Calculus on Computational Graphs: Backpropagation
Calculus on Computational Graphs: Backpropagation
Introduction
Backpropagation is the key algorithm that makes training deep models computationally tractable. For modern neural networks, it can make training with gradient descent as much as ten million times faster, relative to a naive implementation. That’s the difference between a model taking a week to train and taking 200,000 years.
Beyond its use in deep learning, backpropagation is a powerful computational tool in many other areas, ranging from weather forecasting to analyzing numerical stability – it just goes by different names. In fact, the algorithm has been reinvented at least dozens of times in different fields (seeGriewank (2010)). The general, application independent, name is “reverse-mode differentiation.”
Fundamentally, it’s a technique for calculating derivatives quickly. And it’s an essential trick to have in your bag, not only in deep learning, but in a wide variety of numerical computing situations.
Computational Graphs
Computational graphs are a nice way to think about mathematical expressions. For example, consider the expression e=(a+b)∗(b+1). There are three operations: two additions and one multiplication. To help us talk about this, let’s introduce two intermediary variables, c and d so that every function’s output has a variable. We now have:
To create a computational graph, we make each of these operations, along with the input variables, into nodes. When one node’s value is the input to another node, an arrow goes from one to another.
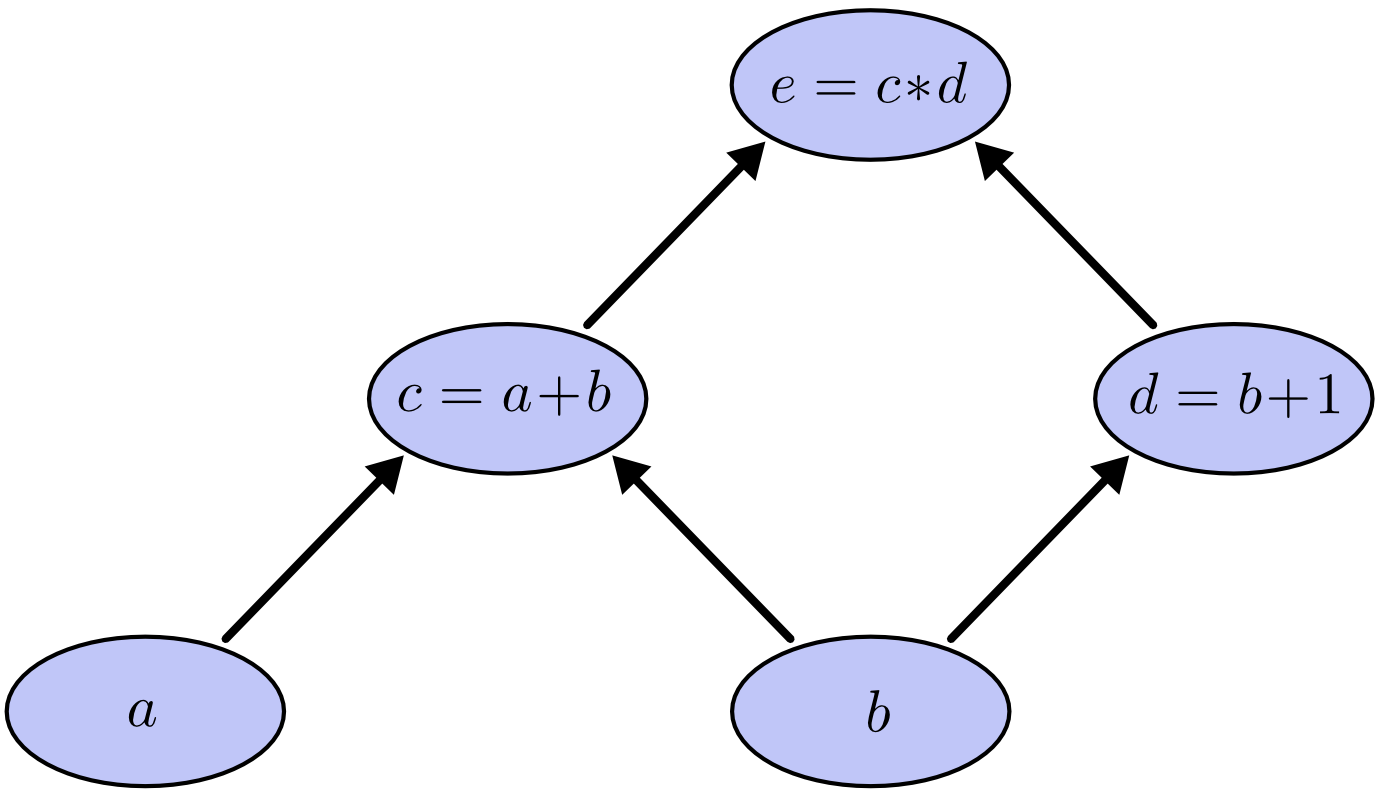
These sorts of graphs come up all the time in computer science, especially in talking about functional programs. They are very closely related to the notions of dependency graphs and call graphs. They’re also the core abstraction behind the popular deep learning framework Theano.
