Spark RDD/Core 编程 API入门系列之map、filter、textFile、cache、对Job输出结果进行升和降序、union、groupByKey、join、reduce、lookup(一)
1、以本地模式实战map和filter
2、以集群模式实战textFile和cache
3、对Job输出结果进行升和降序
4、union
5、groupByKey
6、join
7、reduce
8、lookup
1、以本地模式实战map和filter
以local的方式,运行spark-shell。
spark@SparkSingleNode:~$ cd /usr/local/spark/spark-1.5.2-bin-hadoop2.6/bin
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6/bin$ pwd
/usr/local/spark/spark-1.5.2-bin-hadoop2.6/bin
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6/bin$ ./spark-shell


从集合中创建RDD,spark中主要提供了两种函数:parallelize和makeRDD,
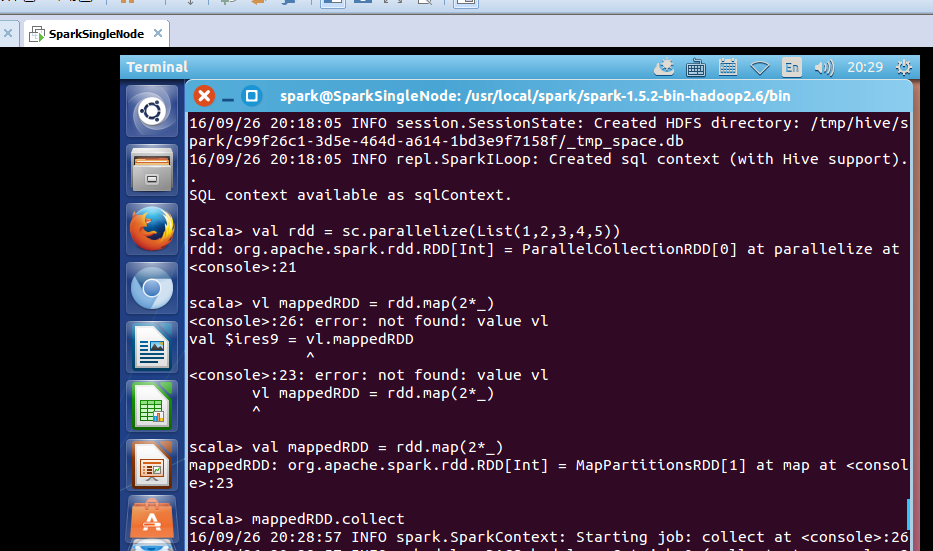
scala> val rdd = sc.parallelize(List(1,2,3,4,5))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:21
scala> val mappedRDD = rdd.map(2*_)
mappedRDD: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[1] at map at <console>:23
scala> mappedRDD.collect
得到
res0: Array[Int] = Array(2, 4, 6, 8, 10)
scala>

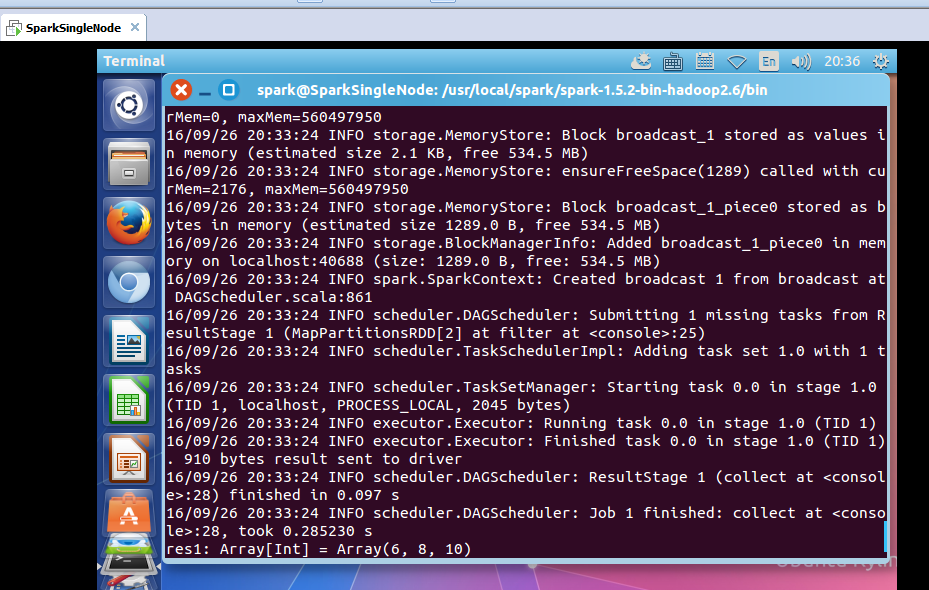
scala> val filteredRDD = mappedRDD.filter(_ > 4)
16/09/26 20:32:29 INFO storage.BlockManagerInfo: Removed broadcast_0_piece0 on localhost:40688 in memory (size: 1218.0 B, free: 534.5 MB)
16/09/26 20:32:30 INFO spark.ContextCleaner: Cleaned accumulator 1
filteredRDD: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[2] at filter at <console>:25
scala> filteredRDD.collect

