day03 set集合,文件操作,字符编码以及函数式编程
嗯哼,第三天了
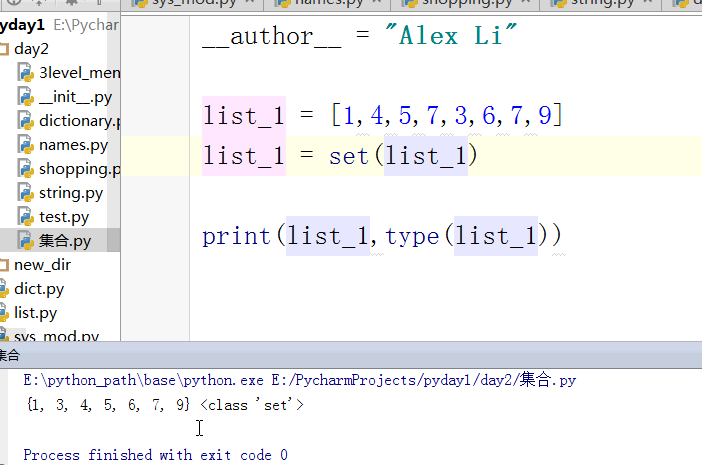
我们来get 下新技能,集合,个人认为集合就是用来list 比较的,就是把list 转换为set 然后做一些列表的比较啊求差值啊什么的。
先看怎么生成集合:
list_s = [1,3,4,5,7,9]
list_t = [1,3,4,5,7,9]
dic_1 = {
'name':'shenyang',
'age':16
}
dic_2 = {'name':'wanglu',
'age':18,
'sex':'girl'} s = set(list_s)
t = set(list_t)
d = set(dic_1)
n = set(dic_2)
print(s,type(s))
print(t,type(t))
print(d,type(d))
print(n,type(n))
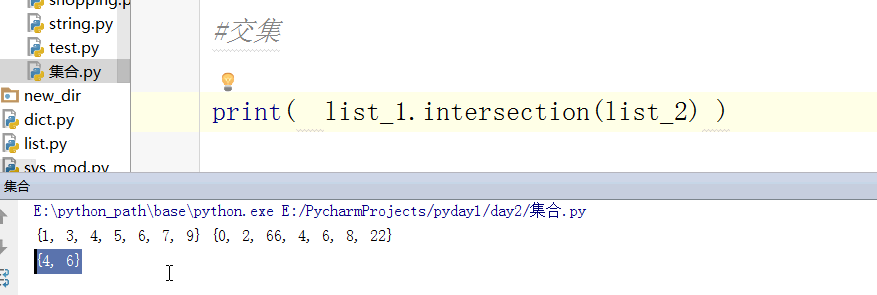
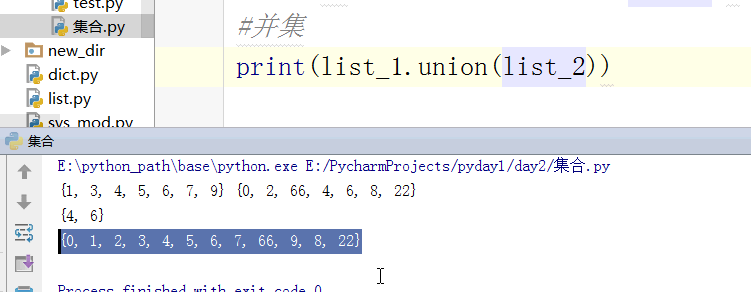
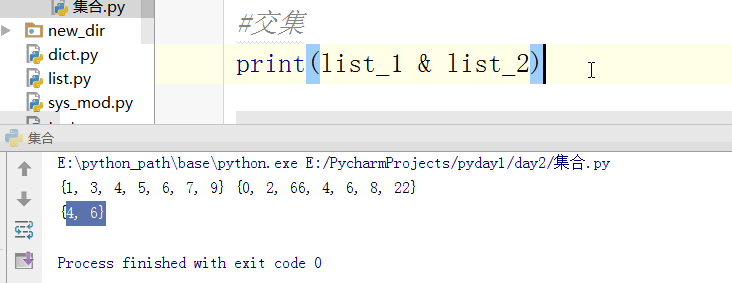
找并集:
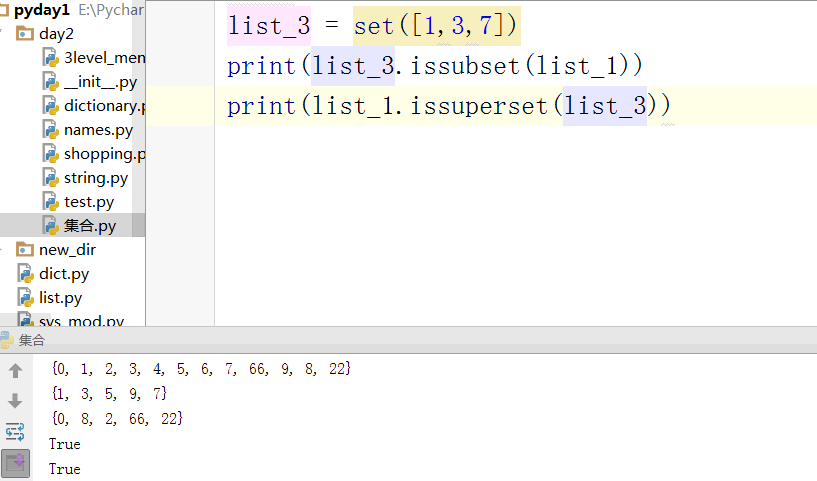
检查是否是子集
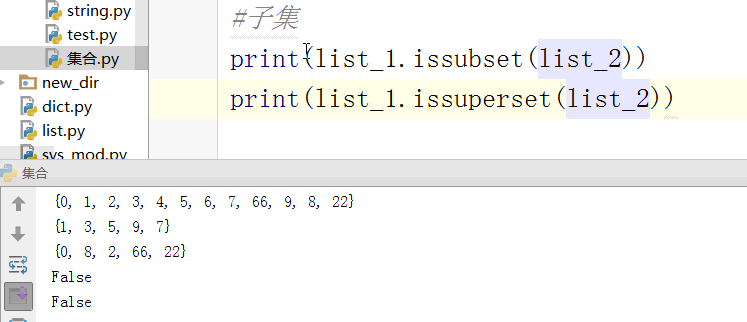
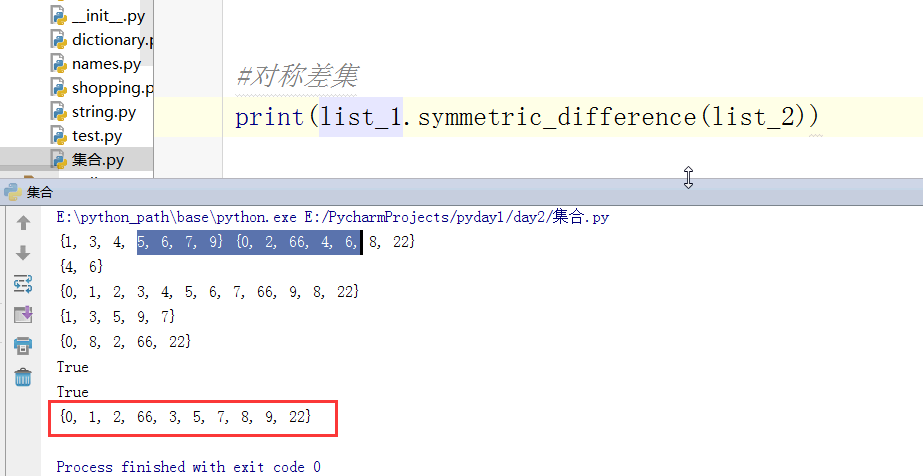
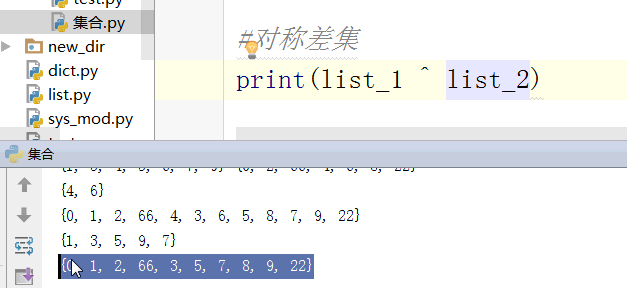
#对称差集 把交集去掉,留两边互相都没有的
检查两个set 是否有交集,有返回False 没有返回True

