransformation(sc:SparkContext){
val data = Array(Tuple2(100,"Spark"),Tuple2(100,"Tachyon"),Tuple2(70,"Hadoop"),Tuple2(80,"Kafka"),Tuple2(80,"HBase"))//准备数据
val dataRDD = sc.parallelize(data)//根据集合创建RDD
val grouped = dataRDD.groupByKey()//按照相同的key对value进行分组,分组后的value是一个集合
grouped.collect.foreach(println)//收集计算结果并通过foreach循环打印
}
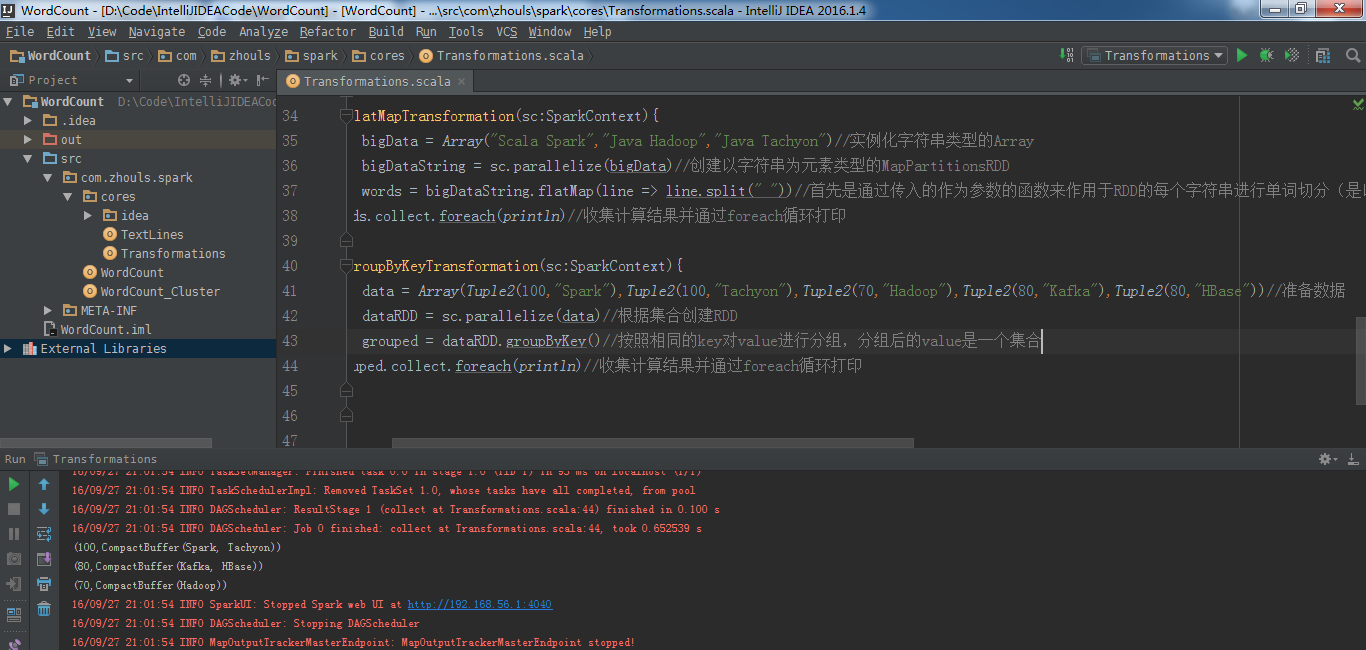
def reduceByKeyTransformation(sc:SparkContext){
val lines = sc.textFile("D://SoftWare//spark-1.6.2-bin-hadoop2.6//README.md")
val words = lines.flatMap{ line => line.split(" ")}
val pairs = words.map { word => (word,1) }
val wordCountsOdered = pairs.reduceByKey(_+_)//对相同的key,进行value的累计(包括local和reducer级别同时reduce)
wordCountsOdered.collect.foreach(wordNumberPair => println(wordNumberPair._1 + ":" + wordNumberPair._2))//收集计算结果并通过foreach循环打印
}
}
reduceByKey源码
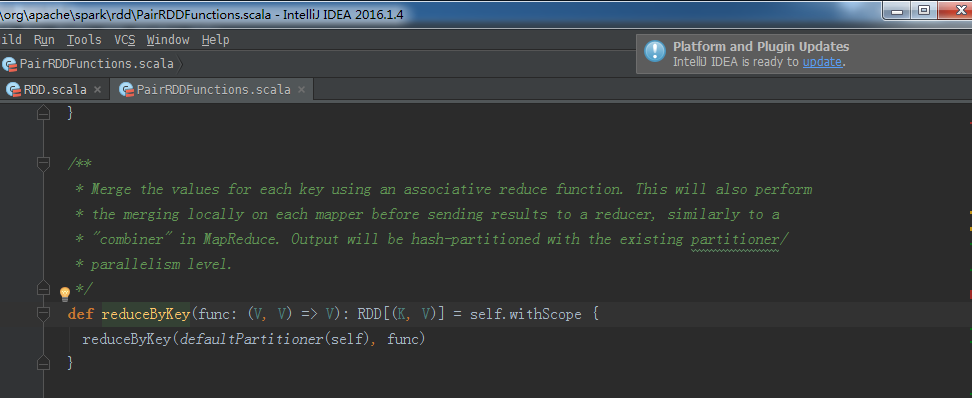
/**
* Merge the values for each key using an associative reduce function. This will also perform
* the merging locally on each mapper before sending results to a reducer, similarly to a
* "combiner" in MapReduce. Output will be hash-partitioned with the existing partitioner/
* parallelism level.