注意,一般,生产环境和正宗的写法是。
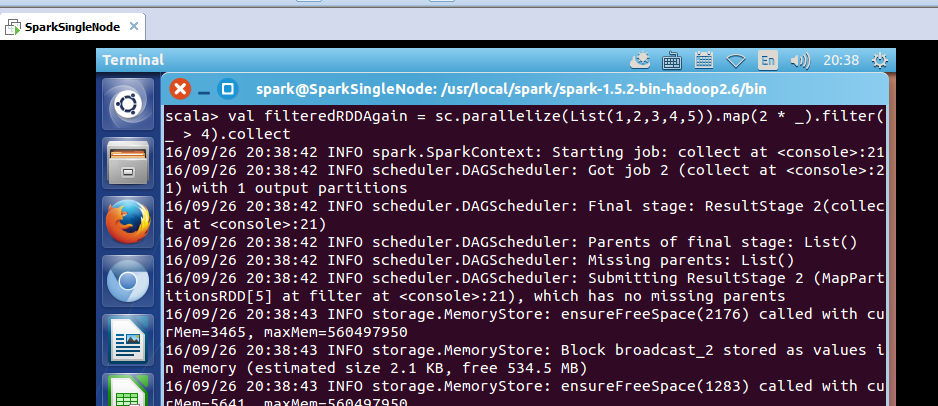
scala> val filteredRDDAgain = sc.parallelize(List(1,2,3,4,5)).map(2 * _).filter(_ > 4).collect



2、以集群模式实战textFile和cache
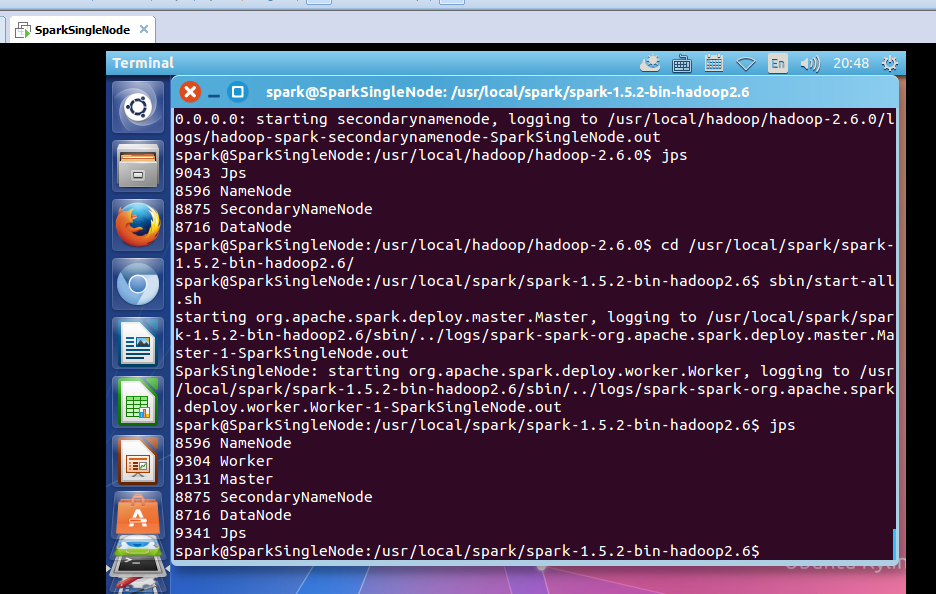
启动hadoop集群
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0$ jps
8457 Jps
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0$ sbin/start-dfs.sh

启动spark集群
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6$ sbin/start-all.sh
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6/bin$ ./spark-shell --master spark://SparkSingleNode:7077


