node.js爬虫
这是一个简单的node.js爬虫项目,麻雀虽小五脏俱全。
本项目主要包含一下技术:
发送http抓取页面(http)、分析页面(cheerio)、中文乱码处理(bufferhelper)、异步并发流程控制(thenjs)
1、为什么选择http模块来发送Http请求下载页面
社区有很多封装好的Http请求模块,例如:request、needle、node-rest-client等,http有这些模块比拟不了的优势,可以监听抓取的字节流,我们知道要抓取的页面一般会含有汉字,一个汉字是3个字节(也有说4个字节),笔者在node中测试的是3个字节,一个英文字母是1个字节(见下图),node对中文的支持是不友好的,所以就需要借助bufferhelper来解决字节流问题,再使用 iconv-lite模块把buffer转化成utf8格式。

2、使用cheerio分析Html,让你感觉就像是在使用JQuery
3、虽说如今node上已经有异步控制的标准 async/await,但是thenjs,真的很好用,并且效率也不错,本项目主要用了它的异步并行控制 Then.each,了解更多thenjs介绍
4、本项目主要是抓取菜鸟教程的 HTML/CSS 下的8个页面,本项目先抓取 http://www.runoob.com 分析其Html,找到这8个页面的Url,再分别抓取这些页面的Html,写入到本地文件
代码 chong.js :
var http = require('http');
var Then = require('thenjs');
var BufferHelper = require('bufferhelper');
var fs = require('fs');
var cheerio = require('cheerio'); // Html分析模块
var iconv = require('iconv-lite'); // 字符转码模块
var pageUrl = []; //Url集合
var pagesHtml = []; //所有Url获取的Html的集合
var baseUrl = 'http://www.runoob.com';
main();
function main() {
console.log('Start');
Then(cont => {
grabPageAsync(baseUrl, cont)
}).then((cont, html) => {
var $ = cheerio.load(html);
var $html = $('.codelist.codelist-desktop.cate1');
var $aArr = $html.find('a');
$aArr.each((i, u) => {
pageUrl.push('http:' + $(u).attr('href'));
})
everyPage(cont);
}).fin((cont, error, result) => {
console.log(error ? error : JSON.stringify(result));
console.log('End');
})
}
//爬去每个Url
function everyPage(callback) {
Then.each(pageUrl, (cont, item) => {
grabPageAsync(item, cont);
}).then((cont, args) => {
pagesHtml = args;
createHtml(cont);
}).fin((cont, error, result) => {
callback(error, result);
})
}
//创建Html文件
function createHtml(callback) {
Then.each(pagesHtml, (cont, item, index) => {
var name = pageUrl[index].substr(pageUrl[index].lastIndexOf('/') + 1);
fs.writeFile(__dirname + '/grapHtml/' + name, item, function(err) {
err ? console.error(err) : console.log('写入成功:' + name);
cont(err, index);
});
}).fin((cont, error, result) => {
callback(error, result);
})
}
// 异步爬取页面HTML
function grabPageAsync(url, callback) {
http.get(url, function(res) {
var bufferHelper = new BufferHelper();
res.on('data', function(chunk) {
bufferHelper.concat(chunk);
});
res.on('end', function() {
console.log('爬取 ' + url + ' 成功');
var fullBuffer = bufferHelper.toBuffer();
var utf8Buffer = iconv.decode(fullBuffer, 'UTF-8');
var html = utf8Buffer.toString()
callback(null, html);
});
}).on('error', function(e) {
// 爬取成功
callback(e, null);
console.log('爬取 ' + url + ' 失败');
});
}
运行:
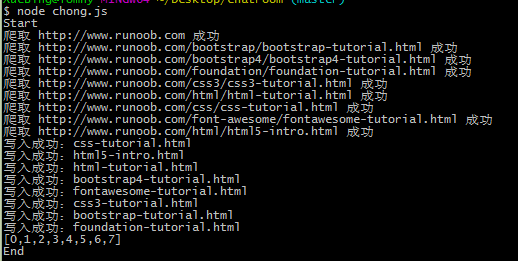
抓取的页面结果:

欢迎拍砖 :)
本文原创转载请注明出处!
node.js爬虫的更多相关文章
- Node.js爬虫-爬取慕课网课程信息
第一次学习Node.js爬虫,所以这时一个简单的爬虫,Node.js的好处就是可以并发的执行 这个爬虫主要就是获取慕课网的课程信息,并把获得的信息存储到一个文件中,其中要用到cheerio库,它可以让 ...