使用运算符 来测试关系:
添加:
#!/usr/bin/env python3
s = set([1,3,4,5,7,9])
t = set([2,3,4,6,8,10])
#交集
print(s & t)
#并集
print(s | t)
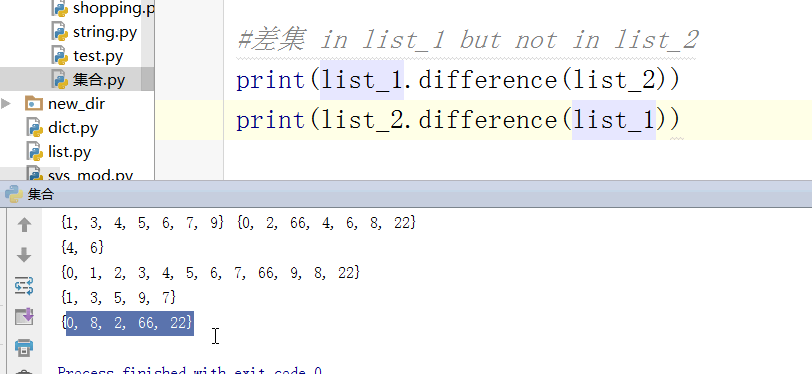
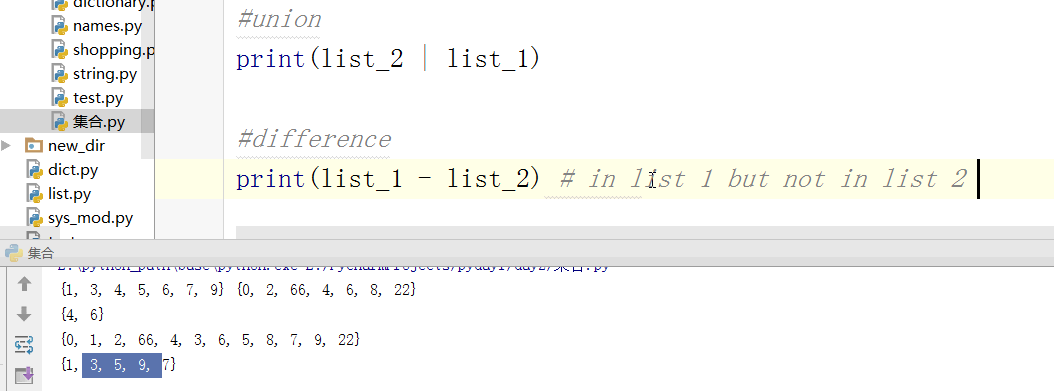
#差集 有顺序,找出前面有的后面没有的
print(s - t)
#对称差集
print(s ^ t) #往集合里添加
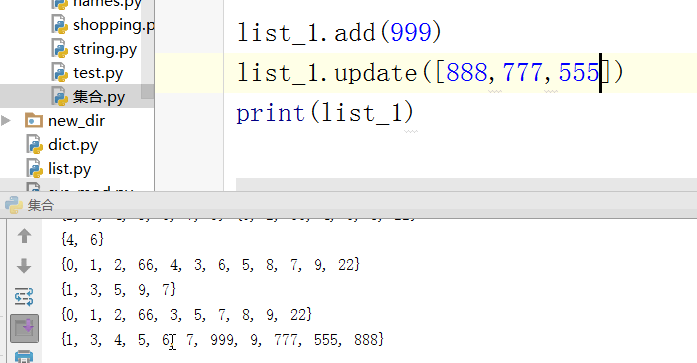
s.add(10) #添加一项
print(s)
s.update([13,14,15]) #添加多项
print(s)
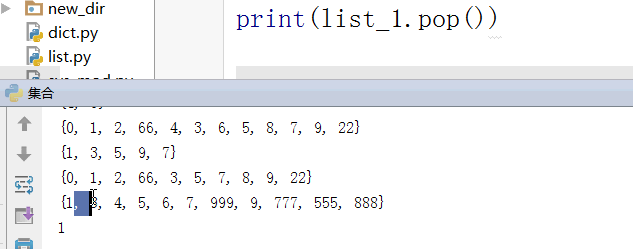
#删除
s.pop() #随机删除
print(s)
s.remove(13) #删除指定项
print(s) #成员测试
if 14 in s:
print("is in")
if 13 not in s:
print("is not in")