读取该文件
scala> val rdd = sc.textFile("/README.md")
使用count统计一下该文件的行数
scala> rdd.count
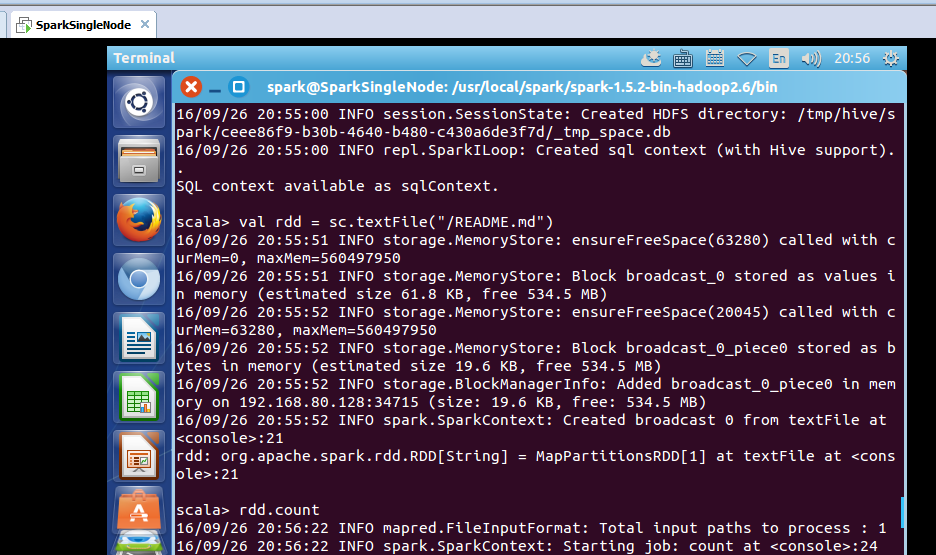
took 7.018386 s
res0: Long = 98
花了时间7.018386 s
通过观察RDD.scala源代码即可知道cache和persist的区别: def persist(newLevel: StorageLevel): this.type = {
if (storageLevel != StorageLevel.NONE && newLevel != storageLevel) {
throw new UnsupportedOperationException( "Cannot change storage level of an RDD after it was already assigned a level")
}
sc.persistRDD(this)
sc.cleaner.foreach(_.registerRDDForCleanup(this))
storageLevel = newLevel
this
}
/** Persist this RDD with the default storage level (`MEMORY_ONLY`). */
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY) /** Persist this RDD with the default storage level (`MEMORY_ONLY`). */
def cache(): this.type = persist() 可知:
1)RDD的cache()方法其实调用的就是persist方法,缓存策略均为MEMORY_ONLY;
2)可以通过persist方法手工设定StorageLevel来满足工程需要的存储级别;
3)cache或者persist并不是action;
附:cache和persist都可以用unpersist来取消
进行缓存
scala> rdd.cache
res1: rdd.type = MapPartitionsRDD[1] at textFile at <console>:21
执行count,使得缓存生效
scala> rdd.count


took 2.055063 s
res2: Long = 98
花了时间 2.055063 s
再执行,count


took 0.583177 s
res3: Long = 98
花了时间 0.583177 s
总结,我们直接基于cache缓存后的数据,计算所消耗时间大大减少。
正在进行中的spark-shell

