Python爬虫:爬取美拍小姐姐视频
最近在写一个应用,需要收集微博上一些热门的视频,像这些小视频一般都来自秒拍,微拍,美拍和新浪视频,而且没有下载的选项,所以只能动脑想想办法了。
第一步
分析网页源码。 例如:http://video.weibo.com/show?fid=1034:0988e59a12e5178acb7f23adc3fe5e97,右键查看源码,一般视频都是mp4后缀,搜索发现没有,但是有的直接就能看到了比如美拍的视频。
第二步
抓包,分析请求和返回。这个也可以通过强大的chrome实现,还是上面的例子,右键->审查元素->NetWork,然后F5刷新网页
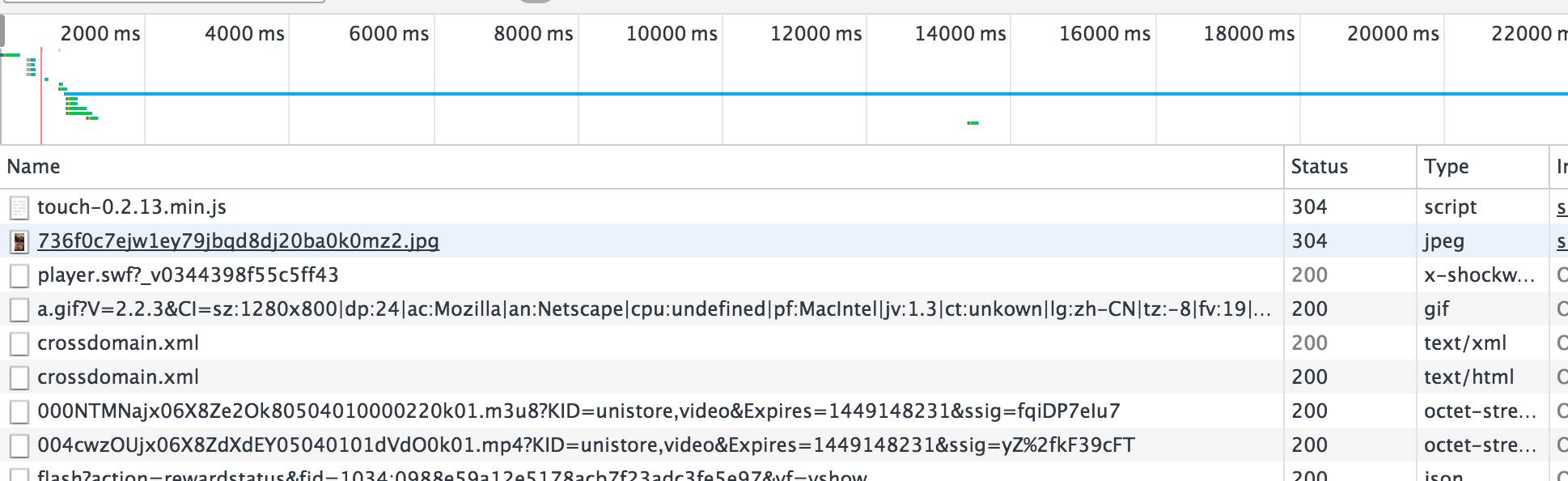
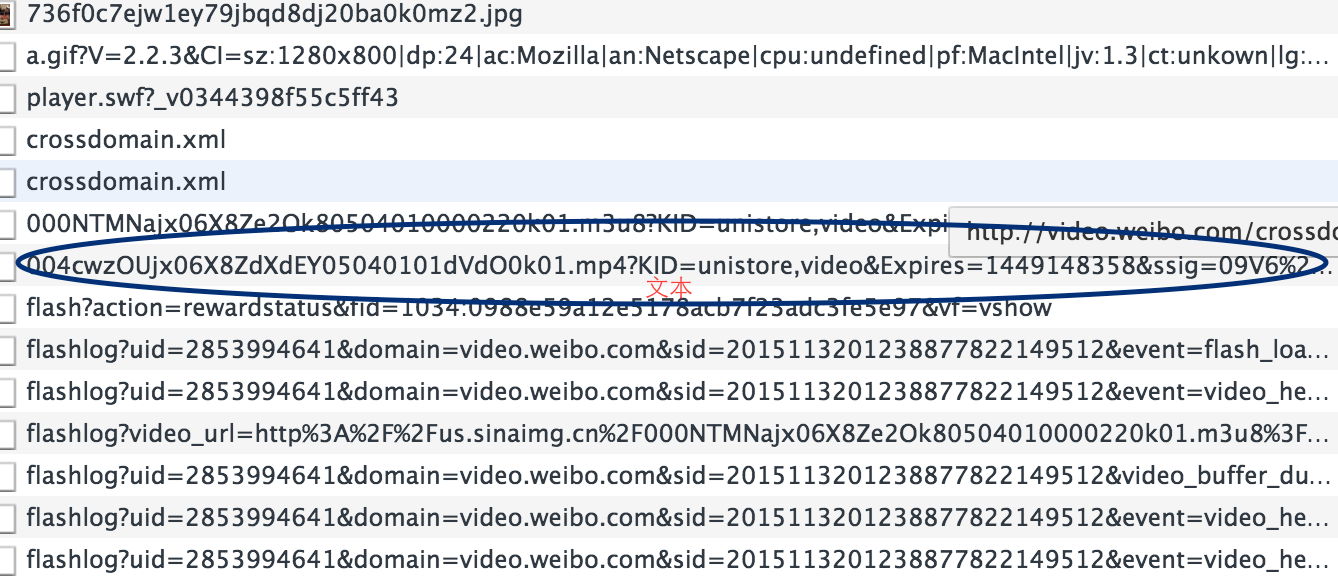
发现有很多请求,只能一条一条的分析了,其实视频格式就是那几种mp4,flv,avi了,一下就能看到了,复制到浏览器中打开,果然就是我们想要的下载链接了。
第三步
分析下载链接和视频链接的规律。即http://video.weibo.com/show?fid=1034:0988e59a12e5178acb7f23adc3fe5e97与xxx.mp4的关系。这个又需要分析网页源码了,其实可以注意上面那个以.m3u8后缀的链接,m3u8记录了一个索引纯文本文件,打开它时播放软件并不是播放它,而是根据它的索引找到对应的音视频文件的网络地址进行在线播放,打开看,里面确实记录着我们想要的下载链接。而且.m3u8后缀的链接就在网页源码中。

总结
经过前三步的分析,获取视频下载链接的思路就是先从网页源码中获取.m3u8后缀的链接,下载该文件,从里面得到视频下载链接,最后下载视频就好了
源码
#sinavideo.py
#coding=utf-8
import os
import re
import urllib2
import urllib
from common import Common
class SinaVideo(): URL_PIRFIX = "http://us.sinaimg.cn/"
def getM3u8(self,html):
reg = re.compile(r'list=([\s\S]*?)&fid')
result = reg.findall(html)
return result[0] def getName(self,url):
return url.split('=')[1] def getSinavideoUrl(self,filepath):
f = open(filepath,'r')
lines = f.readlines()
f.close()
for line in lines:
if line[0] !='#':
return line def download(self,url,filepath):
#获取名称
name = self.getName(url)
html = Common.getHtml(url)
m3u8 = self.getM3u8(html)
Common.download(urllib.unquote(m3u8),filepath,name + '.m3u8')