*/
def reduceByKey(func: (V, V) => V): RDD[(K, V)] = self.withScope {
reduceByKey(defaultPartitioner(self), func)
}
join适用于
package com.zhouls.spark.cores
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by Administrator on 2016/9/27.
*/
object Transformations {
def main(args: Array[String]) {
val sc = sparkContext("Transformations Operations") //创建SparkContext
// mapTransformation(sc)//map案例
// filterTransformation(sc)//filter案例
// flatMapTransformation(sc)//flatMap案例
// groupByKeyTransformation(sc)//groupByKey案例
// reduceByKeyTransformation(sc)//reduceByKey案例
joinTransformation(sc)//join案例
sc.stop() //停止sparkContext,释放相关的Driver对象,释放资源
}
def sparkContext(name:String)={
val conf = new SparkConf().setAppName("Transformations").setMaster("local")
val sc = new SparkContext(conf)
sc
}
def mapTransformation(sc:SparkContext){
val nums = sc.parallelize(1 to 10) //根据集合创建RDD
val mapped = nums.map(item => 2 * item) //map适用于任何类型的元素且对其作用的集合中的每一个元素循环遍历并调用其作为参数的函数对每一个遍历的元素进行具体化处理
mapped.collect.foreach(println)//收集计算结果并通过foreach循环打印
}
def filterTransformation(sc:SparkContext){
val nums = sc.parallelize(1 to 20) //根据集合创建RDD
val filtered = nums.filter(item => item%2 == 0)//根据filter中作为参数的函数Boolean来判断符合条件的元素,并基于这些元素构成新的MapPartitionsRDD。
filtered.collect.foreach(println)//收集计算结果并通过foreach循环打印
}
def flatMapTransformation(sc:SparkContext){
val bigData = Array("Scala Spark","Java Hadoop","Java Tachyon")//实例化字符串类型的Array
val bigDataString = sc.parallelize(bigData)//创建以字符串为元素类型的MapPartitionsRDD
val words = bigDataString.flatMap(line => line.split(" "))//首先是通过传入的作为参数的函数来作用于RDD的每个字符串进行单词切分(是以集合的方式存在的),然后把切分后的结果合并成一个大的集合,是{Scala Spark Java Hadoop Java Tachyon}
words.collect.foreach(println)//收集计算结果并通过foreach循环打印
}
def groupByKeyTransformation(sc:SparkContext){
val data = Array(Tuple2(100,"Spark"),Tuple2(100,"Tachyon"),Tuple2(70,"Hadoop"),Tuple2(80,"Kafka"),Tuple2(80,"HBase"))//准备数据
val dataRDD = sc.parallelize(data)//根据集合创建RDD