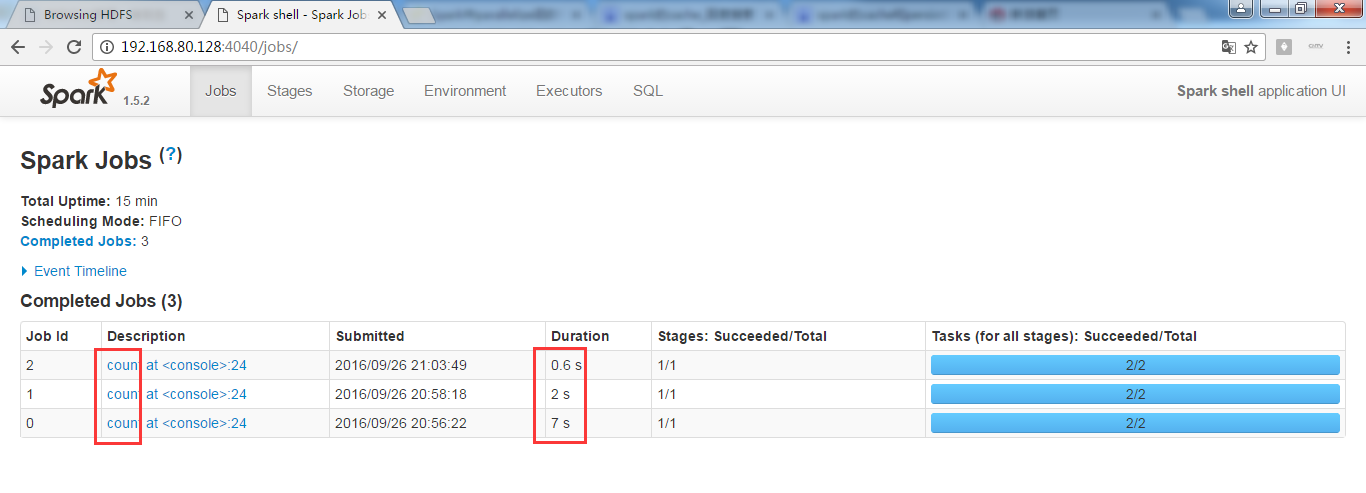



接着,对上面的RDD,进行wordcount操作
scala> val wordcount = rdd.flatMap(_.split(' ')).map((_,1)).reduceByKey(_+_)
wordcount: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[4] at reduceByKey at <console>:23
scala> wordcount.collect

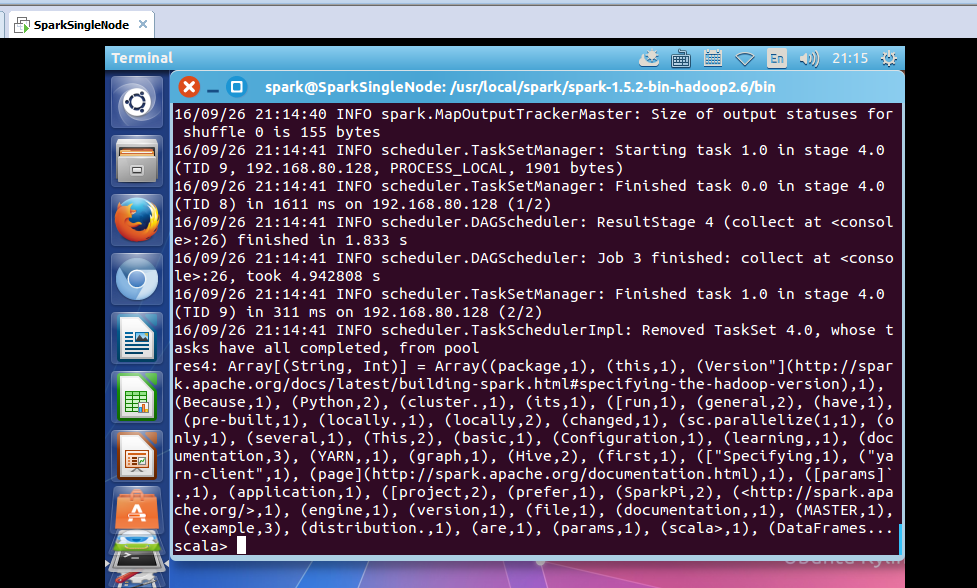
通过saveAsTextFile把数据保存起来
res4: Array[(String, Int)] = Array((package,1), (this,1), (Version"](http://spark.apache.org/docs/latest/building-spark.html#specifying-the-hadoop-version),1), (Because,1), (Python,2), (cluster.,1), (its,1), ([run,1), (general,2), (have,1), (pre-built,1), (locally.,1), (locally,2), (changed,1), (sc.parallelize(1,1), (only,1), (several,1), (This,2), (basic,1), (Configuration,1), (learning,,1), (documentation,3), (YARN,,1), (graph,1), (Hive,2), (first,1), (["Specifying,1), ("yarn-client",1), (page](http://spark.apache.org/documentation.html),1), ([params]`.,1), (application,1), ([project,2), (prefer,1), (SparkPi,2), (<http://spark.apache.org/>,1), (engine,1), (version,1), (file,1), (documentation,,1), (MASTER,1), (example,3), (distribution.,1), (are,1), (params,1), (scala>,1), (DataFrames...
scala> wordcount.saveAsTextFile("/result")