We can evaluate the expression by setting the input variables to certain values and computing nodes up through the graph. For example, let’s set a=2 and b=1:
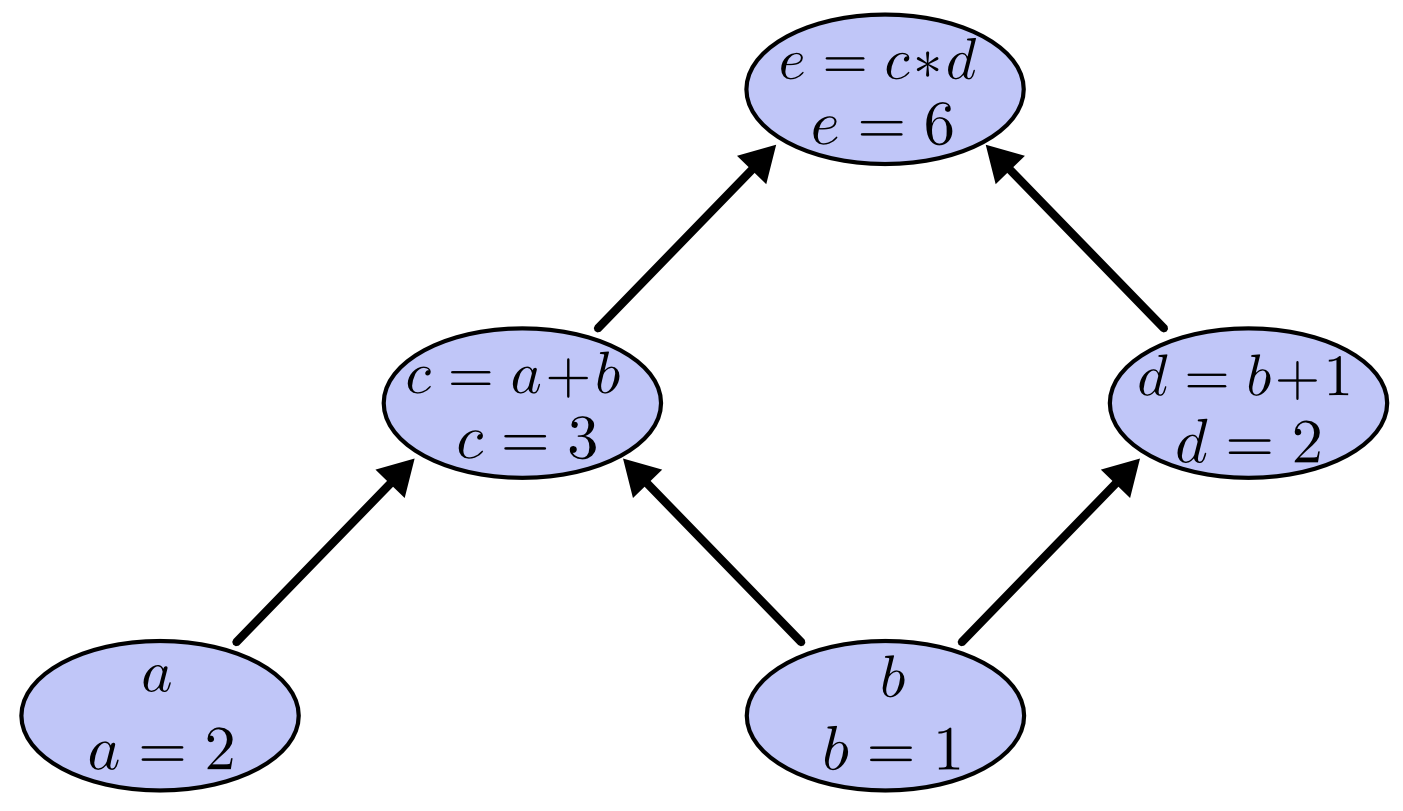
The expression evaluates to 6.