val grouped = dataRDD.groupByKey()//按照相同的key对value进行分组,分组后的value是一个集合
grouped.collect.foreach(println)//收集计算结果并通过foreach循环打印
}
def reduceByKeyTransformation(sc:SparkContext){
val lines = sc.textFile("D://SoftWare//spark-1.6.2-bin-hadoop2.6//README.md")
val words = lines.flatMap{ line => line.split(" ")}
val pairs = words.map { word => (word,1) }
val wordCountsOdered = pairs.reduceByKey(_+_)//对相同的key,进行value的累计(包括local和reducer级别同时reduce)
wordCountsOdered.collect.foreach(wordNumberPair => println(wordNumberPair._1 + ":" + wordNumberPair._2))//收集计算结果并通过foreach循环打印
}
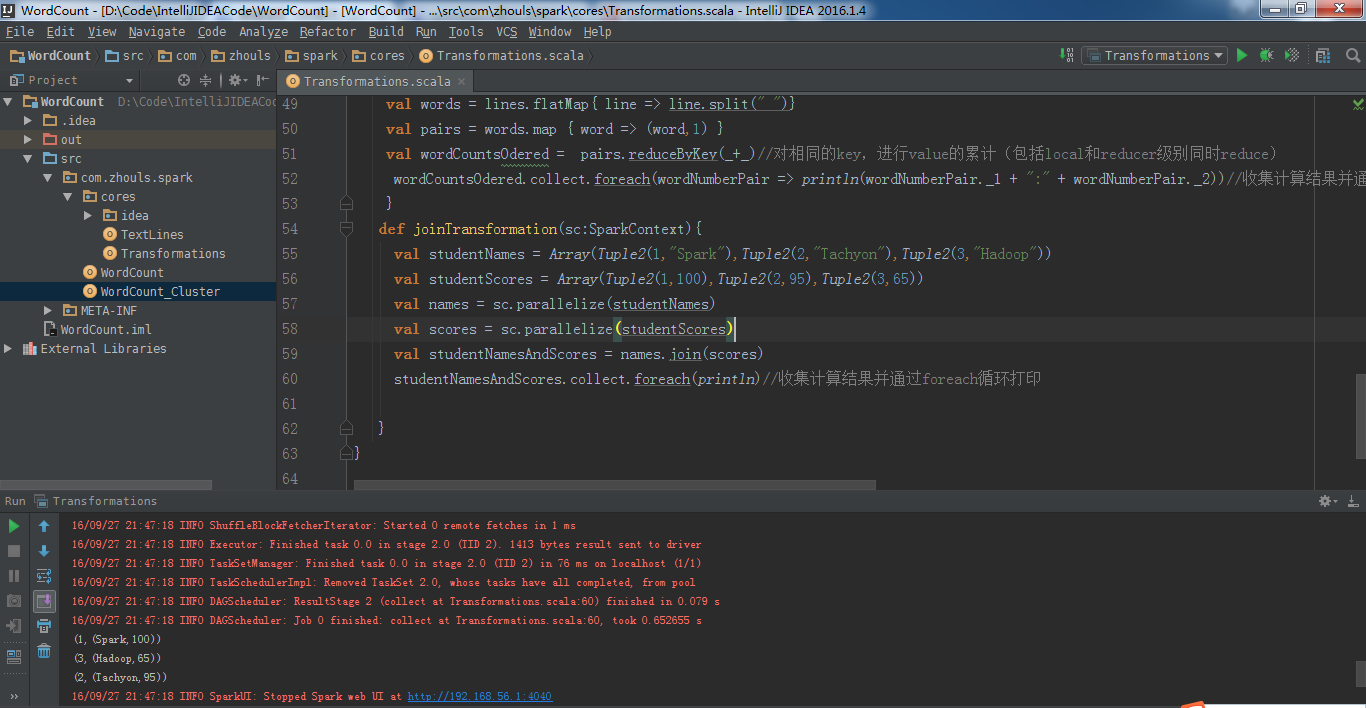
def joinTransformation(sc:SparkContext){
val studentNames = Array(Tuple2(1,"Spark"),Tuple2(2,"Tachyon"),Tuple2(3,"Hadoop"))
val studentScores = Array(Tuple2(1,100),Tuple2(2,95),Tuple2(3,65))
val names = sc.parallelize(studentNames)
val scores = sc.parallelize(studentScores)
val studentNamesAndScores = names.join(scores)
studentNamesAndScores.collect.foreach(println)//收集计算结果并通过foreach循环打印
}
}
join源码
/**
* Cartesian join with another [[DataFrame]].
*
* Note that cartesian joins are very expensive without an extra filter that can be pushed down.
*
* @param right Right side of the join operation.
* @group dfops
* @since 1.3.0
*/
def join(right: DataFrame): DataFrame = {
Join(logicalPlan, right.logicalPlan, joinType = Inner, None)
} /**
* Inner equi-join with another [[DataFrame]] using the given column.
*
* Different from other join functions, the join column will only appear once in the output,
* i.e. similar to SQL's `JOIN USING` syntax.
*
* {{{
* // Joining df1 and df2 using the column "user_id"
* df1.join(df2, "user_id")
* }}}
*
* Note that if you perform a self-join using this function without aliasing the input
* [[DataFrame]]s, you will NOT be able to reference any columns after the join, since
* there is no way to disambiguate which side of the join you would like to reference.