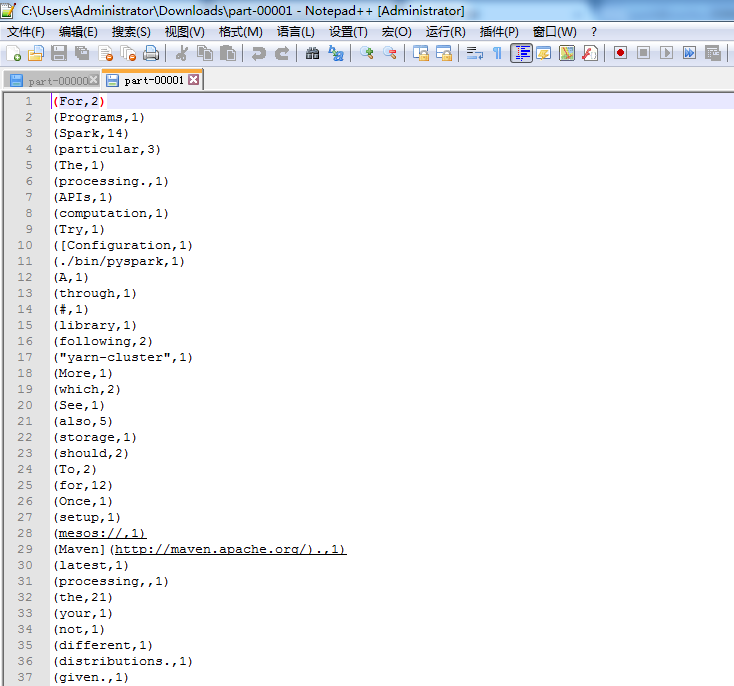
只是,仅仅对每行,做了wordcount而已。
3、对Job输出结果进行升和降序
升序
scala> val wordcount = rdd.flatMap(_.split(' ')).map((_,1)).reduceByKey(_+_).map(x => (x._2,x._1)).sortByKey(true).map(x => (x._2,x._1)).saveAsTextFile("/resultAscSorted")



同理,去下载,不多赘述。
变了


scala> val wordcount = rdd.flatMap(_.split(' ')).map((_,1)).reduceByKey(_+_).map(x => (x._2,x._1)).sortBy(true).map(x => (x._2,x._1)).saveAsTextFile("/resultAscSorted")
<console>:23: error: type mismatch;
found : Boolean(true)
required: ((Int, String)) => ?
val wordcount = rdd.flatMap(_.split(' ')).map((_,1)).reduceByKey(_+_).map(x => (x._2,x._1)).sortBy(true).map(x => (x._2,x._1)).saveAsTextFile("/resultAscSorted")
^
scala>

降序
scala> val wordcount = rdd.flatMap(_.split(' ')).map((_,1)).reduceByKey(_+_).map(x => (x._2,x._1)).sortByKey(false).map(x => (x._2,x._1)).saveAsTextFile("/resultDescSorted")


下载,同理


此刻,成功对Job输出结果进行了排序。
4、union
union的使用
scala> val rdd1 = sc.parallelize(List(('a',1),('b',1)))
rdd1: org.apache.spark.rdd.RDD[(Char, Int)] = ParallelCollectionRDD[26] at parallelize at <console>:21
scala> val rdd2 = sc.parallelize(List(('c',1),('d',1)))
rdd2: org.apache.spark.rdd.RDD[(Char, Int)] = ParallelCollectionRDD[27] at parallelize at <console>:21
scala> rdd1 union rdd2
res6: org.apache.spark.rdd.RDD[(Char, Int)] = UnionRDD[28] at union at <console>:26
scala> val result = rdd1 union rdd2
result: org.apache.spark.rdd.RDD[(Char, Int)] = UnionRDD[29] at union at <console>:25

使用collect操作,查看一下执行结果
scala> result.collect

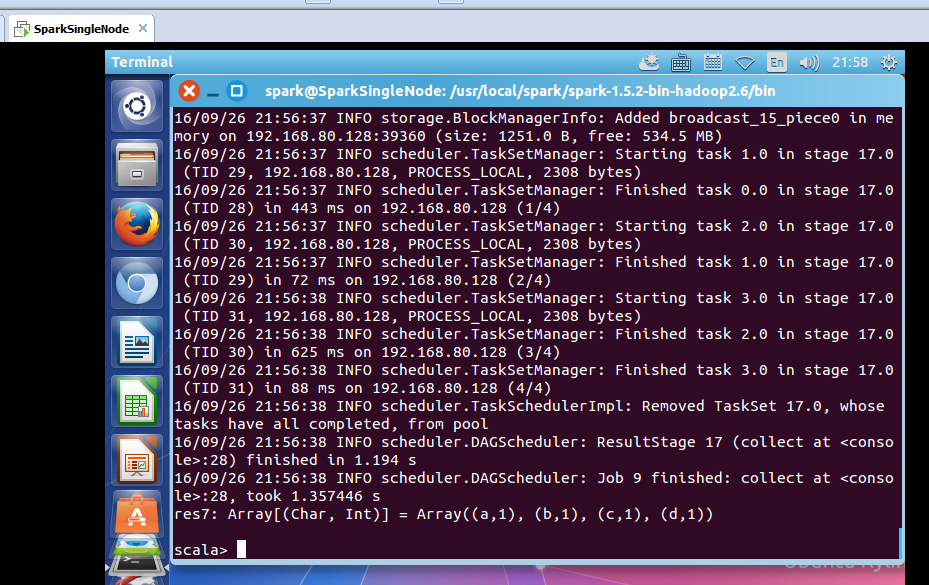
res7: Array[(Char, Int)] = Array((a,1), (b,1), (c,1), (d,1))
5、groupByKey
scala> val wordcount = rdd.flatMap(_.split(' ')).map((_,1)).groupByKey
wordcount: org.apache.spark.rdd.RDD[(String, Iterable[Int])] = ShuffledRDD[32] at groupByKey at <console>:23
scala> wordcount.collect