Derivatives on Computational Graphs
If one wants to understand derivatives in a computational graph, the key is to understand derivatives on the edges. If a directly affects c, then we want to know how it affects c. If achanges a little bit, how does c change? We call this the partial derivative of c with respect to a.
To evaluate the partial derivatives in this graph, we need the sum rule and the product rule:
Below, the graph has the derivative on each edge labeled.
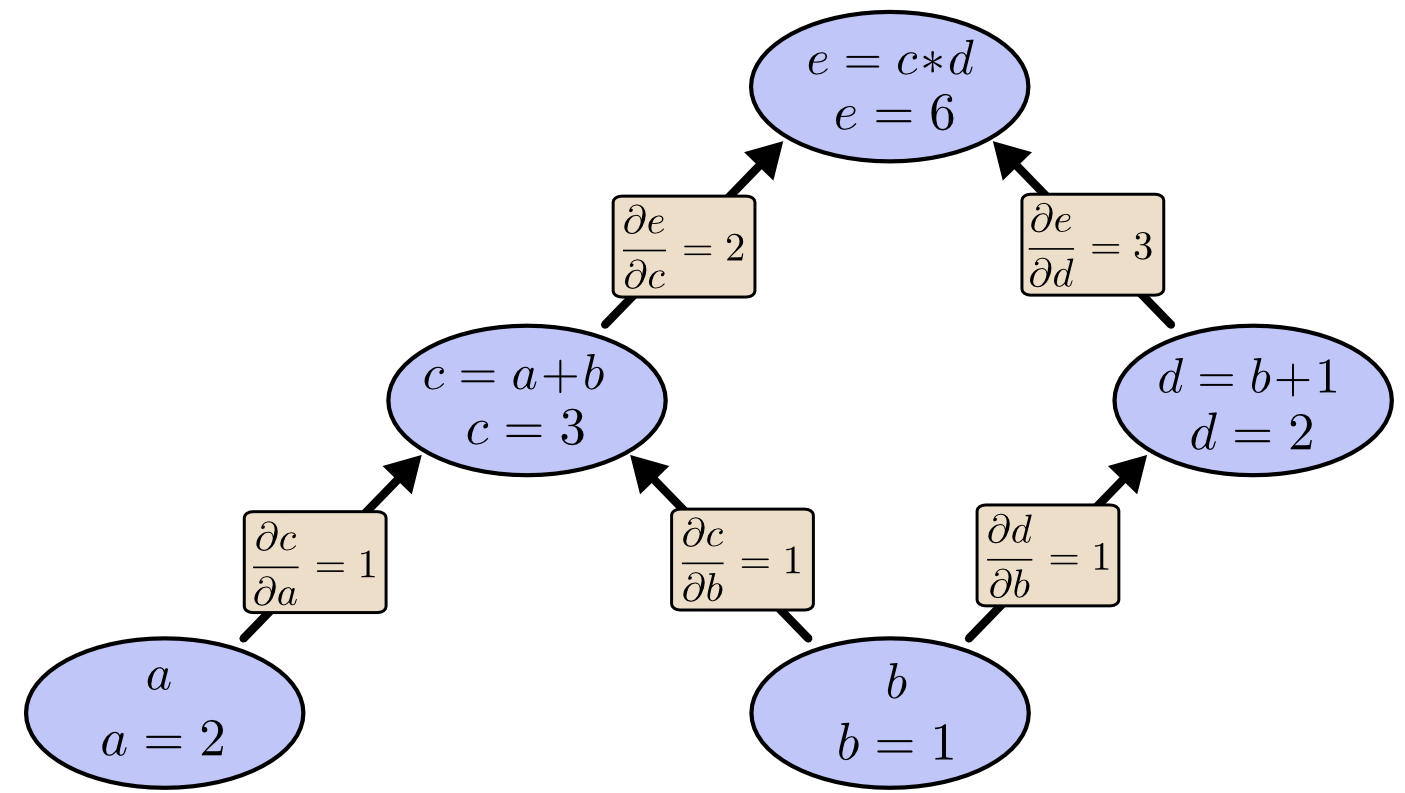
What if we want to understand how nodes that aren’t directly connected affect each other? Let’s consider how e is affected by a. If we change a at a speed of 1, c also changes at a speed of 1. In turn, c changing at a speed of 1 causes e to change at a speed of 2. So e changes at a rate of 1∗2with respect to a.