url = self.URL_PIRFIX + self.getSinavideoUrl(filepath+name+'.m3u8')
Common.download(url,filepath,name+'.mp4')
#common.py
#coding=utf-8
import urllib2
import os
import re class Common():
# 获取网页源码
@staticmethod
def getHtml(url):
html = urllib2.urlopen(url).read()
print "[+]获取网页源码:"+url
return html # 下载文件
@staticmethod
def download(url,filepath,filename):
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Charset': 'UTF-8,*;q=0.5',
'Accept-Encoding': 'gzip,deflate,sdch',
'Accept-Language': 'en-US,en;q=0.8',
'User-Agent': 'Mozilla/5.0 (Linux; Android 4.4.2; Nexus 4 Build/KOT49H) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.114 Mobile Safari/537.36'
}
request = urllib2.Request(url,headers = headers);
response = urllib2.urlopen(request)
path = filepath + filename
with open(path,'wb') as output:
while True:
buffer = response.read(1024*256);
if not buffer:
break
# received += len(buffer)
output.write(buffer) print "[+]下载文件成功:"+path @staticmethod
def isExist(filepath):
return os.path.exists(filepath) @staticmethod
def createDir(filepath):
os.makedirs(filepath,0777)
调用方式:
url = "http://video.weibo.com/show?fid=1034:0988e59a12e5178acb7f23adc3fe5e97"
sinavideo = SinaVideo() sinavideo.download(url,""/Users/cheng/Documents/PyScript/res/"")
结果

Python爬虫:爬取美拍小姐姐视频的更多相关文章
- python爬取快手小姐姐视频
流程分析 一.导入需要的三方库 import re #正则表表达式文字匹配 import requests #指定url,获取网页数据 import json #转化json格式 import os ...