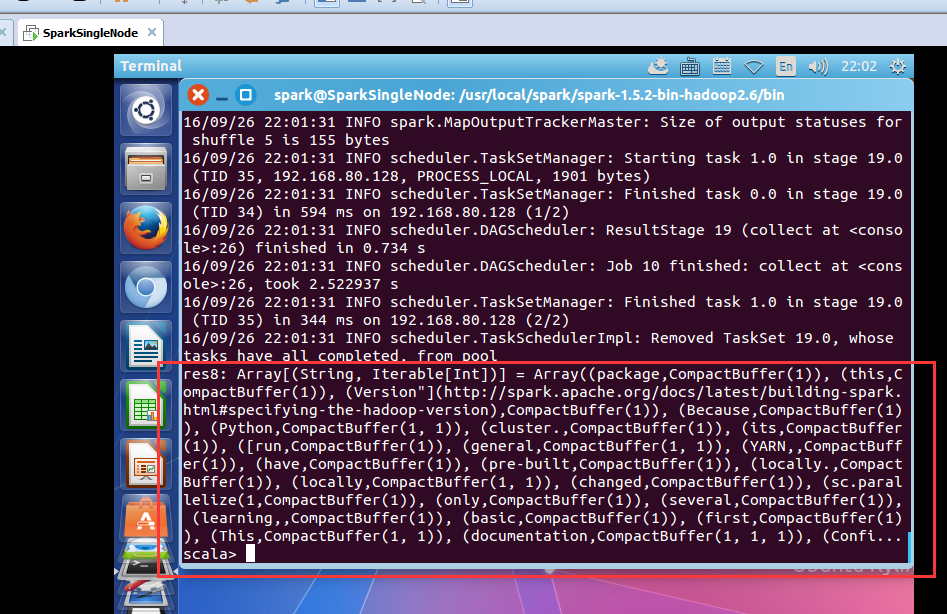
res8: Array[(String, Iterable[Int])] = Array((package,CompactBuffer(1)), (this,CompactBuffer(1)), (Version"](http://spark.apache.org/docs/latest/building-spark.html#specifying-the-hadoop-version),CompactBuffer(1)), (Because,CompactBuffer(1)), (Python,CompactBuffer(1, 1)), (cluster.,CompactBuffer(1)), (its,CompactBuffer(1)), ([run,CompactBuffer(1)), (general,CompactBuffer(1, 1)), (YARN,,CompactBuffer(1)), (have,CompactBuffer(1)), (pre-built,CompactBuffer(1)), (locally.,CompactBuffer(1)), (locally,CompactBuffer(1, 1)), (changed,CompactBuffer(1)), (sc.parallelize(1,CompactBuffer(1)), (only,CompactBuffer(1)), (several,CompactBuffer(1)), (learning,,CompactBuffer(1)), (basic,CompactBuffer(1)), (first,CompactBuffer(1)), (This,CompactBuffer(1, 1)), (documentation,CompactBuffer(1, 1, 1)), (Confi...
scala>
6、join
概念知识,参考
http://www.cnblogs.com/goforward/p/4748128.html
scala> val rdd1 = sc.parallelize(List(('a',1),('a',2),('b',3),('b',4)))
rdd1: org.apache.spark.rdd.RDD[(Char, Int)] = ParallelCollectionRDD[33] at parallelize at <console>:21
scala> val rdd2 = sc.parallelize(List(('a',5),('a',6),('b',7),('b',8)))
rdd2: org.apache.spark.rdd.RDD[(Char, Int)] = ParallelCollectionRDD[34] at parallelize at <console>:21
scala> rdd1 join rdd2
res9: org.apache.spark.rdd.RDD[(Char, (Int, Int))] = MapPartitionsRDD[37] at join at <console>:26
scala> val result = rdd1 join rdd2
result: org.apache.spark.rdd.RDD[(Char, (Int, Int))] = MapPartitionsRDD[40] at join at <console>:25
scala> result.collect
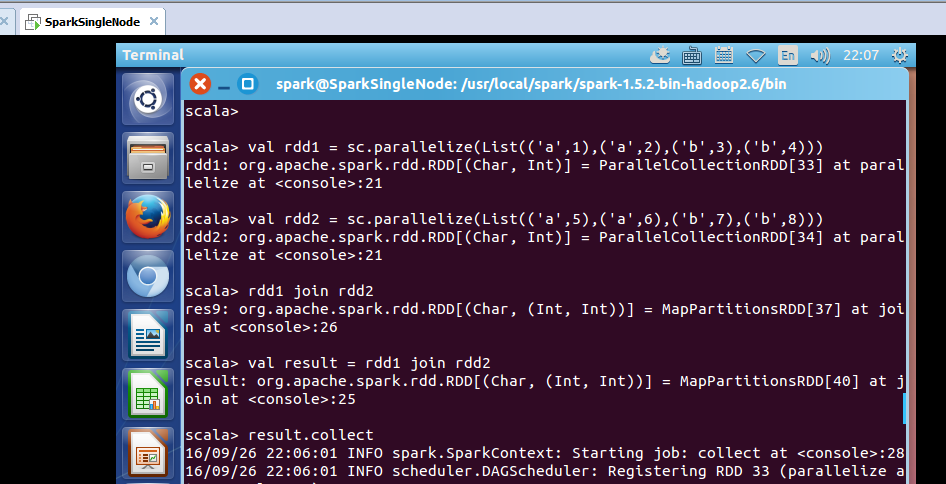

