Hadoop(三)手把手教你搭建Hadoop全分布式集群
前言
上一篇介绍了伪分布式集群的搭建,其实在我们的生产环境中我们肯定不是使用只有一台服务器的伪分布式集群当中的。接下来我将给大家分享一下全分布式集群的搭建!
其实搭建最基本的全分布式集群和伪分布式集群基本没有什么区别,只有很小的区别。
一、搭建Hadoop全分布式集群前提
1.1、网络
1)如果是在一台虚拟机中安装多个linux操作系统的话,可以使用NAT或桥接模式都是可以的。试一试可不可以相互ping通!
2)如果在一个局域网当中,自己的多台电脑(每台电脑安装相同版本的linux系统)搭建,将所要使用的Ubuntu操作系统的网络模式调整为桥接模式。
步骤:
一是:在要使用的虚拟机的标签上右键单击,选择设置,选择网络适配器,选择桥接模式,确定
二是:设置完成之后,重启一下虚拟机
三是:再设置桥接之前将固定的IP取消
桌面版:通过图形化界面设置的。
服务器版:在/etc/network/interfaces
iface ens33 inet dhcp
#address ...
四是:ifconfig获取IP。172.16.21.xxx
最后试一试能不能ping通
1.2、安装jdk
每一个要搭建集群的服务器都需要安装jdk,这里就不介绍了,可以查看上一篇
1.3、安装hadoop
每一个要搭建集群的服务器都需要安装hadoop,这里就不介绍了,可以查看上一篇。
二、Hadoop全分布式集群搭建的配置
配置/opt/hadoop/etc/hadoop相关文件

2.1、hadoop-env.sh
25行左右:export JAVA_HOME=${JAVA_HOME}
改成:export JAVA_HOME=/opt/jdk
2.2、core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mip:9000</value>
</property>
</configuration>
分析:
