multi-label image classification:多标签图像分类总结
多标签图像分类总结
目录
1.简介
2.现有数据集和评价指标
3.学习算法
4.总结(现在存在的问题,研究发展的方向)
简介
传统监督学习主要是单标签学习,而现实生活中目标样本往往比较复杂,具有多个语义,含有多个标签。
 荷兰城市图片
荷兰城市图片
(1)传统单标签分类
city(person)
(2)多标签分类
city , river, person, European style
(3)人的认知
两个人在河道边走路
欧洲式建筑,可猜测他们在旅游
天很蓝,应该是晴天但不是很晒
相比较而言,单标签分类需要得到的信息量最少,人的认知得到的信息量最多,多标签分类在它们两者之间
问题描述:
X=Rd表示d维的输入空间,Y={y1,y2,...,yq}表示带有q个可能的标签的标签空间
训练集D={(xi,yi)|1≤ i ≤ m},m表示训练集的大小,上标表示样本序数
xi∈ X,是一个d维向量。yi⊆Y,是Y的一个标签子集
任务就是学习要学习一个多标签集的分类器h(x),预测h(x)⊆Y作为x的正确标签集。
常见的做法是学习一个衡量x和y相关性的函数f(x,yj),希望f(x,yj1)>(x,yj2),其中yj1∈y,yj2∉y。
现有数据集和评价指标
1.现有数据集
NUS-WIDE 是一个带有网络标签标注的图像数据,包含来自网站的 269648张 图像,5018类 不同的标签。
从这些图像中提取的六种低级特征,包括64-D颜色直方图,144-D颜色相关图,73-D边缘方向直方图,128-D小波纹理,225-D块颜色矩和500-D 基于SIFT描述的词袋。
网址:http://lms.comp.nus.edu.sg/research/NUS-WIDE.htm
MS-COCO 数据集包括91类目标,328,000影像和2,500,000个label。
所有的物体实例都用详细的分割mask进行了标注,共标注了超过 500,000 个物体实体.
网址:http://cocodataset.org/
PASCAL VOC数据集该挑战的主要目标是在真实场景中识别来自多个视觉对象类的对象。 它基本上是监督学习学习问题,因为提供了标记图像的训练集。 已选择的20个对象类是:
人:人
动物:鸟,猫,牛,狗,马,羊
车辆:飞机,自行车,船,公共汽车,汽车,摩托车,火车
室内:瓶子,椅子,餐桌,盆栽,沙发,电视/显示器
train/val数据有11,530张图像,包含27,450个ROI注释对象和6,929个segmentation。
网址:http://host.robots.ox.ac.uk/pascal/VOC/voc2012/index.html#devkit
腾讯 AI Lab 此次开源的 ML-Images 数据集包括 1800 万训练图像和 1.1 万多常见物体类别.
2.评价指标
可分为三类
- 基于样本的评价指标(先考虑单个样本在所有标签上的表现,然后对多个样本取平均,不常用)
- 所有样本的评价指标(直接将所有标签的在所有样本上的表现)
- 基于标签的评价指标(先考虑单个标签在所有样本上的表现,然后对多个标签取平均)
所有样本的评价指标
Precision, Recall, F值(单标签学习中精准率,召回率,F值的天然拓展)
