python网络爬虫笔记(五)
一、python的类对象的继承
1、所有的父类都是object类,由于类可以起到模块的作用,因此,可以在创建实例的时候,巴西一些认为必须要绑定的属性填写上去,通过定义一个特殊的方法 __init__,绑定属性值、,注意 __init__ 方法的第一个参数永远是self,表示创建的是实例本身,在__init__方法内部,就可以将各种属性绑定到self,因为self就是指向创建实例本身。有了__init__方法就不能在创建实例的时候传入空的参数。而且必须传入与__intit__方法匹配的参数。但是self不需要再次传入,python解释器自己会把实例变量传进。
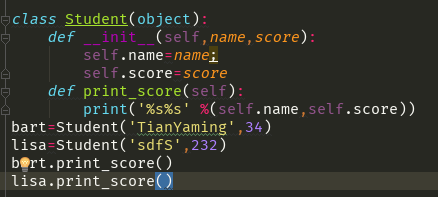

2、数据封装,面向对象编程最重要的是数据封装,在Student类中,每个实例都有各自的name 和score这些数据,可以通过函数来访问这些数据。封装的另一个好处就是可以随时给类添加新的方法,如果让内部的属性不被外部访问,可以把属性的名称前加上两个下划线__,,,实例的变量名如果以__开头,就表示这是一个私有变量(private)只可以在内部访问。
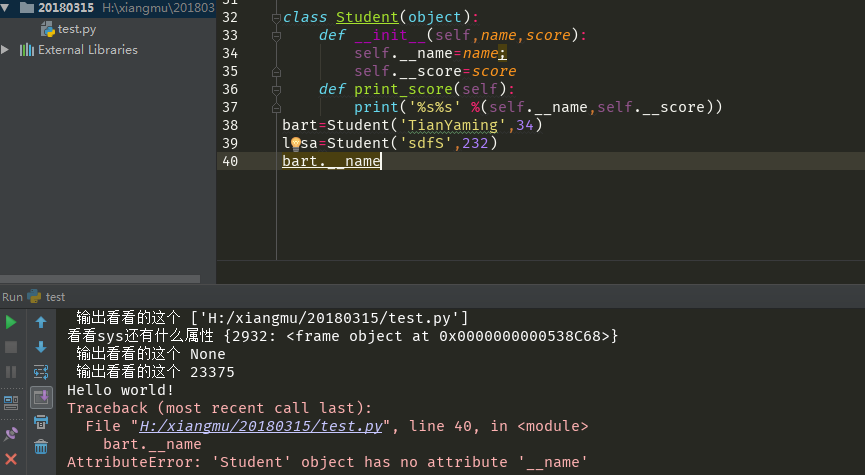
但是注意的一点就是 变量名__xx__这样双划线开头的并且是结尾的,是特殊变量。特殊变量只可以直接访问的。
3、判断一个对象是否属于这个类的语句
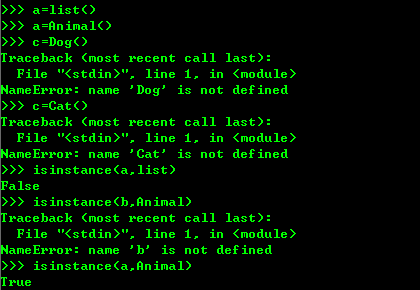
4、多态的好处就是当我们需要传入Dog Cat Tortoise 时,实际上任何依赖Animal作为参数的函数或者方法都可以不加修饰正常运行,原因就是出于多态,多态的好处,当我们传入Dog Cat 等 我们只需要修改Animal类就可以,因为Dog Cat 等就是Animal的类型,然后按照Animal类型进行操作,由于Animal类型有run()方法,因此传入的类型是Animal 类或者子类,就会自动调用实际类型的run() 方法,就是多态的。对于静态语言如果传入Animal类型,则传入的对象必须是Animal类型或者子类,否则无法调用run() 方法,对于python动态语言来说,只需要传入的对象有run()方法就可以啦。
继承可以父类的所有功能直接拿过来名字类只需要新增自己的特有方法,也可以吧父类不适合的方法覆盖重写,

5、类型判断type(),从这里可以看出type函数其实返回的就是 class
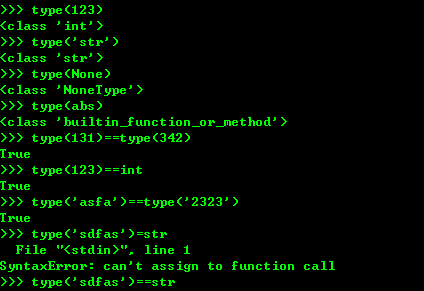
6、判断基本数据类型可以直接写int ,str等,但是如果判断一个对象是否是函数就要使用 types模块中定义的常量,
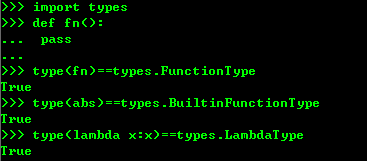
但是对于class继承关系来说,使用type()就很不方便,我们要判断class类型可以使用isinstance()函数,isinstance()判断一个对象是否是该类型的本身或者位于该类型的父类继承链接上。

