CentOS7下搭建hadoop2.7.3完全分布式
这里搭建的是3个节点的完全分布式,即1个nameNode,2个dataNode,分别如下:
CentOS-master nameNode 192.168.11.128
CentOS-node1 dataNode 192.168.11.131
CentOS-node2 dataNode 192.168..11.132
1.首先创建好一个CentOS虚拟机,将它作为主节点我这里起名为CentOS-master,起什么都行,不固定要求

2.VMware中打开虚拟机,输入java -version,检查是否有JDK环境,不要用系统自带的openJDK版本,要自己安装的版本

3.输入 systemctl status firewalld.service ,若如图,防火墙处于running状态,则执行第4和第5步,否则直接进入第6步
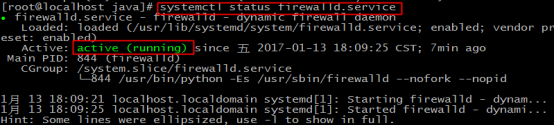
4.输入 systemctl stop firewalld.service ,关闭防火墙

5.输入 systemctl disable firewalld.service ,禁用防火墙

6.输入 mkdir /usr/local/hadoop 创建一个hadoop的文件夹

7.将hadoop的tar包放到刚创建好的目录

8.进入hadoop目录,输入 tar -zxvf hadoop-2.7.3.tar.gz 解压tar包

9.输入 vi /etc/profile ,配置环境变量

10.加入如下内容,保存并退出
HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.3/
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
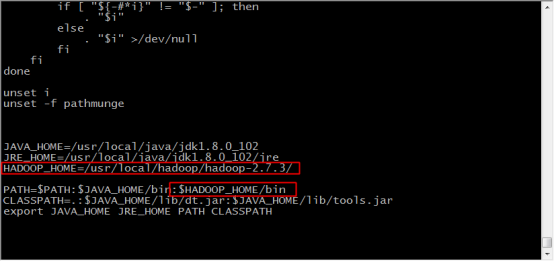
11.输入 . /etc/profile ,使环境变量生效

12.任意目录输入 hado ,然后按Tab,如果自动补全为hadoop,则说明环境变量配的没问题,否则检查环境变量哪出错了

13.创建3个之后要用到的文件夹,分别如下:
mkdir /usr/local/hadoop/tmp

mkdir -p /usr/local/hadoop/hdfs/name

mkdir /usr/local/hadoop/hdfs/data
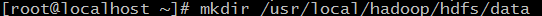
14.进入hadoop解压后的 /etc/hadoop 目录,里面存放的是hadoop的配置文件,接下来要修改这里面一些配置文件
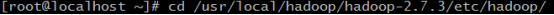
15.有2个.sh文件,需要指定一下JAVA的目录,首先输入 vi hadoop-env.sh 修改配置文件

16.将原有的JAVA_HOME注释掉,根据自己的JDK安装位置,精确配置JAVA_HOME如下,保存并退出
export JAVA_HOME=/usr/local/java/jdk1.8.0_102/
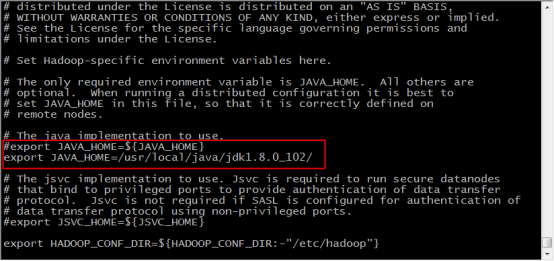
17.输入 vi yarn-env.sh 修改配置文件

18.加入如下内容,指定JAVA_HOME,保存并退出
export JAVA_HOME=/usr/local/java/jdk1.8.0_102
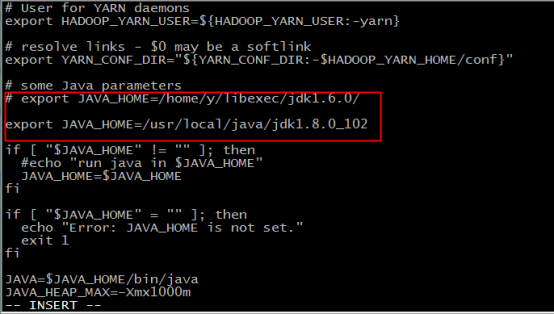
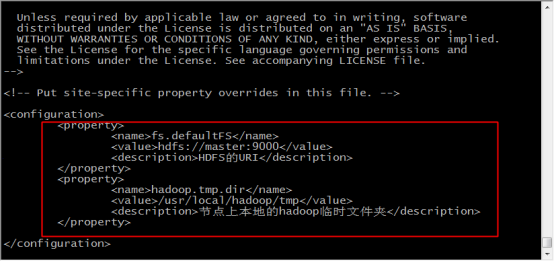
19.输入 vi core-site.xml 修改配置文件