The general rule is to sum over all possible paths from one node to the other, multiplying the derivatives on each edge of the path together. For example, to get the derivative of e with respect to b we get:
This accounts for how b affects e through c and also how it affects it through d.
This general “sum over paths” rule is just a different way of thinking about the multivariate chain rule.
Factoring Paths
The problem with just “summing over the paths” is that it’s very easy to get a combinatorial explosion in the number of possible paths.
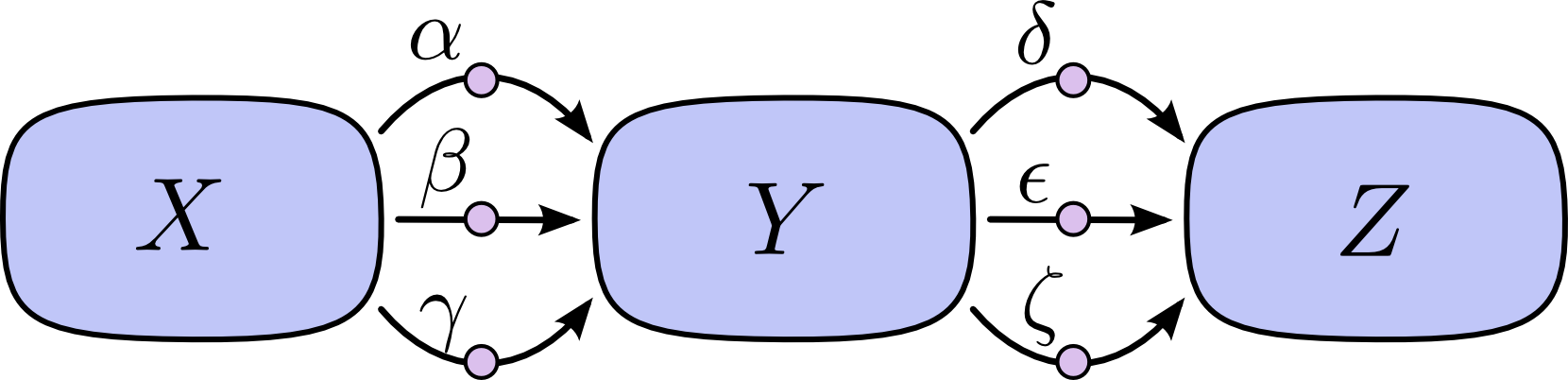
In the above diagram, there are three paths from X to Y, and a further three paths from Y to Z. If we want to get the derivative ∂Z∂X by summing over all paths, we need to sum over 3∗3=9paths:
The above only has nine paths, but it would be easy to have the number of paths to grow exponentially as the graph becomes more complicated.
Instead of just naively summing over the paths, it would be much better to factor them:
This is where “forward-mode differentiation” and “reverse-mode differentiation” come in. They’re algorithms for efficiently computing the sum by factoring the paths. Instead of summing over all of the paths explicitly, they compute the same sum more efficiently by merging paths back together at every node. In fact, both algorithms touch each edge exactly once!
Forward-mode differentiation starts at an input to the graph and moves towards the end. At every node, it sums all the paths feeding in. Each of those paths represents one way in which the input affects that node. By adding them up, we get the total way in which the node is affected by the input, it’s derivative.