mip:在主节点的mip就是自己的ip,而所有从节点的mip是主节点的ip。
9000:主节点和从节点配置的端口都是9000
2.3、hdfs-site.xml
注意:**:下面配置了几个目录。需要将/data目录使用-R给权限为777。
<configuration>
<property>
<name>dfs.nameservices</name>
<value>hadoop-cluster</value>
</property>
<property>
<name>dfs.replication</name>
<value></value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///data/hadoop/hdfs/nn</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///data/hadoop/hdfs/snn</value>
</property>
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:///data/hadoop/hdfs/snn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///data/hadoop/hdfs/dn</value>
</property>
</configuration>
分析:
dfs.nameservices:在一个全分布式集群大众集群当中这个的value要相同
dfs.replication:因为hadoop是具有可靠性的,它会备份多个文本,这里value就是指备份的数量(小于等于从节点的数量)
一个问题:
dfs.datanode.data.dir:这里我在配置的时候遇到一个问题,就是当使用的这个的时候从节点起不来。当改成fs.datanode.data.dir就有用了。
但是官方给出的文档确实就是这个呀!所以很邪乎。因为只有2.0版本之前是fs
2.4.mapred-site.xml
注意:如果在刚解压之后,是没有这个文件的,需要将mapred-site.xml.template复制为mapred-site.xml。
<configuration>
<property>
<!-指定Mapreduce运行在yarn上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2.5、yarn-site.xml
<configuration>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>mip</value>
</property>
<!-- 指定reducer获取数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>file:///data/hadoop/yarn/nm</value>
</property>
分析:
mip:在主节点的mip就是自己的ip,而所有从节点的mip是主节点的ip。
2.6、创建上面配置的目录
sudo mkdir -p /data/hadoop/hdfs/nn
sudo mkdir -p /data/hadoop/hdfs/dn
sudo mkdir -p /data/hadoop/hdfs/snn
sudo mkdir -p /data/hadoop/yarn/nm
一定要设置成:sudo chmod -R 777 /data
三、全分布式集群搭建测试
3.1、运行环境
有三台ubuntu服务器(ubuntu 17.04):
主机名:udzyh1 IP:1.0.0.5 作为主节点(名字节点)
主机名:server1 IP:1.0.0.3 作为从节点(数据节点)
主机名:udzyh2 IP:1.0.0.7 作为从节点(数据节点)
jdk1.8.0_131
hadoop 2.8.1
3.2、服务器集群的启动与关闭