*
* @param right Right side of the join operation.
* @param usingColumn Name of the column to join on. This column must exist on both sides.
* @group dfops
* @since 1.4.0
*/
def join(right: DataFrame, usingColumn: String): DataFrame = {
join(right, Seq(usingColumn))
} /**
* Inner equi-join with another [[DataFrame]] using the given columns.
*
* Different from other join functions, the join columns will only appear once in the output,
* i.e. similar to SQL's `JOIN USING` syntax.
*
* {{{
* // Joining df1 and df2 using the columns "user_id" and "user_name"
* df1.join(df2, Seq("user_id", "user_name"))
* }}}
*
* Note that if you perform a self-join using this function without aliasing the input
* [[DataFrame]]s, you will NOT be able to reference any columns after the join, since
* there is no way to disambiguate which side of the join you would like to reference.
*
* @param right Right side of the join operation.
* @param usingColumns Names of the columns to join on. This columns must exist on both sides.
* @group dfops
* @since 1.4.0
*/
def join(right: DataFrame, usingColumns: Seq[String]): DataFrame = {
// Analyze the self join. The assumption is that the analyzer will disambiguate left vs right
// by creating a new instance for one of the branch.
val joined = sqlContext.executePlan(
Join(logicalPlan, right.logicalPlan, joinType = Inner, None)).analyzed.asInstanceOf[Join] // Project only one of the join columns.
val joinedCols = usingColumns.map(col => joined.right.resolve(col))
val condition = usingColumns.map { col =>
catalyst.expressions.EqualTo(joined.left.resolve(col), joined.right.resolve(col))
}.reduceLeftOption[catalyst.expressions.BinaryExpression] { (cond, eqTo) =>
catalyst.expressions.And(cond, eqTo)
} Project(
joined.output.filterNot(joinedCols.contains(_)),
Join(
joined.left,
joined.right,
joinType = Inner,
condition)
)
} /**
* Inner join with another [[DataFrame]], using the given join expression.
*
* {{{
* // The following two are equivalent:
* df1.join(df2, $"df1Key" === $"df2Key")
* df1.join(df2).where($"df1Key" === $"df2Key")
* }}}
* @group dfops
* @since 1.3.0
*/
def join(right: DataFrame, joinExprs: Column): DataFrame = join(right, joinExprs, "inner") /**
* Join with another [[DataFrame]], using the given join expression. The following performs
* a full outer join between `df1` and `df2`.
*
* {{{
* // Scala:
* import org.apache.spark.sql.functions._
* df1.join(df2, $"df1Key" === $"df2Key", "outer")
*
* // Java:
* import static org.apache.spark.sql.functions.*;
* df1.join(df2, col("df1Key").equalTo(col("df2Key")), "outer");
* }}}
*
* @param right Right side of the join.
* @param joinExprs Join expression.
* @param joinType One of: `inner`, `outer`, `left_outer`, `right_outer`, `leftsemi`.
* @group dfops
* @since 1.3.0
*/
def join(right: DataFrame, joinExprs: Column, joinType: String): DataFrame = {
// Note that in this function, we introduce a hack in the case of self-join to automatically
// resolve ambiguous join conditions into ones that might make sense [SPARK-6231].
// Consider this case: df.join(df, df("key") === df("key"))
// Since df("key") === df("key") is a trivially true condition, this actually becomes a
// cartesian join. However, most likely users expect to perform a self join using "key".
// With that assumption, this hack turns the trivially true condition into equality on join
// keys that are resolved to both sides. // Trigger analysis so in the case of self-join, the analyzer will clone the plan.
// After the cloning, left and right side will have distinct expression ids.
val plan = Join(logicalPlan, right.logicalPlan, JoinType(joinType), Some(joinExprs.expr))
.queryExecution.analyzed.asInstanceOf[Join] // If auto self join alias is disabled, return the plan.
if (!sqlContext.conf.dataFrameSelfJoinAutoResolveAmbiguity) {
return plan
} // If left/right have no output set intersection, return the plan.
val lanalyzed = this.logicalPlan.queryExecution.analyzed
val ranalyzed = right.logicalPlan.queryExecution.analyzed
if (lanalyzed.outputSet.intersect(ranalyzed.outputSet).isEmpty) {
return plan
} // Otherwise, find the trivially true predicates and automatically resolves them to both sides.
