6-1 如何读写csv数据

>>> from urllib import urlretrieve
>>> urlretrieve('http://table.finance.yahoo.com/table.csv?s=000001.sz',r'C:\视频\python高效实践技巧笔记\6数据编码与处理相关话题\pingan.csv',’pingan.csv’)
Urlretrieve模块第一个参数是url,第二个参数是要将打开的文件保存的文件。
对CSV文件读写使用CSV接口的reader()和writer()函数
因这个网址已经打不开了,所以在网上下载一个CSV文件直接操作
一、打开并读一个csv文件
>>> help(csv.reader)
Help on built-in function reader in module _csv: reader(...)
csv_reader = reader(iterable [, dialect='excel']
[optional keyword args])
for row in csv_reader:
process(row) The "iterable" argument can be any object that returns a line
of input for each iteration, such as a file object or a list. The
optional "dialect" parameter is discussed below. The function
also accepts optional keyword arguments which override settings
provided by the dialect. The returned object is an iterator. Each iteration returns a row
of the CSV file (which can span multiple input lines).
help(csv.reader)
参数是一个打开文件的文件对象,返回的是一个迭代器。
>>> import csv
>>>
>>> rf = open(r"C:\视频\python高效实践技巧笔记\6数据编码与处理相关话题\bank-data.csv",'rb') #注意打开csv文件需要使用二进制打开方式
>>> reader = csv.reader(rf)
>>> reader.next() #csv.reader()返回的是迭代器,查看需要使用next()方法
['id', 'age', 'sex', 'region', 'income', 'married', 'children', 'car', 'save_act', 'current_act', 'mortgage', 'pep']
>>> reader.next()
['ID12101', '', 'FEMALE', 'INNER_CITY', '17546.0', 'NO', '', 'NO', 'NO', 'NO', 'NO', 'YES']

查看reader()返回迭代对象的方法
>>> help(reader)
Help on reader object: class reader(__builtin__.object)
| CSV reader
|
| Reader objects are responsible for reading and parsing tabular data
| in CSV format.
|
| Methods defined here:
|
| __iter__(...)
| x.__iter__() <==> iter(x)
|
| next(...)
| x.next() -> the next value, or raise StopIteration
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| dialect
|
| line_num
help(reader)
二、打开并写一个文件
>>> writer = csv.writer(wf)
>>> help(csv.writer)
Help on built-in function writer in module _csv: writer(...)
csv_writer = csv.writer(fileobj [, dialect='excel']
[optional keyword args])
for row in sequence:
csv_writer.writerow(row) [or] csv_writer = csv.writer(fileobj [, dialect='excel']
[optional keyword args])
csv_writer.writerows(rows) The "fileobj" argument can be any object that supports the file API.
help(csv.writer)
同reader()一样,参数是一个打开文件的对象,返回值是一个迭代器,打开文件的方式 需要使用二进制方式
>>> wf = open(r'C:\视频\python高效实践技巧笔记\6数据编码与处理相关话题\bank-databak.csv','wb')
>>> writer = csv.writer(wf)
>>> writer.writerow(['id', 'age', 'sex', 'region', 'income', 'married', 'children', 'car', 'save_act', 'current_act', 'mortgage', 'pep'])
>>> writer.writerow(reader.next())
>>> writer.writerow(reader.next())
>>> wf.flush() #和c语言的flush()作用相同,及时将文件缓冲区内容输出到文件上。

查看writer()返回的迭代器的方法主要是writerow()写行
>>> help(writer)
Help on writer object: class writer(__builtin__.object)
| CSV writer
|
| Writer objects are responsible for generating tabular data
| in CSV format from sequence input.
|
| Methods defined here:
|
| writerow(...)
| writerow(sequence)
|
| Construct and write a CSV record from a sequence of fields. Non-string
| elements will be converted to string.
|
| writerows(...)
| writerows(sequence of sequences)
|
| Construct and write a series of sequences to a csv file. Non-string
| elements will be converted to string.
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| dialect
help(writer)
Bank-data.csv是一份收入情况,现编写脚本,将文件中年龄在30-40之间,收入大于10000的另存到一个bank-databak.csv文件中.现编写脚本如下:
# -*- coding: cp936 -*-
import csv
with open(r'C:\视频\python高效实践技巧笔记\6数据编码与处理相关话题\bank-data.csv','rb') as rf:
reader = csv.reader(rf)
with open(r'C:\视频\python高效实践技巧笔记\6数据编码与处理相关话题\bank-databak.csv','wb') as wf:
writer = csv.writer(wf)
header = reader.next() #将文件的头读出
writer.writerow(header) #将文件的头写入文件 for row in reader: #迭代执行判断,文件中第一个字段代表age第4个字段代表收入
#文件中读出的是字符,所以在比较时要将字符转成int或float.
#python中判断数字区间可以用数学中的表达方式,与C语言不同.
if (30< int(row[1])<40 and float(row[4])>10000.0):
writer.writerow(row) #将合适的数据写入新的csv文件中
print("end")
结果:

