scrapy基础二
应对反爬虫机制
①、禁止cookie :有的网站会通过用户的cookie信息对用户进行识别和分析,此时可以通过禁用本地cookies信息让对方网站无法识别我们的会话信息
settings.py里开启禁用cookie
# Disable cookies (enabled by default)
COOKIES_ENABLED = False
②、设置下载延时:有的网站会对网页的访问频率进行分析,如果爬取过快,会被判断为自动爬取行为
settings.py里设置下载延时
#DOWNLOAD_DELAY = 3 #去掉注释,3代表3秒
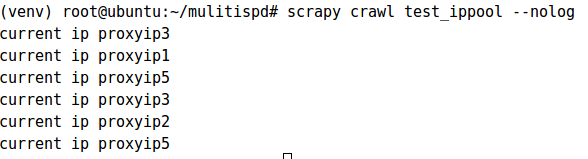
③、使用ip池: 有的网站会对用户的ip进行判断,所以需要多个ip地址。这些地址组成一个ip池,爬虫每次爬取会从ip池中随机选择一个ip,此时可以为爬虫项目建立一个中间件文件,定义ip使用规则
#1、创建项目略过 #2、settings.py 设置代理ip地址池 IPPOOL=[
{"ipaddr":"proxyip1"},
{"ipaddr":"proxyip2"},
{"ipaddr":"proxyip3"},
{"ipaddr":"proxyip4"},
{"ipaddr":"proxyip5"},
{"ipaddr":"proxyip6"},
{"ipaddr":"proxyip7"}
] #3、创建一个中间件文件 middle_download_wares.py #-*-coding:utf-8-*- import random
from mulitispd.settings import IPPOOL
from scrapy.contrib.downloadermiddleware.httpproxy import HttpProxyMiddleware class IPPOOLS(HttpProxyMiddleware):
def __init__(self,ip=''):
self.ip = ip def process_request(self, request, spider):
thisip = random.choice(IPPOOL)
print ("current ip "+thisip["ipaddr"])
request.meta['proxy'] = "http://"+thisip['ipaddr'] #4设置settings.py注册为项目中间件,格式:中间件所在目录.中间件文件名.中间件内部要使用的类
DOWNLOADER_MIDDLEWARES = {
#'mulitispd.middlewares.MulitispdDownloaderMiddleware': 543,
'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware':123,
'mulitispd.middle_download_wares.IPPOOLS':125
}
测试结果:
④、使用用户代理池: User-Agent变换使用,方法流程与使用ippool方法一样
#1、设置settings.py 里User-agent UAPOOL=[
"MOzilla/5.0 ...",
"Chrom/49.0.2623.22 ....."
] #2、新建中间件文件 #-*-coding:utf-8-*- import random
from mulitispd.settings import UAPOOL
from scrapy.contrib.downloadermiddleware.useragent import UserAgentMiddleware class UAPOOLS(UserAgentMiddleware):
def __init__(self,useragent=''):
self.useragent = useragent def process_request(self, request, spider):
thisua = random.choice(UAPOOL)
print ("current useragent "+thisua)
request.headers.setdefault("User-Agent",thisua) #3、settings.py注册中间件
DOWNLOADER_MIDDLEWARES = {
#'mulitispd.middlewares.MulitispdDownloaderMiddleware': 543,
'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware':123,
'mulitispd.middle_download_wares.IPPOOLS':125,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware':2,
'mulitispd.middle_useragent_wares.UAPOOLS':1
}
Scrapy核心架构
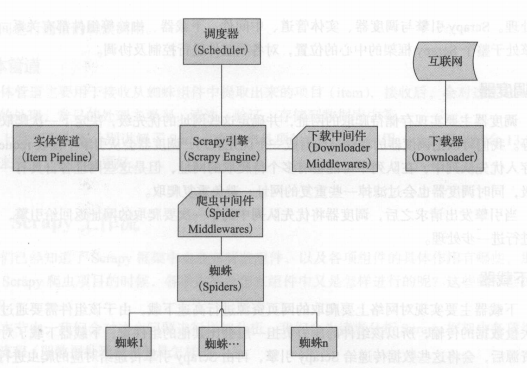
说明:





工作流
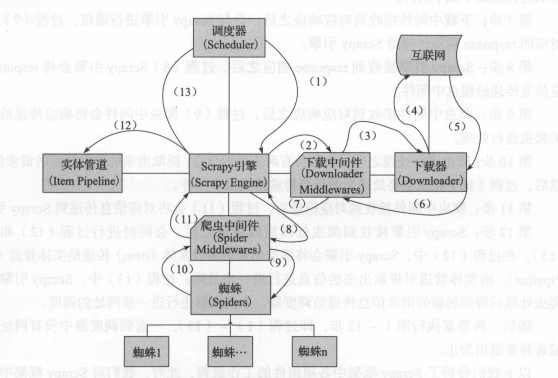


总结:

简单示例
爬取网页内容爬虫(爬取当当网特产)
创建项目及爬虫文件
scrapy startproject autopro
scrapy genspider -t basic autospd dangdang.com
编写items.py
import scrapy class AutoproItem(scrapy.Item):
name = scrapy.Field() #商品名称
price = scrapy.Field() #商品价格
link = scrapy.Field() #商品链接
comnum = scrapy.Field() #商品评论数量
编写爬虫文件autospd.py
# -*- coding: utf-8 -*-
import scrapy