- 用python写一个爬虫——爬取性感小姐姐
忍着鼻血写代码 今天写一个简单的网上爬虫,爬取一个叫妹子图的网站里面所有妹子的图片. 然后试着先爬取了三页,大概有七百多张图片吧!各个诱人的很,有兴趣的同学可以一起来爬一下,大佬级程序员勿喷,简单爬虫 ...
- Python爬虫---爬取抖音短视频
目录 前言 抖音爬虫制作 选定网页 分析网页 提取id构造网址 拼接数据包链接 获取视频地址 下载视频 全部代码 实现结果 待解决的问题 前言 最近一直想要写一个抖音爬虫来批量下载抖音的短视频,但是经 ...
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- Python爬虫|爬取喜马拉雅音频
"GOOD Python爬虫|爬取喜马拉雅音频 喜马拉雅是知名的专业的音频分享平台,用户规模突破4.8亿,汇集了有声小说,有声读物,儿童睡前故事,相声小品等数亿条音频,成为国内发展最快.规模 ...
- python爬虫爬取内容中,-xa0,-u3000的含义
python爬虫爬取内容中,-xa0,-u3000的含义 - CSDN博客 https://blog.csdn.net/aiwuzhi12/article/details/54866310
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
随机推荐
- Intellij IDEA 2018.2.2 SpringBoot热启动 (Maven)
一.IDEA 工具配置 1. 打开IDEA 设置界面,选择编译,按图打勾. 2 . 然后 Shift+Ctrl+Alt+/,选择Registry 3 . compiler.automake.allow ...
- kafka restful api功能介绍与使用
前述 采用confluent kafka-rest proxy实现kafka restful service时候(具体参考上一篇笔记),通过http协议数据传输,需要注意的是采用了base64编码(或 ...
- 初试mininet(可选PyCharm)
目录 0x00 Mininet 0x01 Important classes, methods, functions 0x02 Sample 0x04 run in shell 0x05 Output ...
- centos 7 配置nginx 的yum源
在/etc/yum.repos.d里创建nginx.repo文件: touch nginx.repo vim nginx.repo 填写如下内容后保存 [nginx] name=nginx repo ...
- JavaScript的迭代函数与迭代函数的实现
前言 如果对技术很自信,请直接看 实现的源码 如果想回顾一下基础,请按文章顺序阅读 说到迭代方法,最先想到的是什么?forEach还是map,迭代的方法ES5提供了5种方法 以下定义来自 Ja ...
- mongdb的聚合管道
我们先介绍一下 MongoDB 的聚合功能,聚合操作主要用于对数据的批量处理,往往将记录按条件分组以后,然后再进行一系列操作,例如,求最大值.最小值.平均值,求和等操作.聚合操作还能够对记录进行复杂的 ...
- Python学习 :面向对象(一)
面向对象 一.定义 面向对象:面向对象为类和对象之间的应用 class + 类名: #在类中的函数称作 “方法“ def + 方法名(self,arg): #方法中第一个参数必须是 self prin ...
- [Golang学习笔记] 08 链表
链表(Linked list)是一种常见数据结构,但并不会按线性的顺序存储数据,而是在每一个节点里存到下一个节点的指针. 由于不必须按顺序存储,链表在插入的时候可以达到O(1),比顺序表快得多,但是查 ...
- 20155203 实验二《Java面向对象程序设计》实验报告
20155203 实验二<Java面向对象程序设计>实验报告 一.实验内容 参考http://www.cnblogs.com/rocedu/p/6371315.html#SECUNITTE ...
- 20155234 2016-2017-2 《Java程序设计》第2周学习总结
20155234 2006-2007-2 <Java程序设计>第2周学习总结 教材学习内容总结 %%:表示字符串中的%. %d:以十进制整数格式输出 %f:以十进制浮点式格式输出 %e(% ...