名字节点、资源管理器:这是在主节点中启动或关闭的。
数据节点、节点管理器:这是在从节点中启动或关闭的。
MR作业日志管理器:这是在主节点中启动或关闭的。
3.3、效果
在主节点:udzyh1中
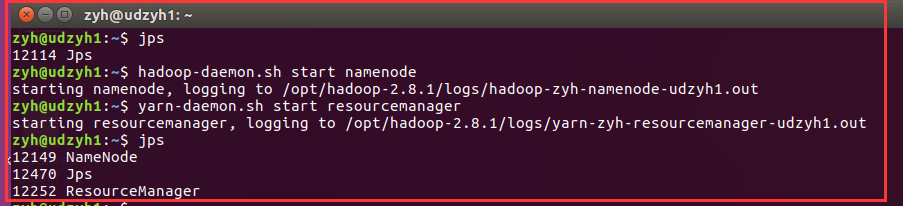
在从节点:server1中
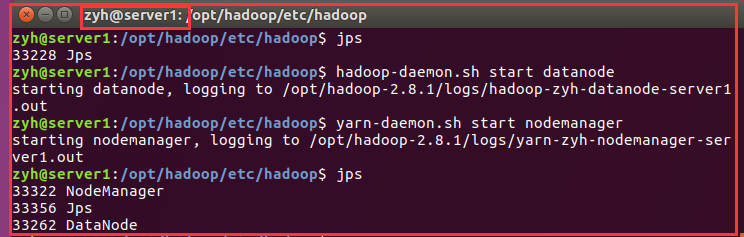
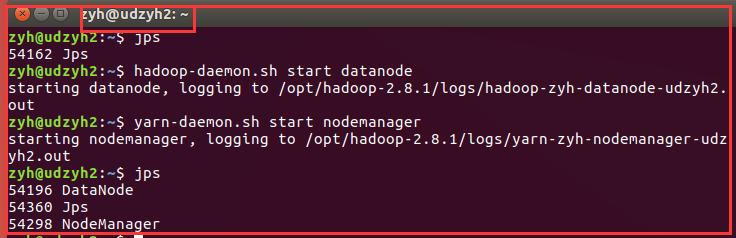
在从节点:udzyh2中
我们在主节点的web控制页面中:http:1.0.0.5:50070中查看到两个从节点
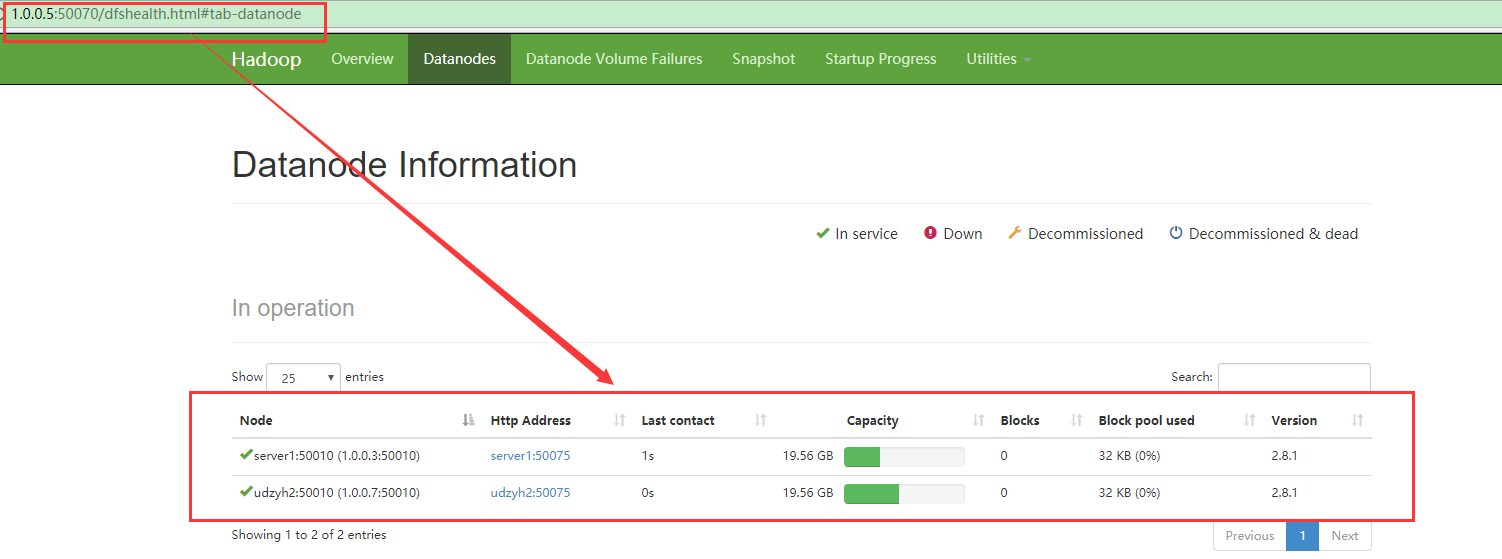
说明配置成功
3.4、监控平台

四、Hadoop全分布式集群配置免密登录实现主节点控制从节点
配置这个是为了实现主节点管理(开启和关闭)从节点的功能:

我们只需要在主节点中使用start-dfs.sh/stop-dfs.sh就能开启或关闭namenode和所有的datanode,使用start-yarn.sh/stop-yarn.sh就能开启或关闭resourcemanager和所有的nodemanager。
4.1、配置主从节点之间的免密登录
1)在所有的主从节点中执行
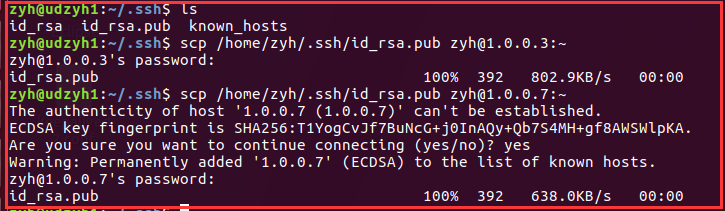
3)在所有的从节点中执行

在从节点1.0.0.7
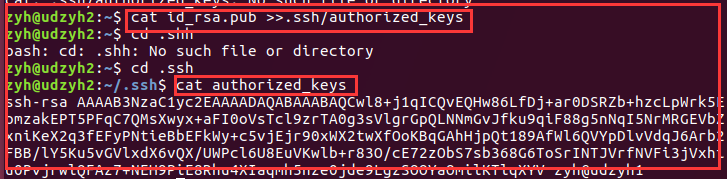
4)测试

我们可以查看他们是用户名相同的,所以可以直接使用ssh 1.0.0.3远程连接
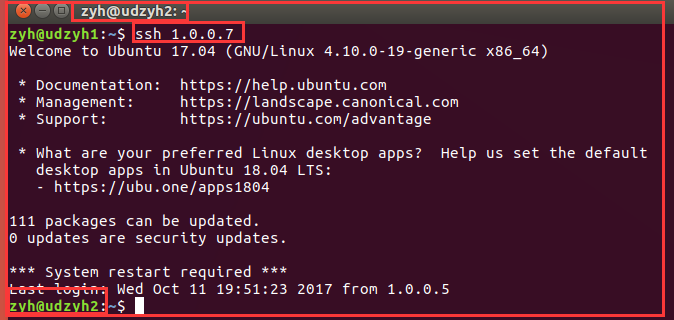
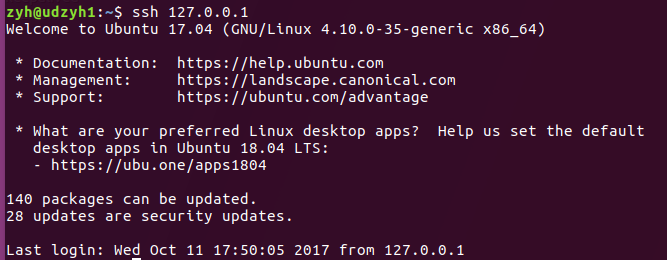
4.2、实现主节点控制从节点
1)在主节点中
打开vi /opt/hadoop/etc/hadoop/slaves