实验:
1 写:
file1 = open("music.lrc","r",encoding="utf-8")
r_file1 = file1.read()
print(r_file1)
file1.close()
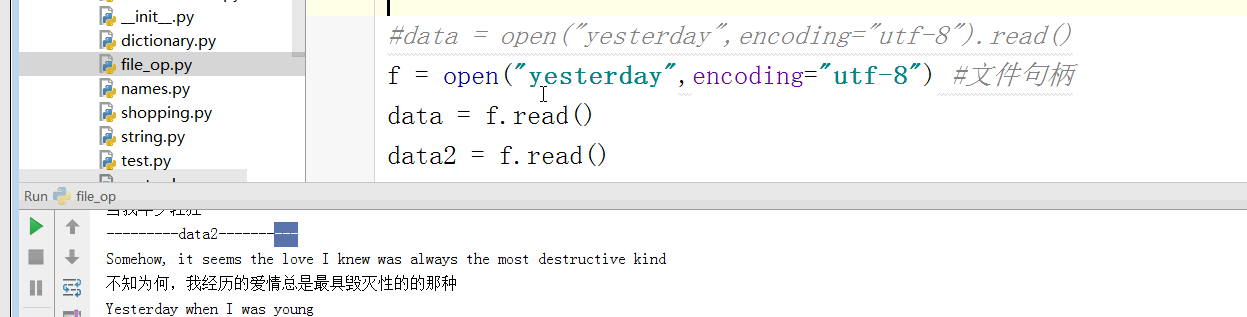
2 读:
file1 = open("music.lrc","r",encoding="utf-8")
r_file1 = file1.read()
print(r_file1)
file1.close()
3 追加: 并不能读
file1 = open("music.lrc","a",encoding="utf-8")
file1.write("This is the last write")
file1 = open("music.lrc","r",encoding="utf-8")
r_file1 = file1.read()
print(r_file1)
file1.close()
一行一行读:



判断行号,只能自己加一个计数器 高逼格的办法

句柄指针: 是按字符计算的

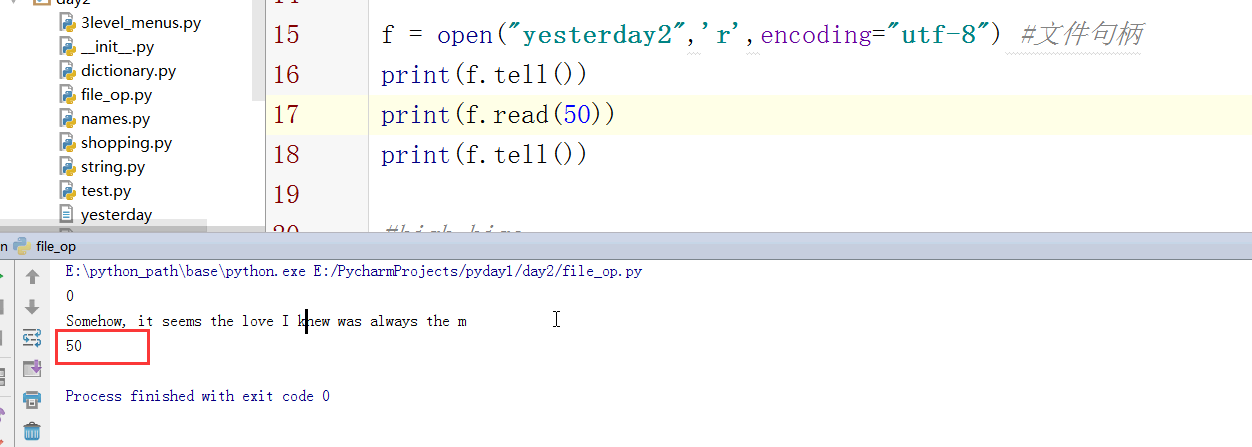

打印文件的字符编码:




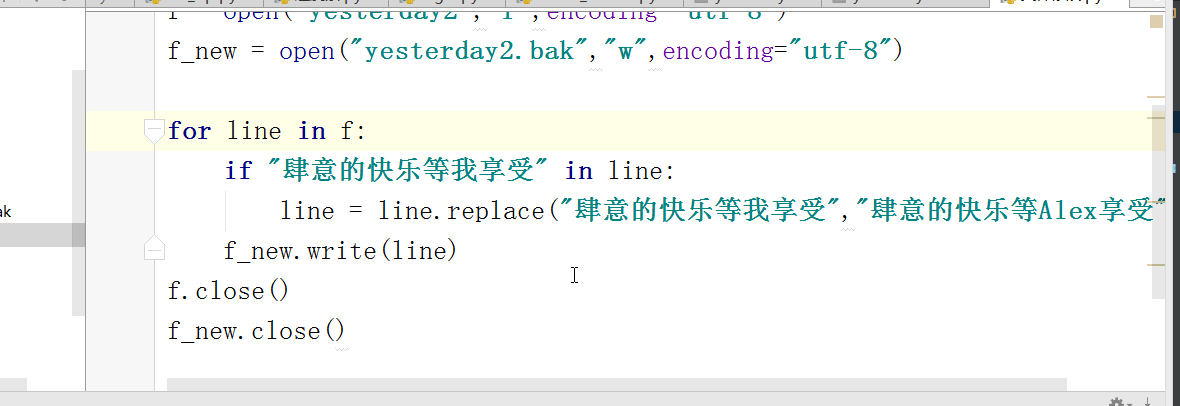
修改文件:
实践:
#!/usr/bin/env python3
# Auth: Shen Yang
f1 = open("lrc.db","r",encoding="utf-8")
f2 = open("lrc2.db","w",encoding="utf-8")
for line in f1:
if "王山炮" in line:
line = line.replace("王山炮","Alex")
f2.write(line)
f1.close()
f2.close()
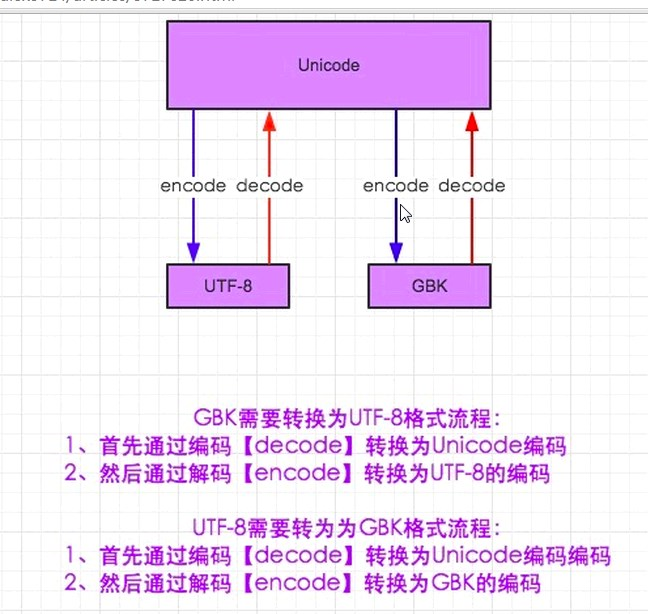

