高并发下的HashMap,ConcurrentHashMap
参照:
http://mp.weixin.qq.com/s/dzNq50zBQ4iDrOAhM4a70A
http://mp.weixin.qq.com/s/1yWSfdz0j-PprGkDgOomhQ
JDK1.7 多线程下死循环
源代码:
/**
* Rehashes the contents of this map into a new array with a
* larger capacity. This method is called automatically when the
* number of keys in this map reaches its threshold.
*
* If current capacity is MAXIMUM_CAPACITY, this method does not
* resize the map, but sets threshold to Integer.MAX_VALUE.
* This has the effect of preventing future calls.
*
* @param newCapacity the new capacity, MUST be a power of two;
* must be greater than current capacity unless current
* capacity is MAXIMUM_CAPACITY (in which case value
* is irrelevant).
*/
void resize( int newCapacity) {
// 当前数组
Entry[] oldTable = table;
// 当前数组容量
int oldCapacity = oldTable.length ;
// 如果当前数组已经是默认最大容量MAXIMUM_CAPACITY ,则将临界值改为Integer.MAX_VALUE 返回
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
} // 使用新的容量创建一个新的链表数组
Entry[] newTable = new Entry[newCapacity];
// 将当前数组中的元素都移动到新数组中
transfer(newTable);
// 将当前数组指向新创建的数组
table = newTable;
// 重新计算临界值
threshold = (int)(newCapacity * loadFactor);
} /**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable) {
// 当前数组
Entry[] src = table;
// 新数组长度
int newCapacity = newTable.length ;
// 遍历当前数组的元素,重新计算每个元素所在数组位置
for (int j = 0; j < src. length; j++) {
// 取出数组中的链表第一个节点
Entry<K,V> e = src[j];
if (e != null) {
// 将旧链表位置置空
src[j] = null;
// 循环链表,挨个将每个节点插入到新的数组位置中
do {
// 取出链表中的当前节点的下一个节点
Entry<K,V> next = e. next;
// 重新计算该链表在数组中的索引位置
int i = indexFor(e. hash, newCapacity);
// 将下一个节点指向newTable[i]
e. next = newTable[i];
// 将当前节点放置在newTable[i]位置
newTable[i] = e;
// 下一次循环
e = next;
} while (e != null);
}
}
}
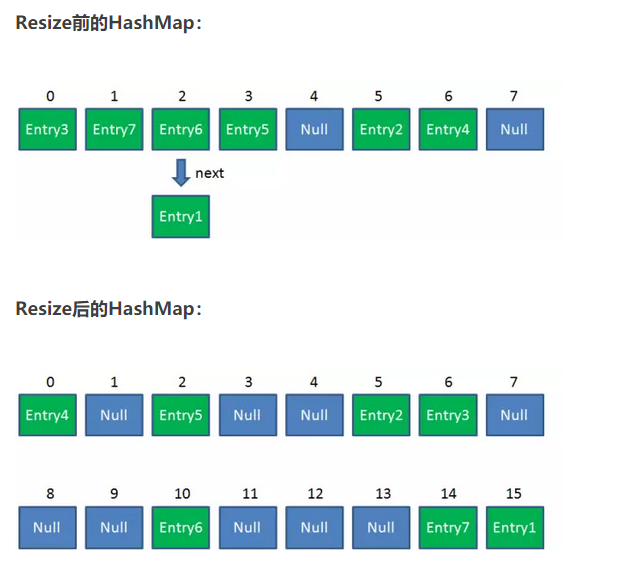
resize步骤:
1.扩容
创建一个新的Entry空数组,长度是原数组的2倍。
2.ReHash
遍历原Entry数组,把所有的Entry重新Hash到新数组。为什么要重新Hash呢?因为长度扩大以后,Hash的规则也随之改变。
ConcuttrntHashMap
改变线程安全的方法:
- HashTable
- Collections.synchronizedMap
性能是个为你,无论是读操作还是写操作,都会给整个集合加锁

利用 ConcurrentHashMap
Segment是什么呢?Segment本身就相当于一个HashMap对象。