res10: Array[(Char, (Int, Int))] = Array((b,(3,7)), (b,(3,8)), (b,(4,7)), (b,(4,8)), (a,(1,5)), (a,(1,6)), (a,(2,5)), (a,(2,6)))
scala>
可见,join操作,完全是一个笛卡尔积的操作。
7、reduce
reduce本身啊,在RDD操作里,属于一个action类型的操作,会导致job作业的提交和执行。
scala> val rdd = sc.parallelize(List(1,2,3,4,5))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[41] at parallelize at <console>:21
scala> rdd.reduce(_+_)

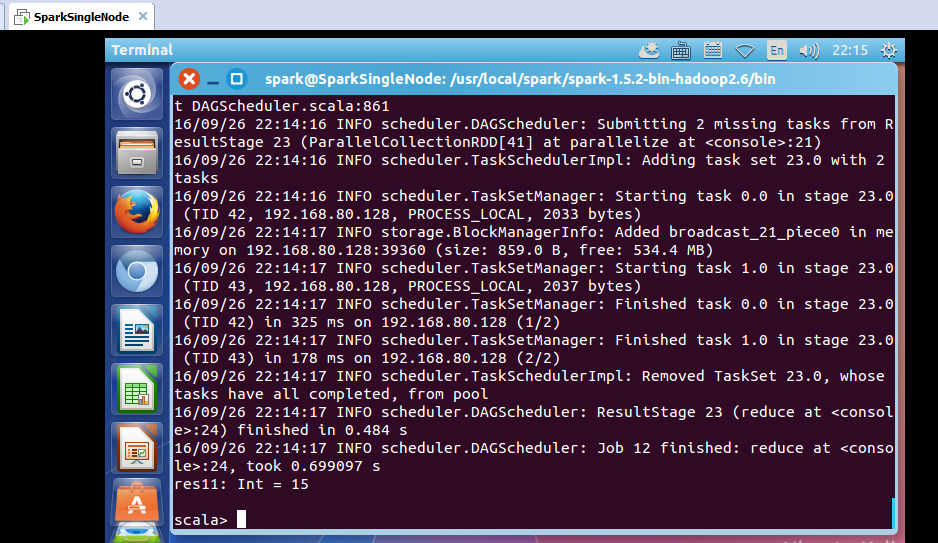
res11: Int = 15
8、lookup
scala> val rdd2 = sc.parallelize(List(('a',5),('a',6),('b',7),('b',8)))
rdd2: org.apache.spark.rdd.RDD[(Char, Int)] = ParallelCollectionRDD[42] at parallelize at <console>:21
scala> rdd2.lookup('a') //返回一个seq, (5, 6) 是把a对应的所有元素的value提出来组成一个seq


res12: Seq[Int] = WrappedArray(5, 6)