Niq :第i个标签预测正确的图片个数,Nip:第i个标签预测的图片的个数,Nig:第i个标签正确的图片的个数,
基于标签的评价指标
Precision, Recall, F值(单标签学习中精准率,召回率,F值的天然拓展)
mAP(mean Average Precision)
P:precision,精确率的扩展(是由单个样本的标签相关度排序决定的,与上面三个精确率含义都不同)|{yj2|rankf(xi,yj2)≤rankf(xi,yj1),yj2∈ X}|
AP:average precision,每一类别P值的平均值
MAP:mean average precision,对所有类别的AP取均值
其中rankf(xi,yj)表示f(.,.)对Y中所有标签进行)进行降序排序,给个排名,最后返回的是yj标签在这个列表中的一个排名,排名越大,相关性越小。
学习算法
1.三种策略(基于标签之间的关系)
多标签学习的主要难点在于输出空间的爆炸增长,比如20个标签,输出空间就有2^20,为了应对指数复杂度的标签空间,需要挖掘标签之间的相关性。比方说,一个图像被标注的标签有热带雨林和足球,那么它具有巴西标签的可能性就很高。一个文档被标注为娱乐标签,它就不太可能和政治相关。有效的挖掘标签之间的相关性,是多标签学习成功的关键。根据对相关性挖掘的强弱,可以把多标签算法分为三类。
- 一阶策略:忽略和其它标签的相关性,比如把多标签分解成多个独立的二分类问题(简单高效)。
- 二阶策略:考虑标签之间的成对关联,比如为相关标签和不相关标签排序。
- 高阶策略:考虑多个标签之间的关联,比如对每个标签考虑所有其它标签的影响(效果最优)。
2.两种方法(基于如何将多标签分类与当前算法结合起来)
- 改造数据适应算法:常用的比如将多个类别合并成单个类别,这样会导致类别数量过
- 改造算法适应数据:常用比如正常输出q维数据,将其中softmax回归改为sigmoid函数,最终将f(.)大于阈值的结果输出出来。
3.Multi-label CNN(VGG,ResNet101)
这是标准的CNN模型,不考虑任何标签依赖性,属于一阶策略,以下都属于高阶策略。
4.label embedding
label embedding不是一整个网络,而是网络中用于处理标签之间联系的网络一部分。
 (a)
(a)  (b)
(b)
(a) one hot encoding (b)embedding
神经网络分析
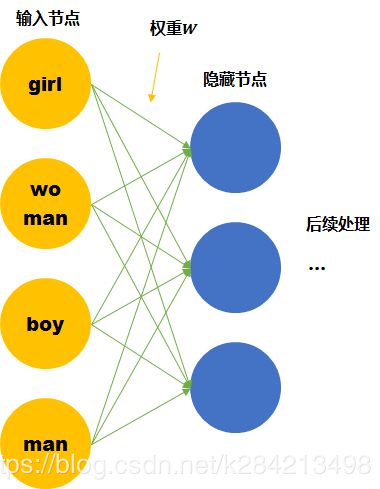
假设我们的词汇只有4个,girl, woman, boy, man,下面就思考用两种不同的表达方式会有什么区别。
One hot representation
尽管我们知道他们彼此的关系,但是计算机并不知道。在神经网络的输入层中,每个单词都会被看作一个节点。 而我们知道训练神经网络就是要学习每个连接线的 权重。如果只看第一层的权重,下面的情况需要确定43个连接线的关系,因为每个维度都彼此独立,girl的数据不会对其他单词的训练产生任何帮助,训练所需要的数据量,基本就固定在那里了。
我们这里手动的寻找这四个单词之间的关系 f 。可以用两个节点去表示四个单词。每个节点取不同值时的意义如下表。 那么girl就可以被编码成向量[0,1],man可以被编码成[1,1](第一个维度是gender,第二个维度是age)。