Ps:
注意字符串日期的比较的大小比较也可以使用如下红框的方式,、
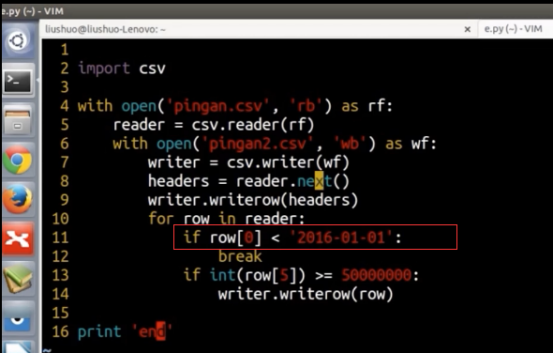
6-1 如何读写csv数据的更多相关文章
- python_如何读写csv数据
案例: 通过股票网站,我们获取了中国股市数据集,它以csv数据格式存储 Data,Open,High,Low,Close,Volume,Adj Close 2016-06-28,8.63,8.47,8 ...
- 使用Python读写csv文件的三种方法
Python读写csv文件 觉得有用的话,欢迎一起讨论相互学习~Follow Me 前言 逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是 ...
- python读写csv文件
文章链接:https://www.cnblogs.com/cloud-ken/p/8432999.html Python读写csv文件 觉得有用的话,欢迎一起讨论相互学习~Follow Me 前言 逗 ...
- 利用java反射读写csv中的数据
前一段有个需求需要将从数据库读取到的信息保存到csv文件中,在实现该需求的时候发现资料比较少,经过收集反射和csv相关资料,最终得到了如下程序. 1.在使用java反射读取csv文件数据时,先通 ...
- 支持各种特殊字符的 CSV 解析类 (.net 实现)(C#读写CSV文件)
CSV是一种十分简洁的数据结构,在DOTNET平台实际使用中发现微软官方并没有提供默认的方法,而网上好多例子发现实现并不严谨甚至一些含有明显错误,所以后面自己实现了一个读写工具类,这里发出来希望方便后 ...
- python3读写csv文件
python读取CSV文件 python中有一个读写csv文件的包,直接import csv即可.利用这个python包可以很方便对csv文件进行操作,一些简单的用法如下. 1. 读文件 csv_ ...
- MATLAB中文件的读写和数据的导入导出
http://blog.163.com/tawney_daylily/blog/static/13614643620111117853933/ 在编写一个程序时,经常需要从外部读入数据,或者将程序运行 ...
- python3使用csv包,读写csv文件
python操作csv,现在很多都用pandas包了,不过python还是有一个原始的包可以直接操作csv,或者excel的,下面举个例子说明csv读写csv文件的方法: import os impo ...
- 使用Spark读写CSV格式文件(转)
原文链接:使用Spark读写CSV格式文件 CSV格式的文件也称为逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号.在本文中的CSV格 ...
随机推荐
- Codeforces 919E Congruence Equation ( 数论 && 费马小定理 )
题意 : 给出数 x (1 ≤ x ≤ 10^12 ),要求求出所有满足 1 ≤ n ≤ x 的 n 有多少个是满足 n*a^n = b ( mod p ) 分析 : 首先 x 的范围太大了,所以使 ...
- (46)LINUX应用编程和网络编程之一Linux应用编程框架
3.1.1.应用编程框架介绍 3.1.1.1.什么是应用编程 (1)整个嵌入式linux核心课程包括5个点,按照学习顺序依次是:裸机.C高级.uboot和系统移植.linux应用编程和网络编程.驱动. ...
- Codeforces Round #403---C题(DFS,树)
C. Andryusha and Colored Balloons time limit per test 2 seconds memory limit per test 256 megabytes ...
- mysql执行拉链表操作
拉链表需求: 1.数据量比较大 2.变化的比例和频率比较小,例如客户的住址信息,联系方式等,比如有1千万的用户数据,每天全量存储会存储很多不变的信息,对存储也是浪费,因此可以使用拉链表的算法来节省存储 ...
- leetcode206 反转链表 两种做法(循环,递归)
反转链表 leetcode206 方法1 循环 public ListNode reverseList(ListNode head) { if (head == null || head.next = ...
- ES6数组的拓展
扩展运算符 扩展运算符(spread)是三个点(...).它好比 rest 参数的逆运算,将一个数组转为用逗号分隔的参数序列. console.log(...[1, 2, 3]) // 1 2 3 c ...
- python-接口开发flask模块(三)开发登陆接口
#写一个login的接口,实现的功能是输入用户名和密码,如果数据库中有该用户,那么就去redis中插入 登陆产生的sign值插入redis中有效时间600s import flask import t ...
- Linux_Samba详解
目录 目录 Samba Server Parameter Configuration file explain Setup the Samba Server Access the samba shar ...
- sql语句exists 用法
参考:SQL语句exists用法,Sql语句中IN和exists的区别及应用 现在有三张表 学生表S: sno ,sname 课程表C:cno ,cname 学生选课表SC: sno ,cno 查询选 ...
- framework7 底部弹层popup js关闭方法
<div class="u-sd-btns"> <button>同意</button> <button class="popup ...