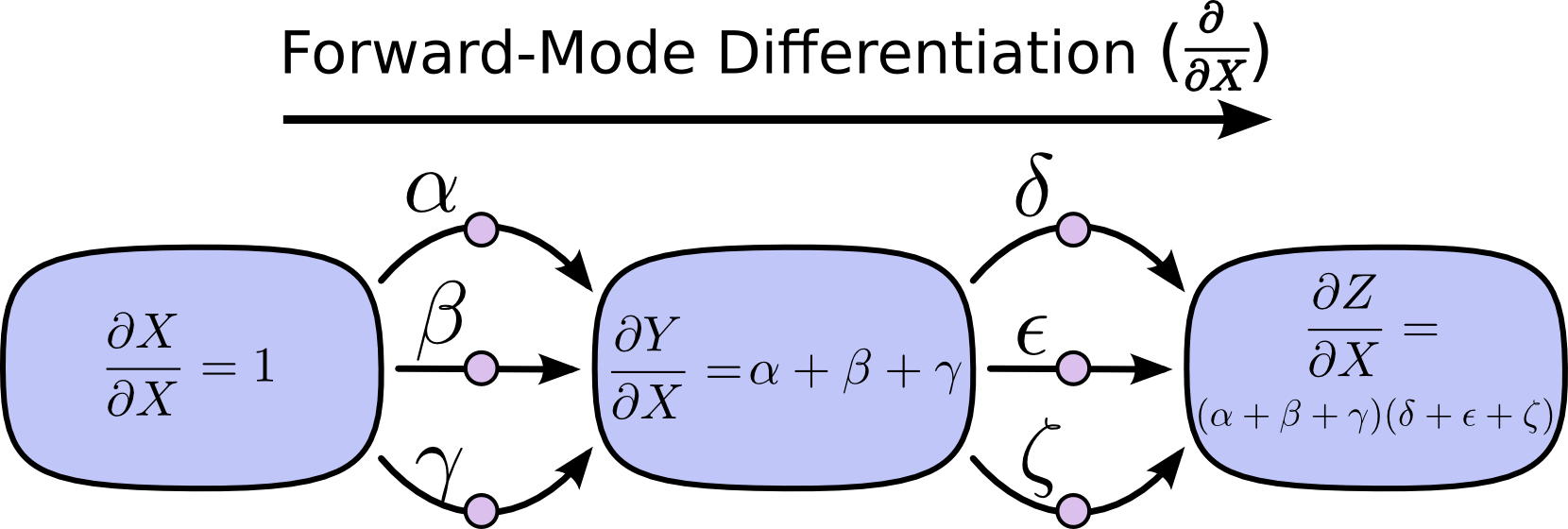
Though you probably didn’t think of it in terms of graphs, forward-mode differentiation is very similar to what you implicitly learned to do if you took an introduction to calculus class.
Reverse-mode differentiation, on the other hand, starts at an output of the graph and moves towards the beginning. At each node, it merges all paths which originated at that node.

Forward-mode differentiation tracks how one input affects every node. Reverse-mode differentiation tracks how every node affects one output. That is, forward-mode differentiation applies the operator ∂∂X to every node, while reverse mode differentiation applies the operator ∂Z∂to every node.1
Computational Victories
At this point, you might wonder why anyone would care about reverse-mode differentiation. It looks like a strange way of doing the same thing as the forward-mode. Is there some advantage?