// By the time we get here, since we have already run analysis, all attributes should've been
// resolved and become AttributeReference.
val cond = plan.condition.map { _.transform {
case catalyst.expressions.EqualTo(a: AttributeReference, b: AttributeReference)
if a.sameRef(b) =>
catalyst.expressions.EqualTo(plan.left.resolve(a.name), plan.right.resolve(b.name))
}}
plan.copy(condition = cond)
}
cogroup的scala版,适用于

package com.zhouls.spark.cores
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by Administrator on 2016/9/27.
*/
object Transformations {
def main(args: Array[String]) {
val sc = sparkContext("Transformations Operations") //创建SparkContext
// mapTransformation(sc)//map案例
// filterTransformation(sc)//filter案例
// flatMapTransformation(sc)//flatMap案例
// groupByKeyTransformation(sc)//groupByKey案例
// reduceByKeyTransformation(sc)//reduceByKey案例
// joinTransformation(sc)//join案例
cogroupTransformation(sc)//cogroup案例
sc.stop() //停止sparkContext,释放相关的Driver对象,释放资源
}
def sparkContext(name:String)={
val conf = new SparkConf().setAppName("Transformations").setMaster("local")
val sc = new SparkContext(conf)
sc
}
def mapTransformation(sc:SparkContext){
val nums = sc.parallelize(1 to 10) //根据集合创建RDD
val mapped = nums.map(item => 2 * item) //map适用于任何类型的元素且对其作用的集合中的每一个元素循环遍历并调用其作为参数的函数对每一个遍历的元素进行具体化处理
mapped.collect.foreach(println)//收集计算结果并通过foreach循环打印
}
def filterTransformation(sc:SparkContext){
val nums = sc.parallelize(1 to 20) //根据集合创建RDD
val filtered = nums.filter(item => item%2 == 0)//根据filter中作为参数的函数Boolean来判断符合条件的元素,并基于这些元素构成新的MapPartitionsRDD。
filtered.collect.foreach(println)//收集计算结果并通过foreach循环打印
}
def flatMapTransformation(sc:SparkContext){
val bigData = Array("Scala Spark","Java Hadoop","Java Tachyon")//实例化字符串类型的Array
val bigDataString = sc.parallelize(bigData)//创建以字符串为元素类型的MapPartitionsRDD
val words = bigDataString.flatMap(line => line.split(" "))//首先是通过传入的作为参数的函数来作用于RDD的每个字符串进行单词切分(是以集合的方式存在的),然后把切分后的结果合并成一个大的集合,是{Scala Spark Java Hadoop Java Tachyon}
words.collect.foreach(println)//收集计算结果并通过foreach循环打印
}
def groupByKeyTransformation(sc:SparkContext){
val data = Array(Tuple2(100,"Spark"),Tuple2(100,"Tachyon"),Tuple2(70,"Hadoop"),Tuple2(80,"Kafka"),Tuple2(80,"HBase"))//准备数据
val dataRDD = sc.parallelize(data)//根据集合创建RDD
val grouped = dataRDD.groupByKey()//按照相同的key对value进行分组,分组后的value是一个集合
grouped.collect.foreach(println)//收集计算结果并通过foreach循环打印
}
def reduceByKeyTransformation(sc:SparkContext){
val lines = sc.textFile("D://SoftWare//spark-1.6.2-bin-hadoop2.6//README.md")
