HBase之八--(1):HBase二级索引的设计(案例讲解)
摘要
最近做的一个项目涉及到了多条件的组合查询,数据存储用的是HBase,恰恰HBase对于这种场景的查询特别不给力,一般HBase的查询都是通过RowKey(要把多条件组合查询的字段都拼接在RowKey中显然不太可能),或者全表扫描再结合过滤器筛选出目标数据(太低效),所以通过设计HBase的二级索引来解决这个问题
查询需求
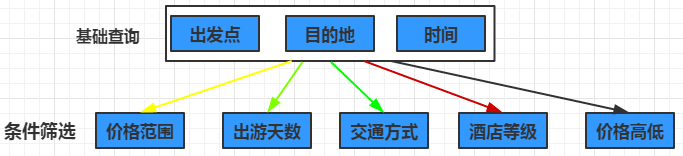
多个查询条件构成多维度的组合查询,需要根据不同组合查询出符合查询条件的数据
HBase的局限性
HBase本身只提供基于行键和全表扫描的查询,而行键索引单一,对于多维度的查询困难(如:对于价格+天数+酒店+交通的多条件组合查询困难),全表扫描效率低下。
二级索引的设计
设计思路
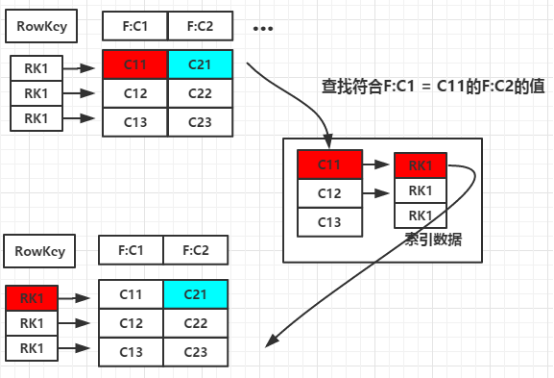
(图1)设计思路
二级索引的本质就是建立各列值与行键之间的映射关系
如(图1),当要对F:C1这列建立索引时,只需要建立F:C1各列值到其对应行键的映射关系,如C11->RK1等,这样就完成了对F:C1列值的二级索引的构建,当要查询符合F:C1=C11对应的F:C2的列值时(即根据C1=C11来查询C2的值,图1青色部分)其查询步骤如下: 1. 根据C1=C11到索引数据中查找其对应的RK,查询得到其对应的RK=RK1 2. 得到RK1后就自然能根据RK1来查询C2的值了 这是构建二级索引大概思路,其他组合查询的联合索引的建立也类似。
逻辑视图
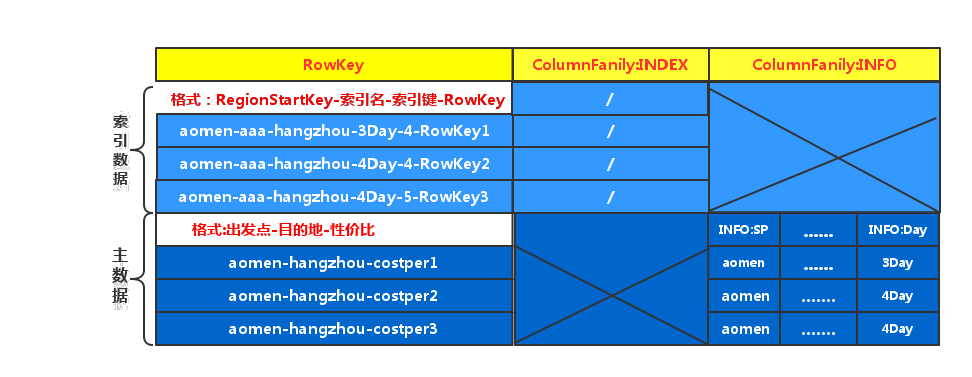
(图2) 部分数据在HBase中存储的逻辑视图
表中有两个列族,其中一个是列族INDEX,其并不存储任何的数据,仅仅是为了将索引数据与主数据分开存储(因为在HBase中同一列族的数据会被压缩在一起存储),索引数据的行键格式为:RegionStartKey-索引名-索引键-Rowkwy,其他RegionStartKey就是出发点,因为在创建HBase表时就对表根据出发点进行了预分区,索引键为主数据中某列(可能是多列)的列值,Rowkey对应主数据的行键;主数据的行键格式为:出发点-目的地-性价比,所以在存储数据时,同一出发点 目的地的数据默认是按性价比排序的;索引数据的行键和主数据的行键的前缀都是出发点,所以在存储时相同出发点的索引数据和主数据是存储在同一个Region中的,这样避免了在通过索引得到RK后又去其他Region上查询目标数据,提高了查询效率。
数据的查询过程
假设查询的条件:
出发点:澳门
目的地:杭州
出游天数:3天
酒店等级:4
其查询步骤如下:
首先根据查询条件来确定索引名,根据其查询条件为出游天数据 酒店等级确定索引名为aaa,这样就将查询的范围缩小在索引名为aaa的索引数据区内
根据出游天数的值为3天,酒店等级的值为4,结合Phoenix的模糊查询就能确定符合这两个查询条件的索引数据的行键
得到索引数据行键后就截取其最后的RowKey
最关键的Rowkey得到后就能轻易的获得其对应的列值了,整个查询过程就结束了。
对于其他更为复杂的组合查询的二级索引设计如类似。
缺点
需要额外的存储空间,属 一种以空间换时间的方式。
注意
1.将查询条件中的可选字段转换成数字能节省存储空间,如交通工具中的飞机,高铁,火车,轮船,汽车分别转换成5,4,3,2,1
2.将汉字转换成拼音才能保证数据按HBase的排序规则排序
3.如果数据量在百万级别以下可使用Phoenix(HBase的SQL查询引擎)模糊查询功能减少索引行键的设计
参考资料
apache kylin思路类似
HBase之八--(1):HBase二级索引的设计(案例讲解)的更多相关文章
- HBase二级索引的设计(案例讲解)
摘要 最近做的一个项目涉及到了多条件的组合查询,数据存储用的是HBase,恰恰HBase对于这种场景的查询特别不给力,一般HBase的查询都是通过RowKey(要把多条件组合查询的字段都拼接在RowK ...