pyhton 3 默认所有的数据类型就是Unicode 你哈 还是 utf-8 除非你转到gbk 上面的只是说这个文件的编码

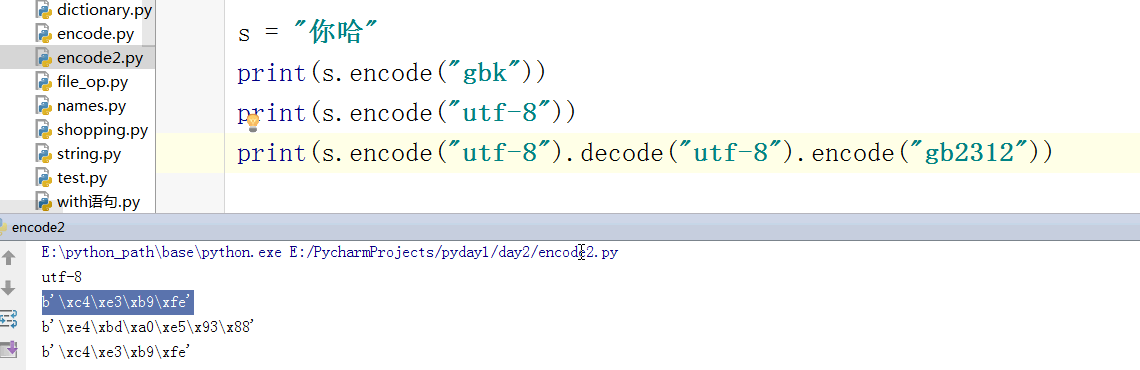
python 3 中 encode 不但转换了编码还变成了bytes 格式的

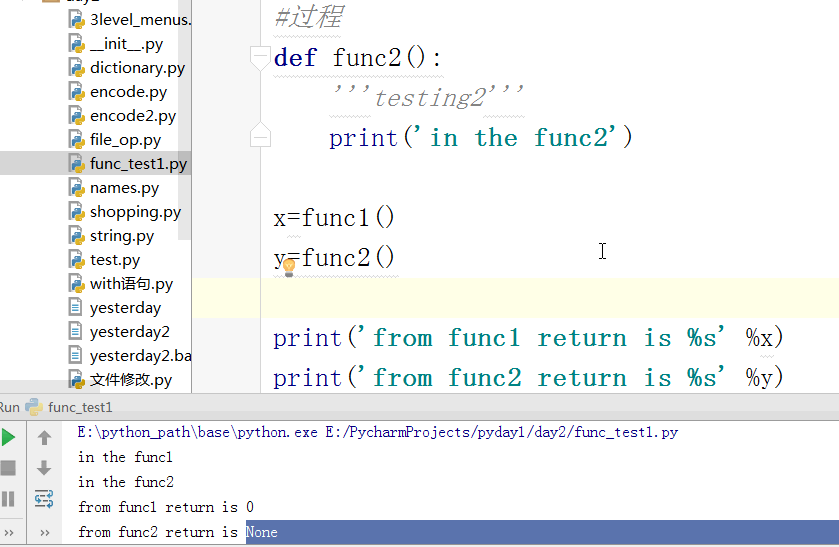
过程就是没有返回值的函数 但是在python 中 隐式的给过程一个结果
练习:
import time
def logger():
time_format = '%T-%m-%d %X'
time_current = time.strftime(time_format)
with open("fun.log","a+",encoding="utf-8") as f:
f.write("{_format} aadd the log\n".format(_format=time_current))
time.sleep(0.5)
def test1():
print("This is test1")
logger()
def test2():
print("This is test2")
logger()
def test3():
print("This is test3")
logger()
test1()
test2()
test3()