4.3、测试实现主节点控制从节点
1)在主节点的服务器中执行start-dfs.sh

2)在web监控平台查询
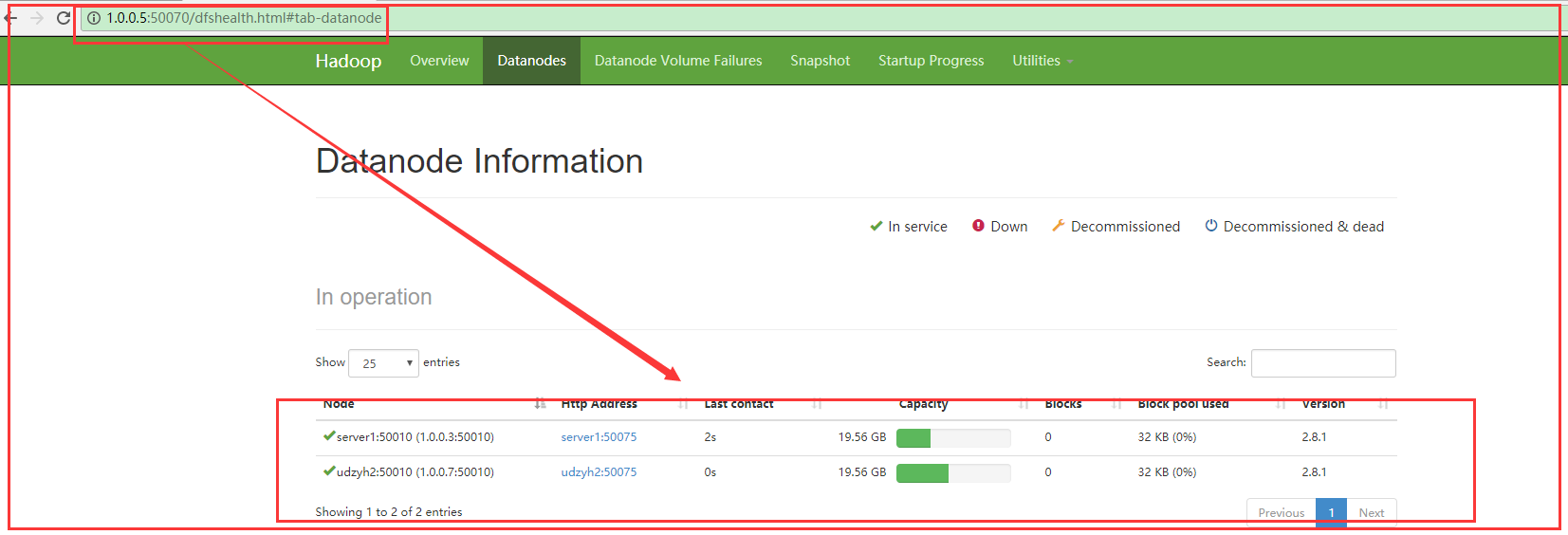
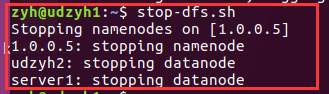
3)在主节点的服务器中执行stop-dfs.sh
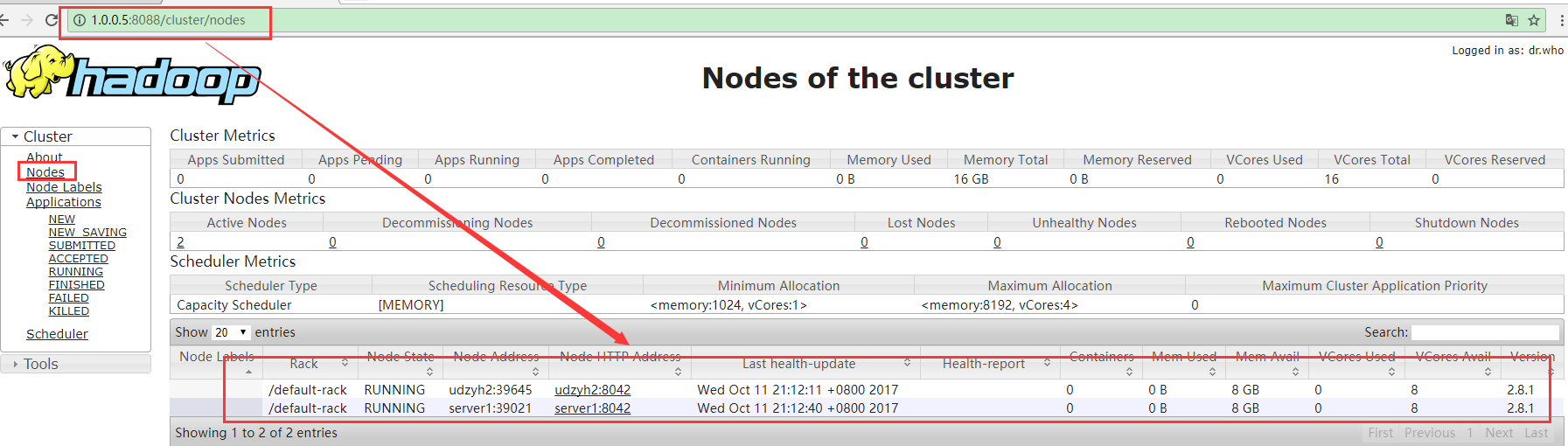
3)在主节点的服务器中执行start-yarn.sh

4)在web监控平台查询到
5)在主节点的服务器中执行stop-yarn.sh

五、配置集群中遇到的问题
2)主节点和从节点启动了,但是在主节点的web控制页面查找不到从节点(linux系统安装在不同的物理机上面)
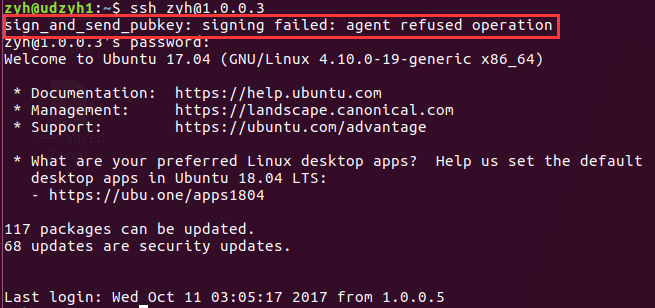
解决方案:
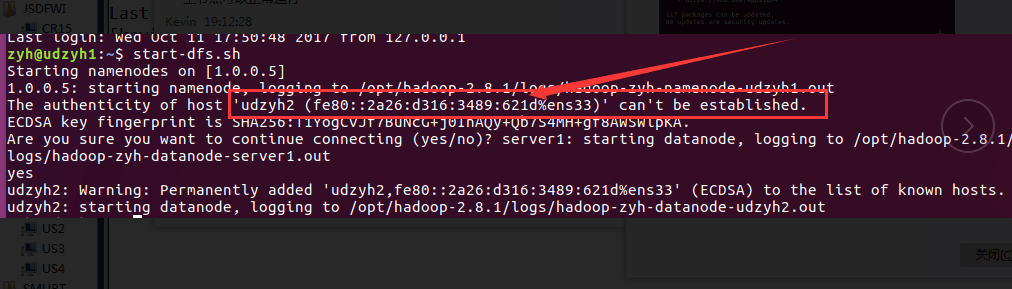
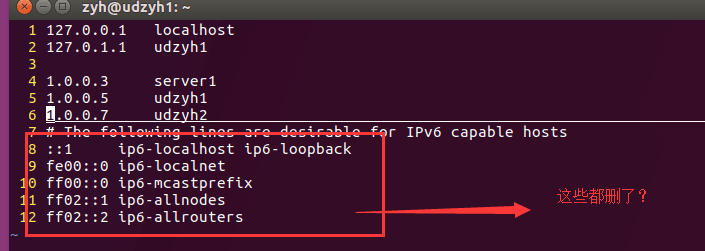
它不能建立IPv6的连接,所以删除了IPv6之后系统会使用IPv4(在主节点上添加从节点的标识的)
4)在主节点的web控制页面查询不到从节点信息(但是使用jps可以查询到)
喜欢就点个“推荐”哦!
Hadoop(三)手把手教你搭建Hadoop全分布式集群的更多相关文章
- Hadoop(三)搭建Hadoop全分布式集群
原文地址:http://www.cnblogs.com/zhangyinhua/p/7652686.html 阅读目录(Content) 一.搭建Hadoop全分布式集群前提 1.1.网络 1.2.安 ...
- 基于HBase0.98.13搭建HBase HA分布式集群
在hadoop2.6.0分布式集群上搭建hbase ha分布式集群.搭建hadoop2.6.0分布式集群,请参考“基于hadoop2.6.0搭建5个节点的分布式集群”.下面我们开始啦 1.规划 1.主 ...