from autopro.items import AutoproItem
from scrapy.http import Request class AutospdSpider(scrapy.Spider):
name = 'autospd'
allowed_domains = ['dangdang.com']
start_urls = ['http://dangdang.com/'] def parse(self, response):
item = AutoproItem()
item['name'] = response.xpath("//a[@class='pic']/@title").extract() #xpath分析结果,@title表示获取titile属性的值
item['price'] =response.xpath("//span[@class='price_n']/text()").extract()
item['link'] = response.xpath("//a[@class='pic']/@href").extract()
item['comnum'] = response.xpath("//a[@dd_name='单品评论']/text()").extract()
yield item
for i in range(1,10):
url="http://category.dangdang.com/pg"+str(i)+"-cid4011029.html" yield Request(url,callback=self.parse)
编写pipelines.py
import codecs #导入codecs模块直接进行解码
import json class AutoproPipeline(object): def __init__(self):
self.file = codecs.open("/root/mydata.json",'wb',encoding="utf-8") #表示将爬取结果写到json文件里 def process_item(self, item, spider): #process_item为pipelines中的主要处理方法,默认会自动调用
for i in range(0,len(item["name"])):
name = item['name'][i]
price = item['price'][i]
comnum = item['comnum'][i]
link = item['link'][i]
goods = {"name":name,"price":price,"comnum":comnum,"link":link}
i = json.dumps(dict(goods),ensure_ascii=False)
line = i+'\n'
self.file.write(line)
return item def close_spider(self,spider):
self.file.close()
设置settings.py
ROBOTSTXT_OBEY = False #表示不遵循robots协议
COOKIES_ENABLED = False #禁止cookie
#开启pipelines
ITEM_PIPELINES = {
'autopro.pipelines.AutoproPipeline': 300,
}
结果:

CrawlSpider
crawlspider是scrapy框架自带爬取网页的爬虫,可以实现网页的自动爬取
创建crawlspider 爬虫文件
crapy genspider -t crawl test_crawl jd.com
test_crawl.py
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule class TestCrawlSpider(CrawlSpider):
name = 'test_crawl'
allowed_domains = ['jd.com']
start_urls = ['http://jd.com/'] #链接提取器 ,allow 为自定义设置的爬行规则,follow表示跟进爬取。即发现新的链接继续爬行,allow_domains表示允许爬行的连接
rules = (
Rule(LinkExtractor(allow=r'Items/'),allow_domains=(aa.com) callback='parse_item', follow=True),
) def parse_item(self, response):
i = {}
#i['domain_id'] = response.xpath('//input[@id="sid"]/@value').extract()
#i['name'] = response.xpath('//div[@id="name"]').extract()
#i['description'] = response.xpath('//div[@id="description"]').extract()
return i
scrapy基础二的更多相关文章
- Python全栈开发【基础二】
Python全栈开发[基础二] 本节内容: Python 运算符(算术运算.比较运算.赋值运算.逻辑运算.成员运算) 基本数据类型(数字.布尔值.字符串.列表.元组.字典) 其他(编码,range,f ...
- Bootstrap <基础二十九>面板(Panels)
Bootstrap 面板(Panels).面板组件用于把 DOM 组件插入到一个盒子中.创建一个基本的面板,只需要向 <div> 元素添加 class .panel 和 class .pa ...
- Bootstrap <基础二十八>列表组
列表组.列表组件用于以列表形式呈现复杂的和自定义的内容.创建一个基本的列表组的步骤如下: 向元素 <ul> 添加 class .list-group. 向 <li> 添加 cl ...