同HashMap一样,Segment包含一个HashEntry数组,数组中的每一个HashEntry既是一个键值对,也是一个链表的头节点。
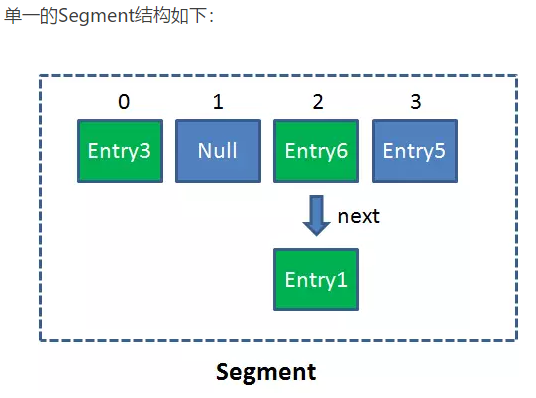
在ConcurrentHashMap集合中有多少个呢?有2的N次方个segment

ConcurrentHashMap优势就是采用了[锁分段技术]
每个segment就好比一个自治区,读写操作高度自治,segment之间相互不影响
- 不同Segment的写入是可以并发执行的。
- 同一Segment的写和读是可以并发执行的。
- Segment的写入是需要上锁的,因此对同一Segment的并发写入会被阻塞。
Get方法:
1.为输入的Key做Hash运算,得到hash值。
2.通过hash值,定位到对应的Segment对象
3.再次通过hash值,定位到Segment当中数组的具体位置。
Put方法:
1.为输入的Key做Hash运算,得到hash值。
2.通过hash值,定位到对应的Segment对象
3.获取可重入锁
4.再次通过hash值,定位到Segment当中数组的具体位置。
5.插入或覆盖HashEntry对象。
6.释放锁。
ConcurrentHashMap读写都需要二次定位
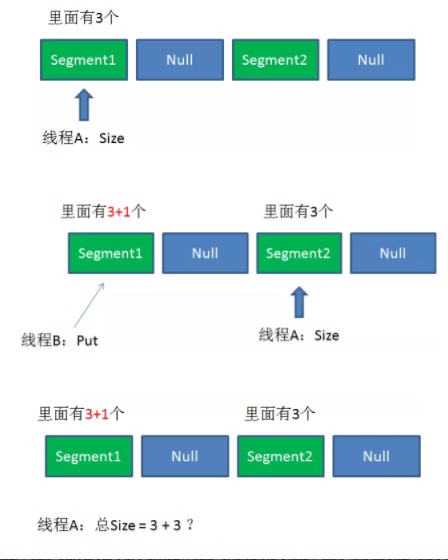
size的一致性问题?
源代码:
public int size() {
// Try a few times to get accurate count. On failure due to
// continuous async changes in table, resort to locking.
final Segment<K,V>[] segments = this.segments;
int size;
boolean overflow; // true if size overflows 32 bits
long sum; // sum of modCounts
long last = 0L; // previous sum
int retries = -1; // first iteration isn't retry
try {
for (;;) {
if (retries++ == RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation
}
sum = 0L;
size = 0;
overflow = false;
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) {
sum += seg.modCount;
int c = seg.count;
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
if (sum == last)
break;
last = sum;
}
} finally {
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
return overflow ? Integer.MAX_VALUE : size;
}
1.遍历所有的Segment。
2.把Segment的元素数量累加起来。
3.把Segment的修改次数累加起来。
4.判断所有Segment的总修改次数是否大于上一次的总修改次数。如果大于,说明统计过程中有修改,重新统计,尝试次数+1;如果不是。说明没有修改,统计结束。
5.如果尝试次数超过阈值,则对每一个Segment加锁,再重新统计。
6.再次判断所有Segment的总修改次数是否大于上一次的总修改次数。由于已经加锁,次数一定和上次相等。
7.释放锁,统计结束。
为了尽量不锁住所有Segment,首先乐观地假设Size过程中不会有修改。当尝试一定次数,才无奈转为悲观锁,锁住所有Segment保证强一致性。
高并发下的HashMap,ConcurrentHashMap的更多相关文章
- 对HashMap的理解(二):高并发下的HashMap
在分析hashmap高并发场景之前,我们要先搞清楚ReHash这个概念.ReHash是HashMap在扩容时的一个步骤.HashMap的容量是有限的.当经过多次元素插入,使得HashMap达到一定饱和 ...
- JDK1.7 ConcurrentHashMap--解决高并发下的HashMap使用问题
高并发下也可以使用HashTable .Collections.synchronizedMap因为他们是线程安全的,但是却牺牲了性能,无论是读操作.写操作都是给整个集合加锁,导致同一时间内其他操作均为 ...