Let’s consider our original example again:
We can use forward-mode differentiation from b up. This gives us the derivative of every node with respect to b.
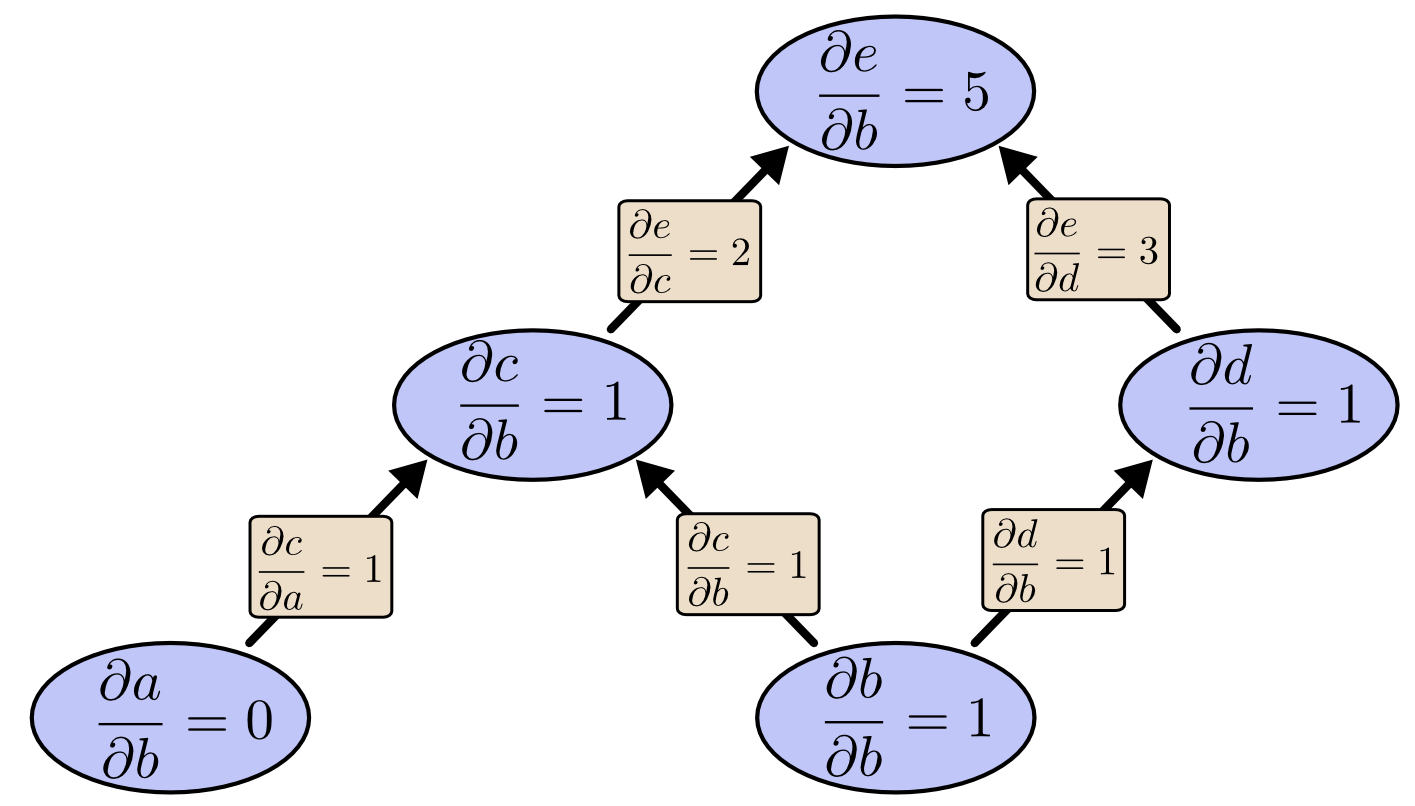
We’ve computed ∂e∂b, the derivative of our output with respect to one of our inputs.
What if we do reverse-mode differentiation from e down? This gives us the derivative of e with respect to every node:
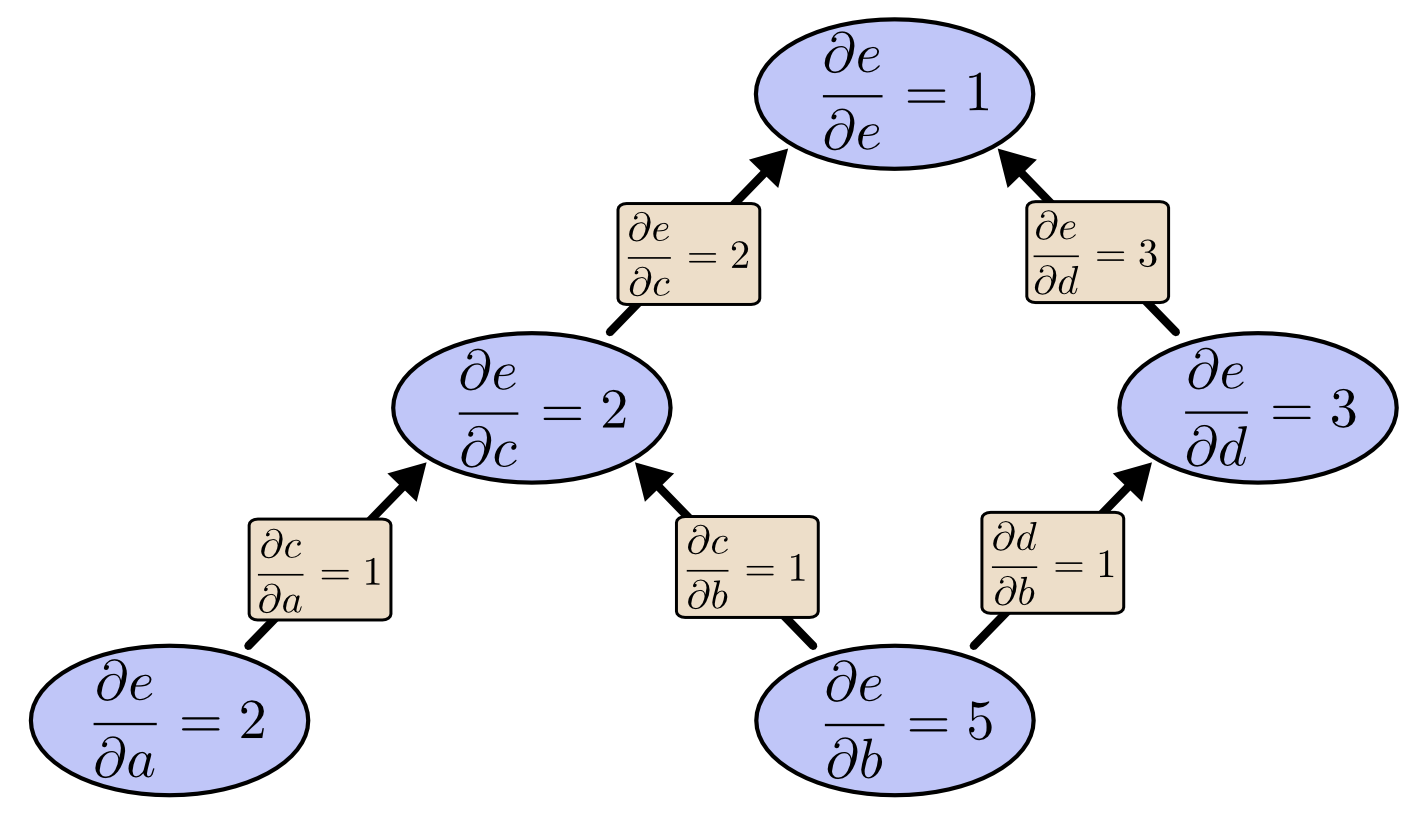
When I say that reverse-mode differentiation gives us the derivative of e with respect to every node, I really do mean every node. We get both ∂e∂a and ∂e∂b, the derivatives of e with respect to both inputs. Forward-mode differentiation gave us the derivative of our output with respect to a single input, but reverse-mode differentiation gives us all of them.