Spark RDD/Core 编程 API入门系列之map、filter、textFile、cache、对Job输出结果进行升和降序、union、groupByKey、join、reduce、lookup(一)的更多相关文章
- Spark RDD/Core 编程 API入门系列之简单移动互联网数据(五)
通过对移动互联网数据的分析,了解移动终端在互联网上的行为以及各个应用在互联网上的发展情况等信息. 具体包括对不同的应用使用情况的统计.移动互联网上的日常活跃用户(DAU)和月活跃用户(MAU)的统计, ...
- Spark RDD/Core 编程 API入门系列 之rdd案例(map、filter、flatMap、groupByKey、reduceByKey、join、cogroupy等)(四)
声明: 大数据中,最重要的算子操作是:join !!! 典型的transformation和action val nums = sc.parallelize(1 to 10) //根据集合创建RDD ...
- Spark RDD/Core 编程 API入门系列之动手实战和调试Spark文件操作、动手实战操作搜狗日志文件、搜狗日志文件深入实战(二)
1.动手实战和调试Spark文件操作 这里,我以指定executor-memory参数的方式,启动spark-shell. 启动hadoop集群 spark@SparkSingleNode:/usr/ ...
- Spark RDD/Core 编程 API入门系列 之rdd实战(rdd基本操作实战及transformation和action流程图)(源码)(三)
本博文的主要内容是: 1.rdd基本操作实战 2.transformation和action流程图 3.典型的transformation和action RDD有3种操作: 1. Trandform ...
- Spark SQL 编程API入门系列之SparkSQL的依赖
不多说,直接上干货! 不带Hive支持 <dependency> <groupId>org.apache.spark</groupId> <artifactI ...
- Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
不多说,直接上代码. Hadoop MapReduce编程 API入门系列之小文件合并(二十九) 生成的结果,作为输入源. 代码 package zhouls.bigdata.myMapReduce. ...
- HBase编程 API入门系列之create(管理端而言)(8)
大家,若是看过我前期的这篇博客的话,则 HBase编程 API入门系列之put(客户端而言)(1) 就知道,在这篇博文里,我是在HBase Shell里创建HBase表的. 这里,我带领大家,学习更高 ...
- HBase编程 API入门系列之delete(客户端而言)(3)
心得,写在前面的话,也许,中间会要多次执行,连接超时,多试试就好了. 前面的基础,如下 HBase编程 API入门系列之put(客户端而言)(1) HBase编程 API入门系列之get(客户端而言) ...
- HBase编程 API入门系列之get(客户端而言)(2)
心得,写在前面的话,也许,中间会要多次执行,连接超时,多试试就好了. 前面是基础,如下 HBase编程 API入门系列之put(客户端而言)(1) package zhouls.bigdata.Hba ...
随机推荐
- 关于Linux内核学习的误区以及相关书籍介绍
http://www.hzlitai.com.cn/article/ARM9-article/system/1605.html 写给Linux内核新手-关于Linux内核学习的误区 先说句正经的:其实 ...
- html 头部正常用法
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- [DevExpress]DxValidationProvider分享
前些日子从研究所临时调回公司,帮忙做另外一个项目的控件验证工作,其实内容非常的简单,就是将用户即将提交至服务器的数据先做一个本地验证,以达到减少服务器压力.提高用户体验的目的. 附上一张图片 这是官方 ...
- mongodb 非 admin 库 认证登陆失败 原因(百度好多都 是渣)db.addUser() 请走开。
首先先晒一下log 日志错误信息 2016-07-13T22:19:43.667+0800 I ACCESS [conn4] authenticate db: finddemo { aut henti ...
- CentOS系统安全配置
http://down.51cto.com/data/318797 http://www.centos.bz/2011/07/centos-system-security-configure/ htt ...
- 以查询方式实现1s定时
以查询控制器的控制位状态来实现1s定时. #include <reg52.h> sbit LED = P0^; unsigned ; void main () { LED = ; // 点 ...
- python 数据类型(元组(不可变列表),字符串
元组(不可变列表) 创建元组: ages = (11, 22, 33, 44, 55) 或 ages = tuple((11, 22, 33, 44, 55)) 一般情况下是不需要被人该的数值才使用元 ...
- osg(OpenSceneGraph)学习笔记1:智能指针osg::ref_ptr<>
OSG的智能指针,osg::ref_ptr<> osg::Referenced类管理引用计数内存块,osg::ref_ptr需要使用以它为基类的其它类作为模板参数. osg::ref_pt ...
- juery mobile select下来菜单选项提交form问题
注意: data-native-menu="false" 虽然具有渲染作用,但是无法进行js提交. <script type="text/javascript&q ...
- [简历] PHP 技能关键字列表
本技能关键字列表是从最近招聘PHP的数百份JD中统计出来的,括号中是出现的词频.如果你的简历要投递给有机器(简历分选系统)和不如机器(不懂技术的HR)筛选简历环节的地方,请一定从下边高频关键词中选择5 ...