- JDK1.7 高并发下的HashMap
HashMap的容量是有限的.当经过多次元素插入,使得HashMap达到一定饱和度时,Key映射位置发生冲突的几率会逐渐提高. 这时候,HashMap需要扩展它的长度,也就是进行Resize. 影响发 ...
- 高并发下,HashMap会产生哪些问题?
HashMap在高并发环境下会产生的问题 HashMap其实并不是线程安全的,在高并发的情况下,会产生并发引起的问题: 比如: HashMap死循环,造成CPU100%负载 触发fail-fast 下 ...
- 漫画:高并发下的HashMap
这一期我们来讲解高并发环境下,HashMap可能出现的致命问题. HashMap的容量是有限的.当经过多次元素插入,使得HashMap达到一定饱和度时,Key映射位置发生冲突的几率会逐渐提高. 这时候 ...
- 高并发下的Java数据结构(List、Set、Map、Queue)
由于并行程序与串行程序的不同特点,适用于串行程序的一些数据结构可能无法直接在并发环境下正常工作,这是因为这些数据结构不是线程安全的.本节将着重介绍一些可以用于多线程环境的数据结构,如并发List.并发 ...
- HashMap高并发下存在的问题
原文链接:https://blog.csdn.net/bjwfm2011/article/details/81076736 1.什么是HashMap? HashMap底层原理 HashMap是存储键值 ...
- Java高并发下多线程编程
1.创建线程 Java中创建线程主要有三种方式: 继承Thread类创建线程类: 定义Thread类的子类,并重写该类的run方法,该run方法的方法体就代表了线程要完成的任务.因此也把run方法称为 ...
- 【mysql】mysql增加version字段实现乐观锁,实现高并发下的订单库存的并发控制,通过开启多线程同时处理模拟多个请求同时到达的情况 + 同一事务中使用多个乐观锁的情况处理
mysql增加version字段实现乐观锁,实现高并发下的订单库存的并发控制,通过开启多线程同时处理模拟多个请求同时到达的情况 ==================================== ...
随机推荐
- C、C++、C#中struct的简单比较
比较这三者是因为C.C++.C#这三者存在着一定的血缘关系,而他们三者都有的struct却有很大的不同. 功能 C中的struct是最简单的.只能有成员变量而不能有成员函数. C++和C#中都支持,而 ...
- android上部署tensorflow
https://www.jianshu.com/p/ddeb0400452f 按照这个博客就可以 https://github.com/CrystalChen1017/TSFOnAndroid 这个博 ...
- Django models多表操作
title: Django models多表操作 tags: Django --- 多表操作 单独创建第三张表的情况 推荐使用的是使用values/value_list,selet_related的方 ...
- Vue 后台管理
这里是结合vue和element快速成型的一个demo 里面展示了基本的后台管理界面的大体结构和element的基本操作 GitHub的地址:https://github.com/wwwming/ad ...
- UpdatePanel中点击按钮Session过期跳转页面相关问题:Sys.WebForms.PageRequestManagerParserErrorException:无法分析从服务器收到的消息
使用 Response.Write("<script language=javascript>window.location.href='Login.aspx';</scr ...
- mysql锁机制(转载)
锁是计算机协调多个进程或线程并发访问某一资源的机制 .在数据库中,除传统的 计算资源(如CPU.RAM.I/O等)的争用以外,数据也是一种供许多用户共享的资源.如何保证数据并发访问的一致性.有效性是所 ...
- python爬虫基础09-selenium大全3/8-Remote Webdriver
Selenium笔记(3)Remote Webdriver 本文集链接:https://www.jianshu.com/nb/25338984 简介 selenium.webdriver.remote ...
- 收集的有关mdk 3的使用方法
收集来自网络上的有关mdk3的一些使用方法以及技巧(持续更新) b beacon泛洪攻击 -f 指定wifi名称的文件夹 -n 加上wifi名称 -w Fake WEP encrypted sta ...
- (转)全网最!详!细!tarjan算法讲解
byhttp://www.cnblogs.com/uncle-lu/p/5876729.html 全网最详细tarjan算法讲解,我不敢说别的.反正其他tarjan算法讲解,我看了半天才看懂.我写的这 ...
- JAVA-基础(一)
1.一个变量可以声明为final,这样做的目的是阻止它的内容被修改.这意味着在声明final 变量的时候,你必须初始化它(在这种用法上,final类似于C/C++中的const). 例如: final ...