val words = lines.flatMap{ line => line.split(" ")}
val pairs = words.map { word => (word,1) }
val wordCountsOdered = pairs.reduceByKey(_+_)//对相同的key,进行value的累计(包括local和reducer级别同时reduce)
wordCountsOdered.collect.foreach(wordNumberPair => println(wordNumberPair._1 + ":" + wordNumberPair._2))//收集计算结果并通过foreach循环打印
}
def joinTransformation(sc:SparkContext){
val studentNames = Array(Tuple2(1,"Spark"),Tuple2(2,"Tachyon"),Tuple2(3,"Hadoop"))
val studentScores = Array(Tuple2(1,100),Tuple2(2,95),Tuple2(3,65))
val names = sc.parallelize(studentNames)
val scores = sc.parallelize(studentScores)
val studentNamesAndScores = names.join(scores)
studentNamesAndScores.collect.foreach(println)//收集计算结果并通过foreach循环打印
}
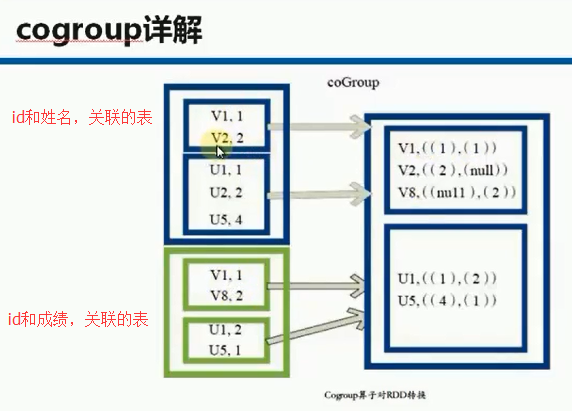
def cogroupTransformation(sc:SparkContext){
val namesLists = Array(Tuple2(1,"xiaoming"),Tuple2(2,"xiaozhou"),Tuple2(3,"xiaoliu"))
val scoresLists = Array(Tuple2(1,100),Tuple2(2,95),Tuple2(3,85),Tuple2(1,75),Tuple2(2,65),Tuple2(3,55))
val names = sc.parallelize(namesLists)
val scores = sc.parallelize(scoresLists)
val namesListsAndScores = names.cogroup(scores)
namesListsAndScores.collect.foreach(println)//收集计算结果并通过foreach循环打印
}
}
cogroup源码
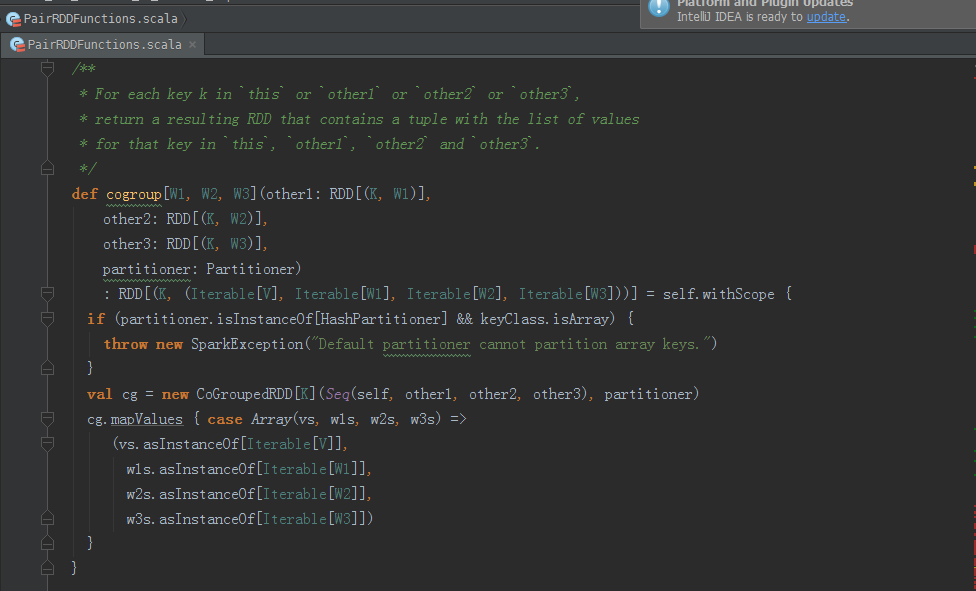
/**
* For each key k in `this` or `other1` or `other2` or `other3`,
* return a resulting RDD that contains a tuple with the list of values
* for that key in `this`, `other1`, `other2` and `other3`.
*/
def cogroup[W1, W2, W3](other1: RDD[(K, W1)],
other2: RDD[(K, W2)],
other3: RDD[(K, W3)],
partitioner: Partitioner)
: RDD[(K, (Iterable[V], Iterable[W1], Iterable[W2], Iterable[W3]))] = self.withScope {
if (partitioner.isInstanceOf[HashPartitioner] && keyClass.isArray) {
throw new SparkException("Default partitioner cannot partition array keys.")
}
val cg = new CoGroupedRDD[K](Seq(self, other1, other2, other3), partitioner)
cg.mapValues { case Array(vs, w1s, w2s, w3s) =>
(vs.asInstanceOf[Iterable[V]],
w1s.asInstanceOf[Iterable[W1]],
w2s.asInstanceOf[Iterable[W2]],
w3s.asInstanceOf[Iterable[W3]])
}
} /**
* For each key k in `this` or `other`, return a resulting RDD that contains a tuple with the
* list of values for that key in `this` as well as `other`.
*/
def cogroup[W](other: RDD[(K, W)], partitioner: Partitioner)
: RDD[(K, (Iterable[V], Iterable[W]))] = self.withScope {
if (partitioner.isInstanceOf[HashPartitioner] && keyClass.isArray) {
throw new SparkException("Default partitioner cannot partition array keys.")