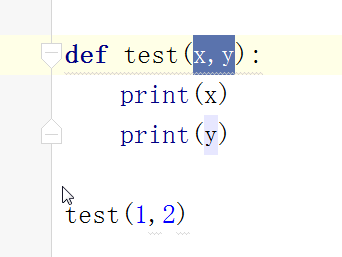

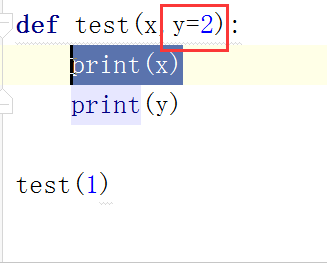

默认参数特点:

传递非固定实参的时候形参使用以* 开头的任意字符即可但不要这样写,就写args :


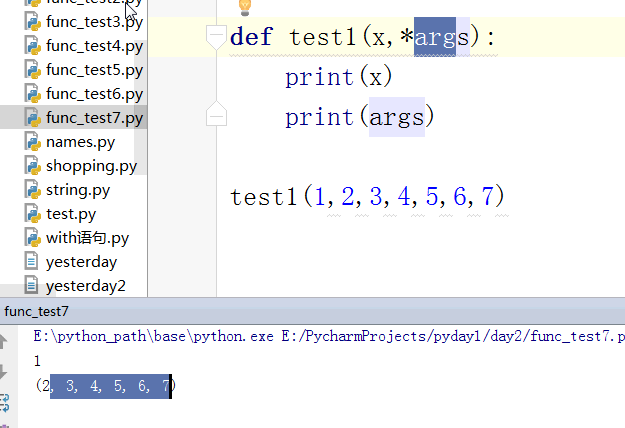

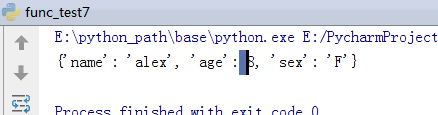
以字典的方式保存参数
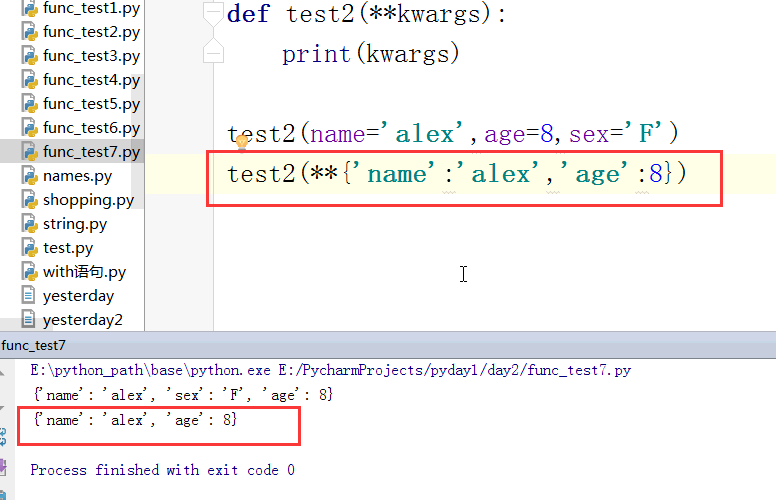