- Node.js aitaotu图片批量下载Node.js爬虫1.00版
即使是https网页,解析的方式也不是一致的,需要多试试. 代码: //====================================================== // aitaot ...
- Node.js umei图片批量下载Node.js爬虫1.00
这个爬虫在abaike爬虫的基础上改改图片路径和下一页路径就出来了,代码如下: //====================================================== // ...
- Node.js abaike图片批量下载Node.js爬虫1.01版
//====================================================== // abaike图片批量下载Node.js爬虫1.01 // 1.01 修正了输出目 ...
- Node.js abaike图片批量下载Node.js爬虫1.00版
这个与前作的差别在于地址的不规律性,需要找到下一页的地址再爬过去找. //====================================================== // abaik ...
- Node JS爬虫:爬取瀑布流网页高清图
原文链接:Node JS爬虫:爬取瀑布流网页高清图 静态为主的网页往往用get方法就能获取页面所有内容.动态网页即异步请求数据的网页则需要用浏览器加载完成后再进行抓取.本文介绍了如何连续爬取瀑布流网页 ...
- Node.js 爬虫爬取电影信息
Node.js 爬虫爬取电影信息 我的CSDN地址:https://blog.csdn.net/weixin_45580251/article/details/107669713 爬取的是1905电影 ...
- Node.js 爬虫初探
前言 在学习慕课网视频和Cnode新手入门接触到爬虫,说是爬虫初探,其实并没有用到爬虫相关第三方类库,主要用了node.js基础模块http.网页分析工具cherrio. 使用http直接获取url路 ...
- Node.js 爬虫,自动化抓取文章标题和正文
持续进行中... 目标: 动态User-Agent模拟浏览器 √ 支持Proxy设置,避免被服务器端拒绝 √ 支持多核模式,发挥多核CPU性能 √ 支持核内并发模式 √ 自动解码非英文站点,避免乱码出 ...
随机推荐
- OpenCV4Android背景建模(MOG、MOG2)
本文为作者原创,转载请注明出处(http://www.cnblogs.com/mar-q/)by 负赑屃 很久以前的笔记了,分享给大家吧...OpenCV4Android中用于背景建模的类主要 ...
- vuex的简易入门
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 12.0px "Helvetica Neue"; color: #454545 } p. ...
- 基于HTML5及WebGL的工控SCADA模拟飞机飞行
昨天看到一篇文章说是学习如何开飞机的,然后我就想,如果我也可以开飞机那就好玩了,每个人小时候都想做飞行员!中国飞行员太难当了,再说也不轻易让你开飞机!后来我就想如果能用 HT 开飞机那就是真的有趣了, ...
- 写了一个bug,最后却变成了feature,要不要修呢?
事情是这样子的,前不久接到一个需求,为一个游戏开发礼包码功能 通常一款游戏运营期间会搞各种各样的活动吸引玩家,其中最常见的就是发放礼包, 玩家可以通过礼包码兑换礼包. 用礼包码兑换礼包有个一限制,游 ...
- gulp-prompt入个了门
gulp-prompt版本:0.4.1 源码:gulp-prompt 一.gulp-prompt的简介 gulp-prompt 是一个基于gulp的命令行提示. 我们可以用它来完成命令行中互动功能. ...
- Javaweb项目开发的前后端解耦的必要性
JavaWeb项目为何我们要放弃jsp?为何要前后端解耦?为何要动静分离? 使用jsp的痛点: 1.jsp上动态资源和静态资源全部耦合在一起,服务器压力大,因为服务器会收到各种静态资源的http请求, ...
- ASP.NET Core的身份认证框架IdentityServer4(4)- 支持的规范
IdentityServer实现以下规范: OpenID Connect OpenID Connect Core 1.0 (spec) OpenID Connect Discovery 1.0 (sp ...
- git使用教程之了解git
1.理解git快照 快照的作用就相当于将旧文件所占的空间保留下来,并且保存一个引用,而新文件中会继续使用与旧文件内容相同部分的磁盘空间,不同部分则写入新的磁盘空间.git有一个HEAD指针,这个指针可 ...
- display:none和visibility:hidden区别
<!-- display:none和visible:hidden都能把网页上某个元素隐藏起来,但两者有区别: --> <!-- display:none 不为被隐藏的对象保留其物理空 ...
- jQuery选择器(添加节点及删除节点及克隆及替换及包装)第九节
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...