}
val cg = new CoGroupedRDD[K](Seq(self, other), partitioner)
cg.mapValues { case Array(vs, w1s) =>
(vs.asInstanceOf[Iterable[V]], w1s.asInstanceOf[Iterable[W]])
}
} /**
* For each key k in `this` or `other1` or `other2`, return a resulting RDD that contains a
* tuple with the list of values for that key in `this`, `other1` and `other2`.
*/
def cogroup[W1, W2](other1: RDD[(K, W1)], other2: RDD[(K, W2)], partitioner: Partitioner)
: RDD[(K, (Iterable[V], Iterable[W1], Iterable[W2]))] = self.withScope {
if (partitioner.isInstanceOf[HashPartitioner] && keyClass.isArray) {
throw new SparkException("Default partitioner cannot partition array keys.")
}
val cg = new CoGroupedRDD[K](Seq(self, other1, other2), partitioner)
cg.mapValues { case Array(vs, w1s, w2s) =>
(vs.asInstanceOf[Iterable[V]],
w1s.asInstanceOf[Iterable[W1]],
w2s.asInstanceOf[Iterable[W2]])
}
} /**
* For each key k in `this` or `other1` or `other2` or `other3`,
* return a resulting RDD that contains a tuple with the list of values
* for that key in `this`, `other1`, `other2` and `other3`.
*/
def cogroup[W1, W2, W3](other1: RDD[(K, W1)], other2: RDD[(K, W2)], other3: RDD[(K, W3)])
: RDD[(K, (Iterable[V], Iterable[W1], Iterable[W2], Iterable[W3]))] = self.withScope {
cogroup(other1, other2, other3, defaultPartitioner(self, other1, other2, other3))
} /**
* For each key k in `this` or `other`, return a resulting RDD that contains a tuple with the
* list of values for that key in `this` as well as `other`.
*/
def cogroup[W](other: RDD[(K, W)]): RDD[(K, (Iterable[V], Iterable[W]))] = self.withScope {
cogroup(other, defaultPartitioner(self, other))
} /**
* For each key k in `this` or `other1` or `other2`, return a resulting RDD that contains a
* tuple with the list of values for that key in `this`, `other1` and `other2`.
*/
def cogroup[W1, W2](other1: RDD[(K, W1)], other2: RDD[(K, W2)])
: RDD[(K, (Iterable[V], Iterable[W1], Iterable[W2]))] = self.withScope {
cogroup(other1, other2, defaultPartitioner(self, other1, other2))
} /**
* For each key k in `this` or `other`, return a resulting RDD that contains a tuple with the
* list of values for that key in `this` as well as `other`.
*/
def cogroup[W](
other: RDD[(K, W)],
numPartitions: Int): RDD[(K, (Iterable[V], Iterable[W]))] = self.withScope {
cogroup(other, new HashPartitioner(numPartitions))
} /**
* For each key k in `this` or `other1` or `other2`, return a resulting RDD that contains a
* tuple with the list of values for that key in `this`, `other1` and `other2`.
*/
def cogroup[W1, W2](other1: RDD[(K, W1)], other2: RDD[(K, W2)], numPartitions: Int)
: RDD[(K, (Iterable[V], Iterable[W1], Iterable[W2]))] = self.withScope {
cogroup(other1, other2, new HashPartitioner(numPartitions))
} /**
* For each key k in `this` or `other1` or `other2` or `other3`,
* return a resulting RDD that contains a tuple with the list of values
* for that key in `this`, `other1`, `other2` and `other3`.
*/
def cogroup[W1, W2, W3](other1: RDD[(K, W1)],
other2: RDD[(K, W2)],
other3: RDD[(K, W3)],
numPartitions: Int)
: RDD[(K, (Iterable[V], Iterable[W1], Iterable[W2], Iterable[W3]))] = self.withScope {
cogroup(other1, other2, other3, new HashPartitioner(numPartitions))
}
cogroup的java版,适用于,转自
http://blog.csdn.net/kimyoungvon/article/details/51417910
另推荐一篇好的博客,https://www.iteblog.com/archives/1280
感谢!
Spark RDD/Core 编程 API入门系列 之rdd案例(map、filter、flatMap、groupByKey、reduceByKey、join、cogroupy等)(四)的更多相关文章
- Spark RDD/Core 编程 API入门系列 之rdd实战(rdd基本操作实战及transformation和action流程图)(源码)(三)
本博文的主要内容是: 1.rdd基本操作实战 2.transformation和action流程图 3.典型的transformation和action RDD有3种操作: 1. Trandform ...