默认参数一定要放在** 的前面



name = "yang"
Job = "Pyther"
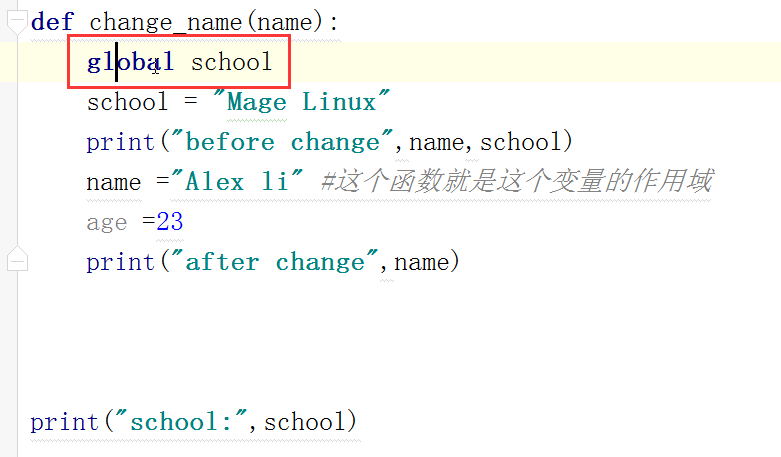
def change_name(name="Lu"):
#global Job
Job = "Shell" print("name:",name,Job) change_name(name="Wang")
print(name,Job)
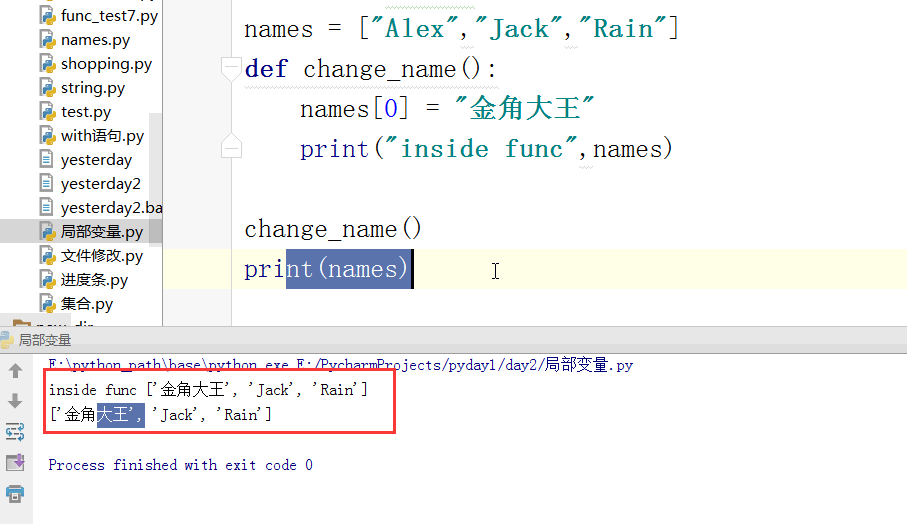
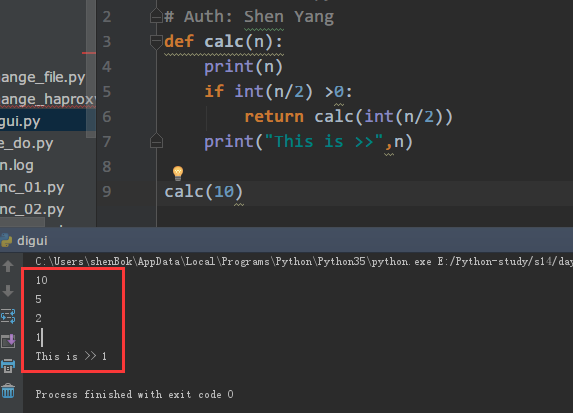
def calc(n):
prin(n)
return calc(n)
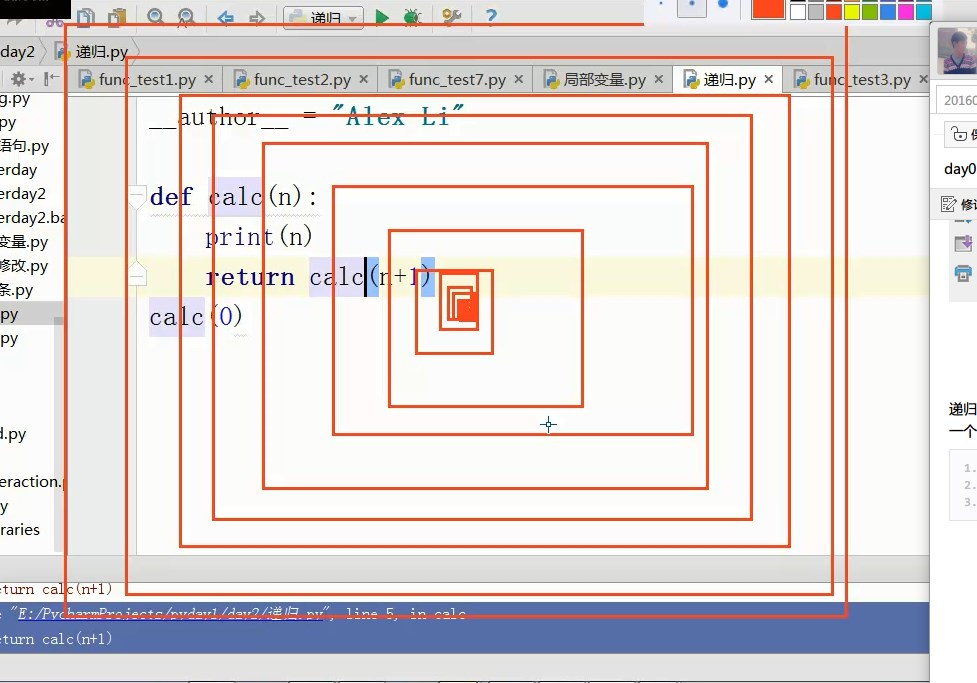