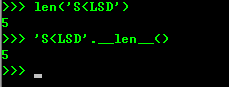
能用type()判断的基本类型也可以会用isinstance()判断,获得一个对象的所有属性和方法使用dir()函数

顺便插一句 pycharm的server注册链接地址测试可行的http://idea.liyang.io
对对象进行属性的测试
python网络爬虫笔记(五)的更多相关文章
- Python网络爬虫笔记(五):下载、分析京东P20销售数据
(一) 分析网页 下载下面这个链接的销售数据 https://item.jd.com/6733026.html#comment 1. 翻页的时候,谷歌F12的Network页签可以看到下面 ...
- [Python]网络爬虫(五):urllib2的使用细节与抓站技巧
转自:http://blog.csdn.net/pleasecallmewhy/article/details/8925978 前面说到了urllib2的简单入门,下面整理了一部分urllib2的使用 ...
- [Python]网络爬虫(五):urllib2的使用细节与抓站技巧(转)
1.Proxy 的设置 urllib2 默认会使用环境变量 http_proxy 来设置 HTTP Proxy. 如果想在程序中明确控制 Proxy 而不受环境变量的影响,可以使用代理. 新建test ...
- Python网络爬虫笔记(二):链接爬虫和下载限速
(一)代码1(link_crawler()和get_links()实现链接爬虫) import urllib.request as ure import re import urllib.parse ...
- python网络爬虫笔记(九)
4.1.1 urllib2 和urllib是两个不一样的模块 urllib2最简单的就是使用urllie2.urlopen函数使用如下 urllib2.urlopen(url[,data[,timeo ...
- python网络爬虫笔记(八)
一.pthon 序列化json格式 1.将python内置对象转换成json 模块,dumps()方法返回的是一个str,内容是标准的JSON,dump()方法可以直接吧JSON写入一个file-li ...
- python网络爬虫笔记(六)
1.获取属性如果不存在就返回404,通过内置一系列函数,我们可以对任意python对象进行剖析,拿到其内部数据,但是要注意的是,只是在不知道对象信息的时候,我们可以获得对象的信息. 2.实例属性和类属 ...
- python网络爬虫笔记(四)
一.python中的高阶函数算法 1.sorted()函数的排序 sorted()函数是一个高阶函数,还可以接受一个key函数来实现自定义的函数排序,key指定的函数作用于每个序列元素上,并根据k ...
- python网络爬虫笔记(三)
一.切片和迭代 1.列表生成式 2.生成器的generate,但是generate保存的是算法,所以可以迭代计算,没有必要,每次调用generate 二.iteration 循环 1.凡是作用于for ...
随机推荐
- LOJ #2196「SDOI2014」LIS
直接退流复杂度好优越啊 LOJ #2196 题意 一段数列,每个点有点权$ A_i$,删除代价$ B_i$,附加属性$ C_i$ 求最小代价使得$ LIS$长度发生变化,且输出一种$ C_i$字典序最 ...
- 【Thymeleaf】常用属性
参考链接 Thymeleaf 常用属性
- 【防坑指南】nginx重启后出现[error] open() “/usr/local/var/run/nginx/nginx.pid” failed
重新启动nginx后,出现报错,原因就是下没有nginx文件夹或没有nginx.pid文件,为什么会没有呢? 原因就是每次重新启动,系统都会自动删除文件,所以解决方式就是更改pid文件存储的位置, 打 ...
- 基于keepalived搭建MySQL热机集群
背景 MySQL的高可用方案一般有如下几种: keepalived+双主,MHA,MMM,Heartbeat+DRBD,PXC,Galera Cluster 比较常用的是keepalived+双主,M ...
- android 组建添加透明度
给TextView添加透明度,起初用的方法是android:alpha = "0.3" 添加后,文字显示也有点透明发虚,后来改成设置background,然后 backgroun ...
- 管理并行SQL执行的进程
本节介绍的并行执行功能可用于Oracle数据库企业版 本节介绍如何管理SQL语句的并行处理.在此配置中,Oracle数据库可以将处理SQL语句的工作分为多个并行进程. 许多SQL语句的执行可以并行化. ...
- CentOS7开启防火墙及特定端口
开启防火墙服务 以前为了方便,把防火墙都关闭了,因为现在项目都比较重要,害怕受到攻击,所以为了安全性,现在需要将防火墙开启,接下来介绍一下步骤. 1, 首先查看防火墙状态: firewall-cmd ...
- 【转】Leveldb源码分析——1
先来看看Leveldb的基本框架,几大关键组件,如图1-1所示. Leveldb是一种基于operation log的文件系统,是Log-Structured-Merge Tree的典型实现.LSM源 ...
- ACM Computer Factory POJ - 3436 网络流拆点+路径还原
http://poj.org/problem?id=3436 每台电脑有$p$个组成部分,有$n$个工厂加工电脑. 每个工厂对于进入工厂的半成品的每个组成部分都有要求,由$p$个数字描述,0代表这个部 ...
- Sq lServer触发器的使用
创建表: CREATE TABLE [dbo].[GeneralRule]( [ID] [int] NOT NULL, ) NULL, [DeleteFlag] [int] NOT NULL ) CR ...