20.在configuration标签中,添加如下内容,保存并退出,注意这里配置的hdfs:master:9000是不能在浏览器访问的
<property>
<name> fs.default.name </name>
<value>hdfs://master:9000</value>
<description>指定HDFS的默认名称</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
<description>HDFS的URI</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
<description>节点上本地的hadoop临时文件夹</description>
</property>
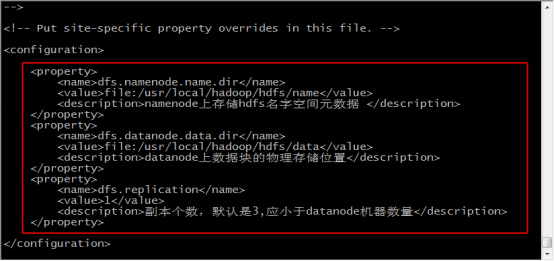
21.输入 vi hdfs-site.xml 修改配置文件

22.在configuration标签中,添加如下内容,保存并退出
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hdfs/name</value>
<description>namenode上存储hdfs名字空间元数据 </description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hdfs/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>副本个数,默认是3,应小于datanode机器数量</description>
</property>
23.输入 cp mapred-site.xml.template mapred-site.xml 将mapred-site.xml.template文件复制到当前目录,并重命名为mapred-site.xml

24.输入 vi mapred-site.xml 修改配置文件

25.在configuration标签中,添加如下内容,保存并退出
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>指定mapreduce使用yarn框架</description>
</property>
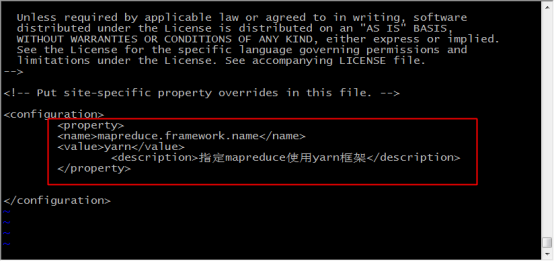
26.输入 vi yarn-site.xml 修改配置文件

27.在configuration标签中,添加如下内容,保存并退出
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
<description>指定resourcemanager所在的hostname</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>
NodeManager上运行的附属服务。
需配置成mapreduce_shuffle,才可运行MapReduce程序
</description>
</property>
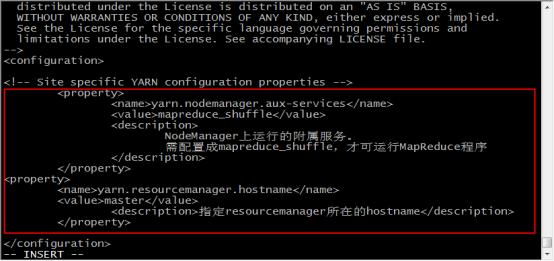
28.输入 vi slaves 修改配置文件

29.将localhost删掉,加入如下内容,即dataNode节点的主机名
node1
node2

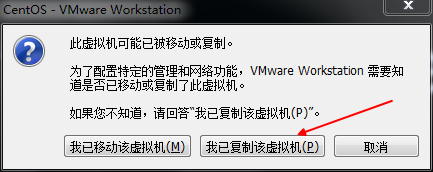
30.将虚拟机关闭,再复制两份虚拟机,重命名为如下,注意这里一定要关闭虚拟机,再复制

31.将3台虚拟机都打开,后两台复制的虚拟机打开时,都选择“我已复制该虚拟机”
32.在master机器上,输入 vi /etc/hostname,将localhost改为master,保存并退出
33.在node1机器上,输入 vi /etc/hostname,将localhost改为node1,保存并退出
34.在node2机器上,输入 vi /etc/hostname,将localhost改为node2,保存并退出
35.在三台机器分别输入 vi /etc/hosts 修改文件,其作用是将一些常用的网址域名与其对应的IP地址建立一个关联,当用户在访问网址时,系统会首先自动从Hosts文件中寻找对应的IP地址
36.三个文件中都加入如下内容,保存并退出,注意这里要根据自己实际IP和节点主机名进行更改,IP和主机名中间要有一个空格
192.168.11.128 master
192.168.11.131 node1
192.168.11.132 node2
37.在master机器上输入 ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa 创建一个无密码的公钥,-t是类型的意思,dsa是生成的密钥类型,-P是密码,’’表示无密码,-f后是秘钥生成后保存的位置