最简单的递归:
#!/usr/bin/env python3
# Auth: Shen Yang
def calc(n):
print(n)
if int(n/2) >0:
return calc(int(n/2))
print("This is >>",n)
calc(10)
def add(a,b,f):
return f(a) + f(b)
res = add(3,-6,abs)
print(res)
day03 set集合,文件操作,字符编码以及函数式编程的更多相关文章
- python基础之 列表、元组操作 字符串操作 字典操作 集合操作 文件操作 字符编码与转码
本节内容 列表.元组操作 字符串操作 字典操作 集合操作 文件操作 字符编码与转码 1. 列表.元组操作 列表是我们最以后最常用的数据类型之一,通过列表可以对数据实现最方便的存储.修改等操作 定义列表 ...
- python学习笔记(2)--列表、元组、字符串、字典、集合、文件、字符编码
本节内容 列表.元组操作 字符串操作 字典操作 集合操作 文件操作 字符编码与转码 1.列表和元组的操作 列表是我们以后最长用的数据类型之一,通过列表可以最方便的对数据实现最方便的存储.修改等操作 定 ...
- Day2 - Python基础2 列表、字符串、字典、集合、文件、字符编码
本节内容 列表.元组操作 数字操作 字符串操作 字典操作 集合操作 文件操作 字符编码与转码 1. 列表.元组操作 列表是我们最以后最常用的数据类型之一,通过列表可以对数据实现最方便的存储.修改等操作 ...
- Python基础2 列表 元祖 字符串 字典 集合 文件操作 -DAY2
本节内容 列表.元组操作 字符串操作 字典操作 集合操作 文件操作 字符编码与转码 1. 列表.元组操作 列表是我们最以后最常用的数据类型之一,通过列表可以对数据实现最方便的存储.修改等操作 定义列表 ...
- linux下改变文件的字符编码
首先确定文件的原始字符编码: $ file -bi test.txt 然后用 iconv 转换字符编码 $ iconv -f from-encoding -t to-encoding file > ...
- Gnu Linux下文件的字符编码及转换工具
/********************************************************************* * Author : Samson * Date ...
- eclipse设置新建jsp文件默认字符编码为utf-8
在使用Eclipse开发中,编码默认是ISO-8859-1,不支持中文.这样我们每次新建文件都要手动修改编码,非常麻烦.其实我们可以设置文件默认编码,今后再新建文件时就不用修改编码了. 1.打开Ecl ...
- python3笔记十八:python列表元组字典集合文件操作
一:学习内容 列表元组字典集合文件操作 二:列表元组字典集合文件操作 代码: import pickle #数据持久性模块 #封装的方法def OptionData(data,path): # ...
- Python基础-week03 集合 , 文件操作 和 函数详解
一.集合及其运算 1.集合的概念 集合是一个无序的,不重复的数据组合,它的主要作用如下 *去重,把一个列表变成集合,就自动去重了 *关系测试,测试两组数据之前的交集.并集.差集.子集.父级.对称差集, ...
随机推荐
- java读取文件封装的一个类(有部分代码借鉴别人的)
package modbus.rtu.calc; import java.io.BufferedReader; import java.io.FileInputStream; import java. ...
- UIButton 图片文字位置
在实际开发过程中经常在按钮上添加文字和图片,位置和图片的位置根据需求放置也是不一样的.下面实现了各种显示方式,如下图: UIButton+LSAdditions.h // // UIButton+LS ...
- mysql主从设置windows
MySQL 主从复制是其最重要的功能之一.主从复制是一台服务器充当主服务器,另一台或多台服务器充当从服务器,主机自动复制到从机.对于多级复制,数据服务器即可充当主机,也可充当从机.MySQL 复制的基 ...
- 文末两大福利 | 微软Inspire大会全接触:微软发布Microsoft 365......
在7月11日举行的“Inspire年度合作伙伴大会”上 ,微软首席执行官萨提亚·纳德拉发布了Microsoft 365. 它包含了:Office 365.Windows 10和企业移动性+安全性(En ...
- Python中的绝对路径和相对路径
大牛们应该对路径都很了解了,这篇文章主要给像我这样的入门小白普及常识用的,啊哈 下面的路径介绍针对windows,其他平台的暂时不是很了解. 在编写的py文件中打开文件的时候经常见到下面其中路径的表达 ...
- JavaScript_3_输出
1. JavaScript通常用于操作HTML元素,可以使用getElementById(id)方法. JavaScript由Web浏览器来执行. 2. document.write()仅仅向文档输出 ...
- HDU 2188 悼念512汶川大地震遇难同胞——选拔志愿者(巴什博弈)
思路:若能给对方留下m+1,就可以胜.否则败. #include <iostream> using namespace std; int main() { int t,n,m;cin> ...
- UVA12897 - Decoding Baby Boos
没必要每次都真的修改一遍字母值,用一个标记表示字母最后的值,最后一遍的时候再进行修改 #include<cstdio> #include<cstring> +; char st ...
- [论文理解] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks 简介 Faster R-CNN是很经典的t ...
- web.xml 中 resource-ref 的注意事项
配置说明: web.xml 中配置 <resource-ref> <description>Employees Database for HR Applications< ...