- 【web】 亿级Web系统搭建——单机到分布式集群
当一个Web系统从日访问量10万逐步增长到1000万,甚至超过1亿的过程中,Web系统承受的压力会越来越大,在这个过程中,我们会遇到很多的问题.为了解决这些性能压力带来问题,我们需要在Web系统架 ...
- CentOS中搭建Redis伪分布式集群【转】
解压redis 先到官网https://redis.io/下载redis安装包,然后在CentOS操作系统中解压该安装包: tar -zxvf redis-3.2.9.tar.gz 编译redis c ...
- 使用Cloudera Manager搭建HDFS完全分布式集群
使用Cloudera Manager搭建HDFS完全分布式集群 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 关于Cloudera Manager的搭建我这里就不再赘述了,可以参考 ...
- Redis集群搭建,伪分布式集群,即一台服务器6个redis节点
Redis集群搭建,伪分布式集群,即一台服务器6个redis节点 一.Redis Cluster(Redis集群)简介 集群搭建需要的环境 二.搭建集群 2.1Redis的安装 2.2搭建6台redi ...
- hadoop学习笔记(六):hadoop全分布式集群的环境搭建
本文原创,如需转载,请注明作者以及原文链接! 一.前期准备: 1.jdk安装 不要用centos7自带的openJDK2.hostname 配置 配置位置:/etc/s ...
- Hadoop学习之路(十二)分布式集群中HDFS系统的各种角色
NameNode 学习目标 理解 namenode 的工作机制尤其是元数据管理机制,以增强对 HDFS 工作原理的 理解,及培养 hadoop 集群运营中“性能调优”.“namenode”故障问题的分 ...
- HBase篇--搭建HBase完全分布式集群
一.前述. 完全分布式基于hadoop集群和Zookeeper集群.所以在搭建之前保证hadoop集群和Zookeeper集群可用.可参考本人博客地址 https://www.cnblogs.com/ ...
随机推荐
- Angular中Constructor 和 ngOnInit 的本质区别
在Medium看到一篇Angular的文章,深入对比了 Constructor 和 ngOnInit 的不同,受益匪浅,于是搬过来让更多的前端小伙伴看到,翻译不得当之处还请斧正. 本文出处:The e ...
- 深入剖析ConcurrentHashMap二
详见:http://blog.yemou.net/article/query/info/tytfjhfascvhzxcyt200 我们关注的操作有:get,put,remove 这3个操作.对于哈希表 ...
- spring boot认识
Spring Boot的好处: 1.配置简化 2.配合各种starter使用,基本上可以做到自动化配置 3.上手速度快 4.提供运行时的应用监控 运用IDEA创建spring boot项目请查看: h ...
- django源码解析一(请求处理流程)
1.我们都知道WSGI是一个规范,规范了server和application之间通信的一些约束,server端在监听到请求之后,会把请求转给application去处理,他们之间关联起来的桥梁是一个e ...
- Day-12: 进程和线程
进程和线程 在操作系统看来,一个任务就是一个进程,而一个进程内部如果要做多个任务就是有多个线程.一个进程至少有一个线程. 真正的并行执行任务是由多个CUP分别执行任务,实际中是由,操作系统轮流让各个任 ...
- webpack配置这一篇就够
最近看了一篇好文,根据这个文章重新梳理了一遍webpack打包过程,以前的一些问题也都清楚了,在这里分享一下,同时自己也做了一些小的调整 原文链接:http://www.jianshu.com/p/4 ...
- JS学习四(BOM DOM)
BOM Screen对象 console.log(window.width);//屏幕宽度 console.log(window.height);//屏幕高度 conso ...
- 作业2——需求分析&原型设计
需求分析: 软件的最终目的是用来解决用户的某些问题,需求分析就是要理解要解决的问题,真正明确用户需求.下面是我们初步的需求分析: 1.访问软件项目的真实用户(至少10个),确保软件真正体现用户的需求, ...
- 201521123097 《JAVA程序设计》第七周学习总结
1. 本周学习总结 总结 2. 书面作业 1.ArrayList代码分析 1.1 解释ArrayList的contains源代码 源代码: public boolean contains(Object ...
- 201521123033《Java程序设计》第4周学习总结
1. 本周学习总结 1.1 尝试使用思维导图总结有关继承的知识点. answer: 1.2 使用常规方法总结其他上课内容. answer:学了继承以及各种关键字 2. 书面作业 1.注释的应用 使用类 ...