38.在master机器上输入 cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys 将公钥id_dsa.pub添加进keys,这样就可以实现无密登陆ssh

39.在master机器上输入 ssh master 测试免密码登陆

如果有询问,则输入 yes ,回车

40.在node1主机上执行 mkdir ~/.ssh
41.在node2主机上执行 mkdir ~/.ssh
42.在master机器上输入 scp ~/.ssh/authorized_keys root@node1:~/.ssh/authorized_keys 将主节点的公钥信息导入node1节点,导入时要输入一下node1机器的登陆密码

43.在master机器上输入 scp ~/.ssh/authorized_keys root@node2:~/.ssh/authorized_keys 将主节点的公钥信息导入node2节点,导入时要输入一下node2机器的登陆密码

44.在三台机器上分别执行 chmod 600 ~/.ssh/authorized_keys 赋予密钥文件权限

45.在master节点上分别输入 ssh node1 和 ssh node2 测试是否配置ssh成功
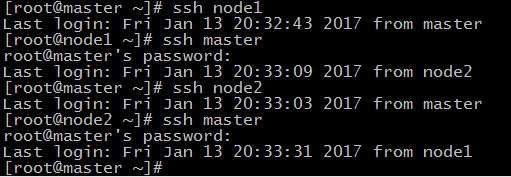
46.如果node节点还没有hadoop,则master机器上分别输入如下命令将hadoop复制
scp -r /usr/local/hadoop/ root@node1:/usr/local/
scp -r /usr/local/hadoop/ root@node2:/usr/local/
47.在master机器上,任意目录输入 hdfs namenode -format 格式化namenode,第一次使用需格式化一次,之后就不用再格式化,如果改一些配置文件了,可能还需要再次格式化