那么这时再来看神经网络需要学习的连接线的权重就缩小到了23。同时,当送入girl为输入的训练数据时,因为它是由两个节点编码的。那么与girl共享相同连接的其他输入例子也可以被训练到(如可以帮助到与其共享female的woman,和child的boy的训练)。
总得来说,label embedding也就是要达到第二个神经网络所表示的结果,降低训练所需要的数据量。
label embedding就是要从数据中自动学习到输入空间到Distributed representation空间的 映射f 。
5.CNN+RNN(CNN-LSTM)
网络框架主要分为cnn和rnn两个部分,cnn负责提取图片中的语义信息,rnn负责建立image/label关系和label dependency的模型。
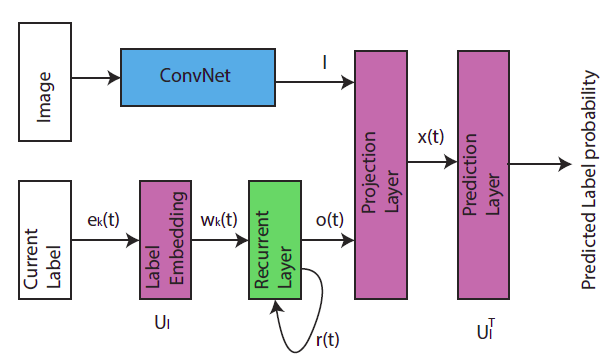 网络模型
网络模型
另外,在识别不同的object的时候,RNN会将attention转移到不同的地方,如下图:

本文两个类别,“zebra” and “elephant”,在预测zebra时,我们发现网络将attention集中到zebra那块。
这是一个考虑全局级别的标签依赖性,属于高阶策略。
6.RLSD
RLSD 在CNN-RNN的基础上,加入了区域潜在语义依赖关系,考虑到图像的位置信息和标签之间的相关性,对算法进行进一步优化。
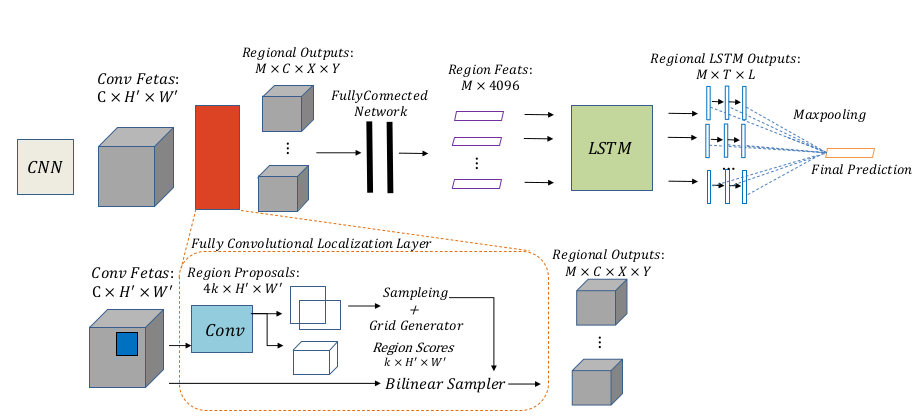 RLSD神经网络
RLSD神经网络
6.HCP
HCP的基本思想是,首先提取图像中的候选区域(基本上是上百个),然后对每个候选区域进行分类,最后使用 cross-hypothesis max-pooling 将图像中所有的候选区域分类结果进行融合,得到整个图像的多类别标签,其中也利用到了attention机制,如下图:
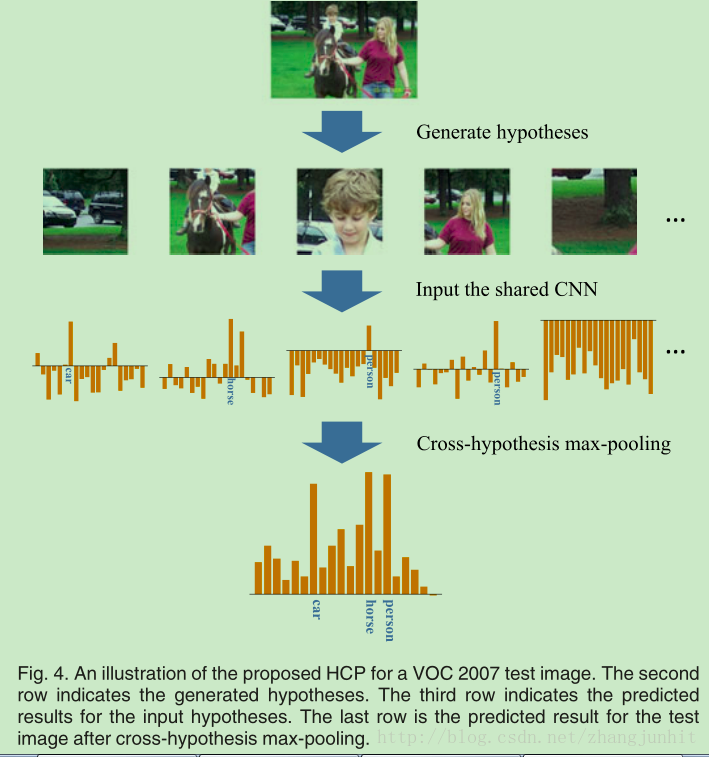
attention机制:像car,person,horse权重大,注意力比较高。这样做的好处是我们在训练图片时不需要加入位置信息,该算发会框出很多个框,自动调节相关标签的框权值更大,达到减弱噪音的目的。
总结
1.目前存在的问题
目前多标签分类依然存在单标签分类,目标检测的问题,如遮挡,小物体识别
另外由于标签相对多存在的问题有要分类的可能性随类别呈指数性增长,rank,样本分布不均
2.应用领域
图像搜索,图像和视频的语义标注
2.研究发展方向
从整体上来看,multi-label classification 由于涉及到多个标签,所以需要对图片和标签了解的信息量更多,意味着要分类的可能性呈指数型增长。
为了减少这种分类的可能性,需要考虑标签与标签,标签与图片之间的联系来降低信息量。
- 第一 涉及到标签与标签之间的关系,也就是NLP里词语与词语之间的联系,这个是语义层次上的
- 第二 涉及到标签与图片之间的关系 ,就是标签与图片特征之间的联系,常用的是attention机制
multi-label image classification:多标签图像分类总结的更多相关文章
- 多标签图像分类任务的评价方法-mAP
http://blog.sina.com.cn/s/blog_9db078090102whzw.html 多标签图像分类(Multi-label Image Classification)任务中图片的 ...