For this graph, that’s only a factor of two speed up, but imagine a function with a million inputs and one output. Forward-mode differentiation would require us to go through the graph a million times to get the derivatives. Reverse-mode differentiation can get them all in one fell swoop! A speed up of a factor of a million is pretty nice!
When training neural networks, we think of the cost (a value describing how bad a neural network performs) as a function of the parameters (numbers describing how the network behaves). We want to calculate the derivatives of the cost with respect to all the parameters, for use in gradient descent. Now, there’s often millions, or even tens of millions of parameters in a neural network. So, reverse-mode differentiation, called backpropagation in the context of neural networks, gives us a massive speed up!
(Are there any cases where forward-mode differentiation makes more sense? Yes, there are! Where the reverse-mode gives the derivatives of one output with respect to all inputs, the forward-mode gives us the derivatives of all outputs with respect to one input. If one has a function with lots of outputs, forward-mode differentiation can be much, much, much faster.)
Isn’t This Trivial?
When I first understood what backpropagation was, my reaction was: “Oh, that’s just the chain rule! How did it take us so long to figure out?” I’m not the only one who’s had that reaction. It’s true that if you ask “is there a smart way to calculate derivatives in feedforward neural networks?” the answer isn’t that difficult.
But I think it was much more difficult than it might seem. You see, at the time backpropagation was invented, people weren’t very focused on the feedforward neural networks that we study. It also wasn’t obvious that derivatives were the right way to train them. Those are only obvious once you realize you can quickly calculate derivatives. There was a circular dependency.
Worse, it would be very easy to write off any piece of the circular dependency as impossible on casual thought. Training neural networks with derivatives? Surely you’d just get stuck in local minima. And obviously it would be expensive to compute all those derivatives. It’s only because we know this approach works that we don’t immediately start listing reasons it’s likely not to.
That’s the benefit of hindsight. Once you’ve framed the question, the hardest work is already done.
Conclusion
Derivatives are cheaper than you think. That’s the main lesson to take away from this post. In fact, they’re unintuitively cheap, and us silly humans have had to repeatedly rediscover this fact. That’s an important thing to understand in deep learning. It’s also a really useful thing to know in other fields, and only more so if it isn’t common knowledge.
Are there other lessons? I think there are.
Backpropagation is also a useful lens for understanding how derivatives flow through a model. This can be extremely helpful in reasoning about why some models are difficult to optimize. The classic example of this is the problem of vanishing gradients in recurrent neural networks.
Finally, I claim there is a broad algorithmic lesson to take away from these techniques. Backpropagation and forward-mode differentiation use a powerful pair of tricks (linearization and dynamic programming) to compute derivatives more efficiently than one might think possible. If you really understand these techniques, you can use them to efficiently calculate several other interesting expressions involving derivatives. We’ll explore this in a later blog post.
This post gives a very abstract treatment of backpropagation. I strongly recommend reading Michael Nielsen’s chapter on it for an excellent discussion, more concretely focused on neural networks.
Acknowledgments
Thank you to Greg Corrado, Jon Shlens, Samy Bengio and Anelia Angelova for taking the time to proofread this post.