- HBase二级索引的设计
摘要 最近做的一个项目涉及到了多条件的组合查询,数据存储用的是HBase,恰恰HBase对于这种场景的查询特别不给力,一般HBase的查询都是通过RowKey(要把多条件组合查询的字段都拼接在RowK ...
- HBase学习(四) 二级索引 rowkey设计
HBase学习(四) 一.HBase的读写流程 画出架构 1.1 HBase读流程 Hbase读取数据的流程:1)是由客户端发起读取数据的请求,首先会与zookeeper建立连接2)从zookeepe ...
- phoenix连接hbase数据库,创建二级索引报错:Error: org.apache.phoenix.exception.PhoenixIOException: Failed after attempts=36, exceptions: Tue Mar 06 10:32:02 CST 2018, null, java.net.SocketTimeoutException: callTimeou
v\:* {behavior:url(#default#VML);} o\:* {behavior:url(#default#VML);} w\:* {behavior:url(#default#VM ...
- hbase基于solr配置二级索引
一.概述 Hbase适用于大表的存储,通过单一的RowKey查询虽然能快速查询,但是对于复杂查询,尤其分页.查询总数等,实现方案浪费计算资源,所以可以针对hbase数据创建二级索引(Hbase Sec ...
- Phoneix(三)HBase集成Phoenix创建二级索引
一.Hbase集成Phoneix 1.下载 在官网http://www.apache.org/dyn/closer.lua/phoenix/中选择提供的镜像站点中下载与安装的HBase版本对应的版本. ...
- HBase的二级索引
使用HBase存储中国好声音数据的案例,业务描述如下: 为了能高效的查询到我们需要的数据,我们在RowKey的设计上下了不少功夫,因为过滤RowKey或者根据RowKey查询数据的效率是最高的,我们的 ...
- hbase构建二级索引解决方案
关注公众号:大数据技术派,回复"资料",领取1024G资料. 1 为什么需要二级索引 HBase的一级索引就是rowkey,我们仅仅能通过rowkey进行检索.假设我们相对Hbas ...
- [转]HBASE 二级索引
1.二级索引的核心思想是什么?2.二级索引由谁来管理?3.在主表中插入某条数据后,hbase如何将索引列写到索引表中去?4.scan查询的时候,coprocessor钩子的作用是什么?5.在split ...
随机推荐
- leetcode刷题1:两数之和two_sum
题目:(难度:Easy) 给定一个整数数组和一个目标值,找出数组中和为目标值的两个数. 你可以假设每个输入只对应一种答案,且同样的元素不能被重复利用. 示例: 给定 nums = [2, 7, 11, ...
- YARN作业提交流程剖析
YARN(MapReduce2) Yet Another Resource Negotiator / YARN Application Resource Negotiator对于节点数超出4000的大 ...
- excel比较筛选两列不一样的数据
在excel表中,罗列两列数据,用B列数据与A列比较,筛选出B列中哪些数据不同,并用红色标记出来. 首先选中B列.直接鼠标左键点击B列即可选中."开始"--->&qu ...
- 可编辑的div模仿文本框缓存(使用AUTOCOMPLETE属性,off是不缓存,on是缓存(默认))
用session实现的, 1.进当前页面就从session(a)中取( sessionStorage.getItem )(不管存在不存在,后续有合理的存储和删除); 2.离开当前页时删除这个sessi ...
- selenium与firefox版本不兼容
报错信息: org.openqa.selenium.firefox.NotConnectedException: Unable to connect to host 127.0.0.1 on port ...
- secureCRT如何设置眼睛舒适的颜色
1.会话选项 设置背景颜色 Options => Sessions options => Terminal => Emulation, 在 Terminal下拉列表下选择Linux, ...
- Spring_总结_03_装配Bean(二)_Java配置
一.前言 本文承接上一节:Spring_总结_03_装配Bean(一)之自动装配 上一节提到,装配Bean有三种方式,首先推荐自动装配.当自动装配行不通时,就需要采用显示配置的方式了. 显示配置有两种 ...
- 网络编程基础----并发编程 ---守护进程----同步锁 lock-----IPC机制----生产者消费者模型
1 守护进程: 主进程 创建 守护进程 辅助主进程的运行 设置进程的 daemon属性 p1.daemon=True 1 守护进程会在主进程代码执行结束后就终止: 2 守护进程内无法再开启子进程 ...
- uva11078 - Open Credit System(动态维护关键值)
这道题使用暴力解法O(n*n)会超时,那么用动态维护最大值可以优化到O(n).这种思想非常实用. #include<iostream> #include<cstdio> #in ...
- uva1636 - Headshot(条件概率)
简单的条件概率题,直接再来一枪没子弹的概率是所有子串”00“的数目除以‘0’的数目,随机转一下再打没子弹的概率是‘0’的数目除以总数目. #include<iostream> #inclu ...