- Chapter 5. Label and Entry Widgets 标签和输入部件
Chapter 5. Label and Entry Widgets 标签和输入部件 有时候,你需要用户输入特定的信息,比如他们的名字,地址或者 甚至序号. 简单的方式来实现这个是使用Enry 部件 ...
- Multi label 多标签分类问题(Pytorch,TensorFlow,Caffe)
适用场景:一个输入对应多个label,或输入类别间不互斥 调用函数: 1. Pytorch使用torch.nn.BCEloss 2. Tensorflow使用tf.losses.sigmoid_cro ...
- Label Propagation Algorithm LPA 标签传播算法解析及matlab代码实现
转载请注明出处:http://www.cnblogs.com/bethansy/p/6953625.html LPA算法的思路: 首先每个节点有一个自己特有的标签,节点会选择自己邻居中出现次数最多的标 ...
- TinyMind 多标签图像分类竞赛 之路
竞赛传送门:https://www.tinymind.cn/competitions/42 我们就是傻狗天仙配啦~ 决赛排行榜: 这次比赛感谢第一名的 baseline:https://blog.cs ...
- keras multi-label classification 多标签分类
问题:一个数据又多个标签,一个样本数据多个类别中的某几类:比如一个病人的数据有多个疾病,一个文本有多种题材,所以标签就是: [1,0,0,0,1,0,1] 这种高维稀疏类型,如何计算分类准确率? 分类 ...
- iOS系列 基础篇 06 标签和按钮 (Label & Button)
iOS系列 基础篇 06 标签和按钮 (Label & Button) 目录: 标签控件 按钮控件 小结 标签和按钮是两个常用的控件,下面咱们逐一学习. 1. 标签控件 使用Single Vi ...
- kubernetes label 标签使用
查看node的标签kubectl get node --show-labels 删除标签kubectl label nodes node5 storagenode- 设置标签kubectl label ...
- label 标签的用法,点label选中单选、复选框或文本框
<label>拥有的权限</label> <label class="checkbox" id="privilege_id" st ...
随机推荐
- python中一些传参事情
#一个参数的传参 def hello(a): print(a+'王彦军你好')hello('hello')''' #2个参数的 def ab(a,b): print(a+'你好') ...
- linux网络编程基础--(转自网络)
转自 http://www.cnblogs.com/MyLove-Summer/p/5215287.html Linux下的网络编程指的是socket套接字编程,入门比较简单. 1. socket套接 ...
- Intellij Idea 解决字符乱码、设定颜色主题、字体
1.写入字符编码设置 2.调整mintty 字体.主题
- 小白的首个maven web项目Step1软件安装三(8.0.15mysql及workbench安装)
直接先开始下 MySQL 和 Workbench(mysql的可视化工具) ,注意下得是镜像版 .msi 后缀的 (mysql是纯控制面板的呈现方式,想要界面化操作可以装可视化工具,这里我装的是wor ...
- Windows Server 2008 R2 服务器系统安装及配置全过程图文详解
前言 本文主要介绍了 windows Server 2008 R2 服务器系统的安装及相关配置. 介绍的是以优盘的方式安装. 写这篇博文的目的一来是为了供有需要的网友参考, 二来自己也在此做个记载. ...
- java_jsp和servlet中乱码问题
- mpeg4文件分析(纯c解析代码)
参考链接: 1. MPEG4码流的帧率计算 https://blog.csdn.net/littlebee90/article/details/68924690 2. M ...
- SSH整合后tomcat启动报错SEVERE: Exception starting filter struts2 java.lang.NoClassDefFoundError: org/objectweb/asm/ClassVisitor
错误信息: SEVERE: Exception starting filter struts2 java.lang.NoClassDefFoundError: org/objectweb/asm/C ...
- angular.js 渲染
angular.js 小常识 具体看代码,转载请备注来源. html结构 <%@ page language="java" contentType="text/ ...
- Node.js和html数据交互(一) form表单
一.form表单提交数据 数据流向:前端 - > 后端 1.get方法 (action是提交路径,method是提交方法,get方法可以不写) 前端: <form action=" ...