- Spark RDD/Core 编程 API入门系列之简单移动互联网数据(五)
通过对移动互联网数据的分析,了解移动终端在互联网上的行为以及各个应用在互联网上的发展情况等信息. 具体包括对不同的应用使用情况的统计.移动互联网上的日常活跃用户(DAU)和月活跃用户(MAU)的统计, ...
- Spark RDD/Core 编程 API入门系列之map、filter、textFile、cache、对Job输出结果进行升和降序、union、groupByKey、join、reduce、lookup(一)
1.以本地模式实战map和filter 2.以集群模式实战textFile和cache 3.对Job输出结果进行升和降序 4.union 5.groupByKey 6.join 7.reduce 8. ...
- Spark RDD/Core 编程 API入门系列之动手实战和调试Spark文件操作、动手实战操作搜狗日志文件、搜狗日志文件深入实战(二)
1.动手实战和调试Spark文件操作 这里,我以指定executor-memory参数的方式,启动spark-shell. 启动hadoop集群 spark@SparkSingleNode:/usr/ ...
- Spark SQL 编程API入门系列之SparkSQL的依赖
不多说,直接上干货! 不带Hive支持 <dependency> <groupId>org.apache.spark</groupId> <artifactI ...
- Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
不多说,直接上代码. Hadoop MapReduce编程 API入门系列之小文件合并(二十九) 生成的结果,作为输入源. 代码 package zhouls.bigdata.myMapReduce. ...
- HBase编程 API入门系列之create(管理端而言)(8)
大家,若是看过我前期的这篇博客的话,则 HBase编程 API入门系列之put(客户端而言)(1) 就知道,在这篇博文里,我是在HBase Shell里创建HBase表的. 这里,我带领大家,学习更高 ...
- HBase编程 API入门系列之delete(客户端而言)(3)
心得,写在前面的话,也许,中间会要多次执行,连接超时,多试试就好了. 前面的基础,如下 HBase编程 API入门系列之put(客户端而言)(1) HBase编程 API入门系列之get(客户端而言) ...
- HBase编程 API入门系列之get(客户端而言)(2)
心得,写在前面的话,也许,中间会要多次执行,连接超时,多试试就好了. 前面是基础,如下 HBase编程 API入门系列之put(客户端而言)(1) package zhouls.bigdata.Hba ...
随机推荐
- React组件一
<div id='test'></div> <script type='text/babel'> var Zu=React.createClass({ return ...
- js实现幻灯片播放图片示例代码
幻灯片播放图片的效果想必大家都有见到过吧,下面有个不错的示例,感兴趣的朋友可以参考下 复制代码代码如下: <select id="img_date" style=" ...
- MVC中Area的使用
1.Area是什么? MVC 2 中引进了区域的概念,它允许将模型,视图和控制器分成单独的功能节点,换句话说,可以在大型复杂的网站中建立几个区域(模块),每一个区域都有Model,View,Contr ...
- html5音频和视频相关属性和方法
方法 方法 描述 addTextTrack() 为音视频加入一个新的文本轨迹 canPlayType() 检查指定的音视频格式是否得到支持 load() 重新加载音视频标签 play() 播放音视频 ...
- 2014年度辛星html教程夏季版第一节
从今天起开始在博客园开启自己的html教程啦,先从第一节开始把,首先推荐一个网站,就是http:/www.w3cschool.cc,这是一个公开的教学网站,但是它有一个问题,那就是虽然很全面,但是不是 ...
- HTML5+CSS3鼠标悬停图片特效
点击预览效果 下载该特效: HTML5+CSS3鼠标悬停图片特效.zip 特效说明: 一款HTML5+CSS3鼠标悬停图片事件网页特效,集合了最流行鼠标悬停图片文字.图片动画移动 ...
- Django 数据库查询优化
Django数据层提供各种途径优化数据的访问,一个项目大量优化工作一般是放在后期来做,早期的优化是“万恶之源”,这是前人总结的经验,不无道理.如果事先理解Django的优化技巧,开发过程中稍稍留意,后 ...
- FZU 1753
题目的思路还是很简单的,找出这些组合数中最大的公约数: 其中C(n,k)=n ! /k!/(n-k)! 所以枚举每个素因数,用(n!)的减去(k!)和(n-k)!的就行了... 最后取每组的最小值 # ...
- Emily姨妈家的猫
按书上的样例,慢慢理解. 其实,JAVASCRIPT也应该可以写出正规点的,封装性好的代码. <html> <body> <script type="text/ ...
- poi 操作excel
poi操作 创建一个excel关联对象HSSFWorkbook: HSSFWorkbook book = new HSSFWorkbook(); 创建一个sheet: HSSFSheet st = b ...