48.格式化完成
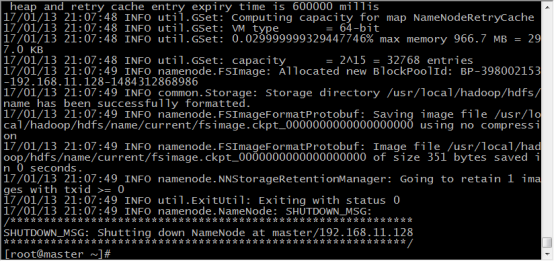
49.在master机器上,进入hadoop的sbin目录,输入 ./start-all.sh 启动hadoop
50.输入yes,回车
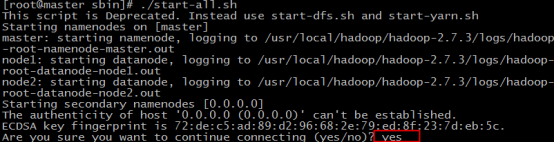
51.输入 jps 查看当前java的进程,该命令是JDK1.5开始有的,作用是列出当前java进程的PID和Java主类名,nameNode节点除了JPS,还有3个进程,启动成功
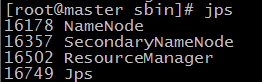
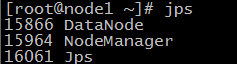
52.在node1机器和node2机器上分别输入 jps 查看进程如下,说明配置成功
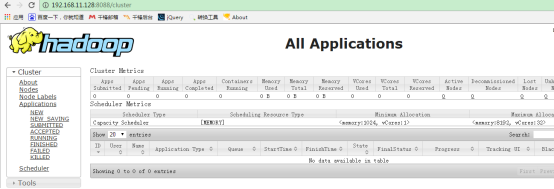
53.在浏览器访问nameNode节点的8088端口和50070端口可以查看hadoop的运行状况
54.在master机器上,进入hadoop的sbin目录,输入 ./stop-all.sh 关闭hadoop
CentOS7下搭建hadoop2.7.3完全分布式的更多相关文章
- 在Win7虚拟机下搭建Hadoop2.6.0伪分布式环境
近几年大数据越来越火热.由于工作需要以及个人兴趣,最近开始学习大数据相关技术.学习过程中的一些经验教训希望能通过博文沉淀下来,与网友分享讨论,作为个人备忘. 第一篇,在win7虚拟机下搭建hadoop ...
- Hadoop(二)CentOS7.5搭建Hadoop2.7.6完全分布式集群
一 完全分布式集群(单点) Hadoop官方地址:http://hadoop.apache.org/ 1 准备3台客户机 1.1防火墙,静态IP,主机名 关闭防火墙,设置静态IP,主机名此处略,参考 ...
- CentOS7.5搭建Hadoop2.7.6完全分布式集群
一 完全分布式集群搭建 Hadoop官方地址:http://hadoop.apache.org/ 1 准备3台客户机 1.2 关闭防火墙,设置静态IP,主机名 关闭防火墙,设置静态IP,主机名此处略 ...
- centos7 下搭建hadoop2.9 分布式集群
首先说明,本文记录的是博主搭建的3节点的完全分布式hadoop集群的过程,环境是centos 7,1个nameNode,2个dataNode,如下: 1.首先,创建好3个Centos7的虚拟机,具体的 ...
- Centos7.5搭建Hadoop2.8.5完全分布式集群部署
一.基础环境设置 1. 准备4台客户机(VMware虚拟机) 系统版本:Centos7.5 节点配置: 192.168.208.128 --Master 192.168.208.129 --Slave ...
- 在CentOS7下搭建Hadoop2.9.0集群
系统环境:CentOS 7 JDK版本:jdk-8u191-linux-x64 MYSQL版本:5.7.26 Hadoop版本:2.9.0 Hive版本:2.3.4 Host Name Ip User ...
- 在Win7虚拟机下搭建Hadoop2.6.0+Spark1.4.0单机环境
Hadoop的安装和配置可以参考我之前的文章:在Win7虚拟机下搭建Hadoop2.6.0伪分布式环境. 本篇介绍如何在Hadoop2.6.0基础上搭建spark1.4.0单机环境. 1. 软件准备 ...
- 32位Ubuntu12.04搭建Hadoop2.5.1完全分布式环境
准备工作 1.准备安装环境: 4台PC,均安装32位Ubuntu12.04操作系统,统一用户名和密码 交换机1台 网线5根,4根分别用于PC与交换机相连,1根网线连接交换机和实验室网口 2.使用ifc ...
- Hyperledger超级账本在Centos7下搭建运行环境
超级账本(hyperledger)是Linux基金会于2015年发起的推进区块链数字技术和交易验证的开源项目,加入成员包括:荷兰银行(ABN AMRO).埃森哲(Accenture)等十几个不同利益体 ...
随机推荐
- Andorid源码系列:View的onTouchEvent()与performClick(),performLongClick()调用时机解析
这是大土豆的第一篇博客,想着工作3年多了,在工作上从一名菜鸟逐渐成长为在项目中能干点事的人,自己对Android的见解也一步步加深,有必要写一些对Android代码和开发过程中的感悟,和广大朋友们分享 ...
- PCI_Making Recommendations
协作性过滤 简单理解从众多用户中先搜索出与目标用户'品味'相似的部分人,然后考察这部分人的偏爱,根据偏爱结果为用户做推荐.这个过程也成为基于用户的协作性过滤(user_based collaborat ...
- phpstudy:80端口被占用解决方案总结
一开始因为要安装新的软件,同时也由于一直电脑很卡,所以直接重装系统,从WIN8变成WIN10,然后不知道为什么,phpstudy里面80端口被占用了!被占用了!现在找到了两种方法解决! 第一种 该端口 ...
- Experience of Python Learning Week 1
1.The founder of python is Guido van Rossum ,he created it on Christmas in 1989, smriti of ABC langu ...
- javascript编程解决黑白卡片问题
问题描述: 时间限制:1秒 空间限制:32768K 牛牛有n张卡片排成一个序列.每张卡片一面是黑色的,另一面是白色的.初始状态的时候有些卡片是黑色朝上,有些卡片是白色朝上.牛牛现在想要把一些卡片翻过来 ...
- unable to create …
问题描述: 在新建Android Application时会出现unable to create the selected property page 解决方法: 将用户PATH路径中的jdk路径放到 ...
- 设置webstorm缩写代码
文件 ->设置->编辑器->活动模板->找到需要设置的文件类型(比如JavaScript)-->添加-(右上角)->设置模板之后,注意最后需要defind才能生效
- 使用Hibernate模板调用存储过程
前提是该Dao类已经已经继承了org.springframework.orm.hibernate5.support.HibernateDaoSupport,并且在整个项目中已经配置好了事务,或者是手动 ...
- 贡献你的代码,将jar包发布到Maven中央仓库以及常见错误的解决办法
前几天将自己的日志工具发布到了Maven中央仓库中.这个工具本省没有多少技术含量,因为是修改别人的源代码实现的,但是将jar发布到Maven仓库却收获颇丰,因为网上有些教程过时了,在此分享下自己发布j ...
- Consul文档简要整理
什么是Consul? Consul是一个用来实现分布式系统的服务发现与配置的开源工具.他主要由多个组成部分: 服务发现:客户端通过Consul提供服务,类似于API,MySQL,或者其他客户端可以使用 ...