Thanks also to Dario Amodei, Michael Nielsen and Yoshua Bengio for discussion of approaches to explaining backpropagation. Also thanks to all those who tolerated me practicing explaining backpropagation in talks and seminar series!
This might feel a bit like dynamic programming. That’s because it is!↩
Calculus on Computational Graphs: Backpropagation的更多相关文章
- (译)Calculus on Computational Graphs: Backpropagation
Posted on August 31, 2015 Introduction Backpropagation is the key algorithm that makes training deep ...
- [TF] Architecture - Computational Graphs
阅读笔记: 仅希望对底层有一定必要的感性认识,包括一些基本核心概念. Here只关注Graph相关,因为对编程有益. TF – Kernels模块部分参见:https://mp.weixin.qq.c ...
- 谷歌大神Jeff Dean:大规模深度学习最新进展 zz
http://www.tuicool.com/articles/MBBbeeQ 在AlphaGo与李世石比赛期间,谷歌天才工程师Jeff Dean在Google Campus汉城校区做了一次关于智能计 ...
- Recurrent Neural Network系列2--利用Python,Theano实现RNN
作者:zhbzz2007 出处:http://www.cnblogs.com/zhbzz2007 欢迎转载,也请保留这段声明.谢谢! 本文翻译自 RECURRENT NEURAL NETWORKS T ...
- Recurrent Neural Network系列3--理解RNN的BPTT算法和梯度消失
作者:zhbzz2007 出处:http://www.cnblogs.com/zhbzz2007 欢迎转载,也请保留这段声明.谢谢! 这是RNN教程的第三部分. 在前面的教程中,我们从头实现了一个循环 ...
- Pytorch 之 backward
首先看这个自动求导的参数: grad_variables:形状与variable一致,对于y.backward(),grad_variables相当于链式法则dz/dx=dz/dy × dy/dx 中 ...
- LSTM与Highway-LSTM算法实现的研究概述
LSTM与Highway-LSTM算法实现的研究概述 zoerywzhou@gmail.com http://www.cnblogs.com/swje/ 作者:Zhouwan 2015-12-22 ...
- What are some good books/papers for learning deep learning?
What's the most effective way to get started with deep learning? 29 Answers Yoshua Bengio, ...
- 本人AI知识体系导航 - AI menu
Relevant Readable Links Name Interesting topic Comment Edwin Chen 非参贝叶斯 徐亦达老板 Dirichlet Process 学习 ...
随机推荐
- Navicat Premium 连接Oracle 数据库
昨天开始工作的时候听同事说:Navicat可以连各种数据库,包括Oracle,头一次听说!!!很是尴尬.现在记录一下怎么用Navicat连接Oracle.最重要的是,Navicat只支持32的Orac ...
- 四则运算结对项目之GUI
本次结对编程让我学到了许多许多知识,受益匪浅!在此之前,我没想过我能做出一个双击运行的小程序. 感谢我的队友与我同心协力,感谢室友宇欣告诉我操作符为“最多多少”而不是“多少”并教我使用效能分析工具,感 ...
- 四则运算截图and代码
1.运行截图 2.代码 #include<stdio.h> #include<stdlib.h> int main() { int i=300; int a=0; while( ...
- Weka平台学习
链接:http://www.cs.waikato.ac.nz/ml/weka/index.html 一简介: WEKA的全名是怀卡托智能分析环境(Waikato Environment for Kno ...
- node入门学习(一)
一.安装node.js 方式很多npm,git等,新手建议从官网上直接去下载node的安装包.一键安装. 二.创建一个web服务器. const http = require('http'); htt ...
- [学习]ulimit
ulimit User limits - limit the use of system-wide resources. Syntax ulimit [-acdfHlmnpsStuv] [limit] ...
- 能把opencv的源码也进行调试吗?(需要pdb文件才行)
能把opencv的源码也进行调试吗?(需要pdb文件才行)1.我是用的Qt Creator,然后"工具\选项\调试器\概要\源码路径映射"中,选择"添加Qt源码" ...
- python 9*9乘法口诀表
# -*- coding: utf-8 -*- # __author__ = 'Carry' for i in range(1, 10): for j in range(1, i + 1): prin ...
- avalon学习教程
最近在项目中发现了个很不错的前端MVVM框架 avalon,对于基础的使用大概学习了一遍,有些深入的没应用场景还没细看. 收藏好,估计以后要用 http://www.html-js.com/artic ...
- ubuntu 16.04 部署 pypy+nginx+uwsgi+django(详细)
1.nginx ...