- Bootstrap<基础二十七> 多媒体对象(Media Object)
Bootstrap 中的多媒体对象(Media Object).这些抽象的对象样式用于创建各种类型的组件(比如:博客评论),我们可以在组件中使用图文混排,图像可以左对齐或者右对齐.媒体对象可以用更少的 ...
- Bootstrap <基础二十六>进度条
Bootstrap 进度条.在本教程中,你将看到如何使用 Bootstrap 创建加载.重定向或动作状态的进度条. Bootstrap 进度条使用 CSS3 过渡和动画来获得该效果.Internet ...
- Bootstrap <基础二十五>警告(Alerts)
警告(Alerts)以及 Bootstrap 所提供的用于警告的 class.警告(Alerts)向用户提供了一种定义消息样式的方式.它们为典型的用户操作提供了上下文信息反馈. 您可以为警告框添加一个 ...
- Bootstrap<基础二十四> 缩略图
Bootstrap 缩略图.大多数站点都需要在网格中布局图像.视频.文本等.Bootstrap 通过缩略图为此提供了一种简便的方式.使用 Bootstrap 创建缩略图的步骤如下: 在图像周围添加带有 ...
- Bootstrap <基础二十三>页面标题(Page Header)
页面标题(Page Header)是个不错的功能,它会在网页标题四周添加适当的间距.当一个网页中有多个标题且每个标题之间需要添加一定的间距时,页面标题这个功能就显得特别有用.如需使用页面标题(Page ...
- Bootstrap <基础二十二>超大屏幕(Jumbotron)
Bootstrap 支持的另一个特性,超大屏幕(Jumbotron).顾名思义该组件可以增加标题的大小,并为登陆页面内容添加更多的外边距(margin).使用超大屏幕(Jumbotron)的步骤如下: ...
随机推荐
- 【Java】Android EditText开发的一个容易忽略的坑
这几天接手做一个远程控制Android application,安卓前台的EditText用来输入ip地址.端口等信息,发现EditText的使用存在着巨坑一个! 我在网上找了半天,发现仅仅有人提出这 ...
- javadoc格式化,解决多个形参空格暴多,页面溢出问题
格式化前: 格式化后: pom.xml <?xml version="1.0" encoding="UTF-8"?> <project xml ...
- Python中csv模块解析
导入模块 import csv 2.读取csv文件 file1 = open('test1.csv', 'rb') reader = csv.reader(file1) rows = [row for ...
- 【XSY2730】Ball 多项式exp 多项式ln 多项式开根 常系数线性递推 DP
题目大意 一行有\(n\)个球,现在将这些球分成\(k\) 组,每组可以有一个球或相邻两个球.一个球只能在至多一个组中(可以不在任何组中).求对于\(1\leq k\leq m\)的所有\(k\)分别 ...
- Java的equals方法,首先要判断类型是否相同
如下代码,Long 和Integer 进行比较: Integer aa = 1; Long bb= 1L; System.out.println(aa.equals(bb)); 输出为:false 查 ...
- MS-DOS 系统汇编环境之DOSBOX+vim
经过虚拟机的体验,我发现还是dosbox里汇编比较方便..... 一.下载安装 dosbox DOSBOX 准备好 masm.exe.link.exe.debug.exe,放在~/dos下(文件夹名字 ...
- Tarjan求有向图强连通详解
Tarjan求有向图强连通详解 注*该文章为转发,原文出处已经不得而知 :first-child { margin-top: 0; } blockquote > :last-child { ma ...
- failover swarm 故障转移
#故障转移 Failover #当其中一个节点关闭宕机时,其节点中的service会转移到另一个节点上.Swarm会检测到node1发生故障并把此故障节点的状态标记为Down; docker node ...
- 在JSON中遇到的一些坑
今天在进行压测的时候,由于需要使用到json进行传参,并且需要在JMeter中加入少量的JSON,由于JSON在java中呈现键值对的形式,并且需要使用到“”来修饰,导致只能使用\进行转义,在发送请求 ...
- js原生事件系统与坐标系统
今天来实现一个可兼容的js原生拖拽,在这里面我将会讲到: 1.封装兼容性的事件系统. 2.封装得到鼠标当前位置的系统. 3.完成拖拽的实现. 首先,我们要讲到鼠标位置的获取,讲到这个,就离不开js的w ...