Hive(十)【窗口函数】
一.定义
官网介绍:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+WindowingAndAnalytics
窗口函数属于sql中比较高级的函数,mysql从8.0版本才支持窗口函数,mysql5.6,5.7都有窗口函数,oracle 里面一直支持窗口函数,hive也支持窗口函数
窗口函数=函数+窗口
窗口:函数在运算时,我们可以指定函数运算的数据范围
Hive中以下函数是窗口函数:
窗口函数:
LEAD LEAD(col,n, default_val):往后第n行数据 col 列名 ;n 往后第几行 默认为1 ; 默认值 默认null
LAG LAG(col,n,default_val):往前第n行数据 ; col 列名 n 往前第几行 默认为1; 默认值 默认null
FIRST_VALUE 在当前窗口下的第一个值 FIRST_VALUE (col,true/false) 如果设置为true,则跳过空值。
LAST_VALUE 在当前窗口下的最后一个值 FIRST_VALUE (col,true/false)如果设置为true,则跳过空值。
标准聚合函数
- COUNT
- SUM
- MIN
- MAX
- AVG
分析排名函数
RANK() 排序相同时会重复,总数不会变
DENSE_RANK() 排序相同时会重复,总数会减少
ROW_NUMBER() 会根据顺序计算
NTILE():根据窗口排序,将数据分为n组,若查找前50%,则条件为n/2组
二.语法
(1)窗口函数 over([partition by 字段] [order by 字段] [ 窗口语句])
partition by 给查出来的结果集按照某个字段分区,分区以后,开窗的大小最大不会超过分区数据的大小
一旦分区之后,我们必须在单个分区内指定窗口。
order by 给分区内的数据按照某个字段排序
(2)窗口语句
(ROWS | RANGE) BETWEEN (UNBOUNDED | [num]) PRECEDING AND ([num] PRECEDING | CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING)
(ROWS | RANGE) BETWEEN CURRENT ROW AND (CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING)
(ROWS | RANGE) BETWEEN [num] FOLLOWING AND (UNBOUNDED | [num]) FOLLOWING
常见用法:rows between unbounded preceding and unbounded following
两种特殊情况
当指定ORDER BY缺少WINDOW子句时,WINDOW规范默认为RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW。
如果同时缺少ORDER BY和WINDOW子句,则WINDOW规范默认为ROW BETWEENUND UNBOUNDED PRECEDING和UNBOUNDED FOLLOWING。
三.需求练习一
需求说明
根据用户的消费记录统计一下需求
name orderdate cost
jack,2017-01-01,10
tony,2017-01-02,15
jack,2017-02-03,23
tony,2017-01-04,29
jack,2017-01-05,46
jack,2017-04-06,42
tony,2017-01-07,50
jack,2017-01-08,55
mart,2017-04-08,62
mart,2017-04-09,68
neil,2017-05-10,12
mart,2017-04-11,75
neil,2017-06-12,80
mart,2017-04-13,94
需求1: 查询在2017年4月份购买过的顾客及总人数
需求3: 查询顾客的购买明细及月购买总额
需求3: 上述的场景, 将每个顾客的cost按照日期进行累加
需求4: 查询顾客购买明细以及上次的购买时间和下次购买时间
需求5: 查询顾客每个月第一次的购买时间 和 每个月的最后一次购买时间
数据准备
消费记录数据:business.txt
jack,2017-01-01,10
tony,2017-01-02,15
jack,2017-02-03,23
tony,2017-01-04,29
jack,2017-01-05,46
jack,2017-04-06,42
tony,2017-01-07,50
jack,2017-01-08,55
mart,2017-04-08,62
mart,2017-04-09,68
neil,2017-05-10,12
mart,2017-04-11,75
neil,2017-06-12,80
mart,2017-04-13,94
建表
create table business(
name string,
orderdate string,
cost int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
导数据
load data local inpath "/opt/module/hive/datas/business.txt" into table business;
查询验证表数据
select * from business;
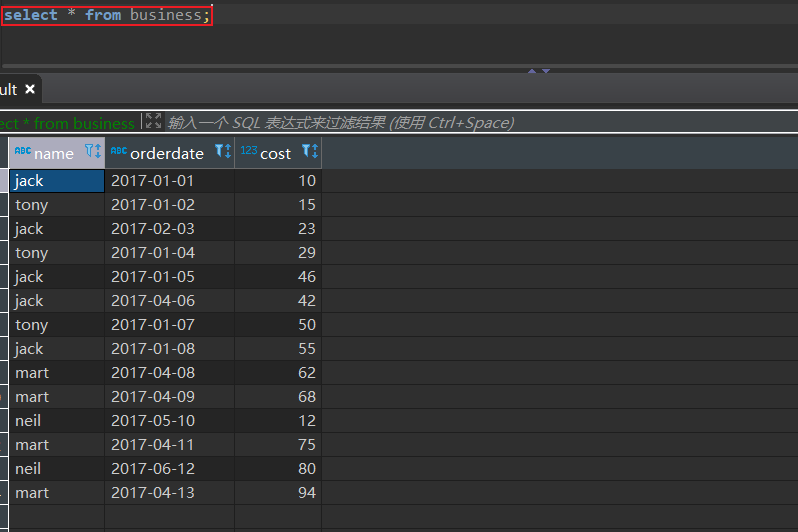
作为练习可以使用本地模式:set hive.exec.mode.local.auto=true;
count,sum
需求1
查询在2017年4月份购买过的顾客及总人数
select
name,
count(*) over()
from business
where substring(orderdate,1,7)='2017-04'
group by name;
结果

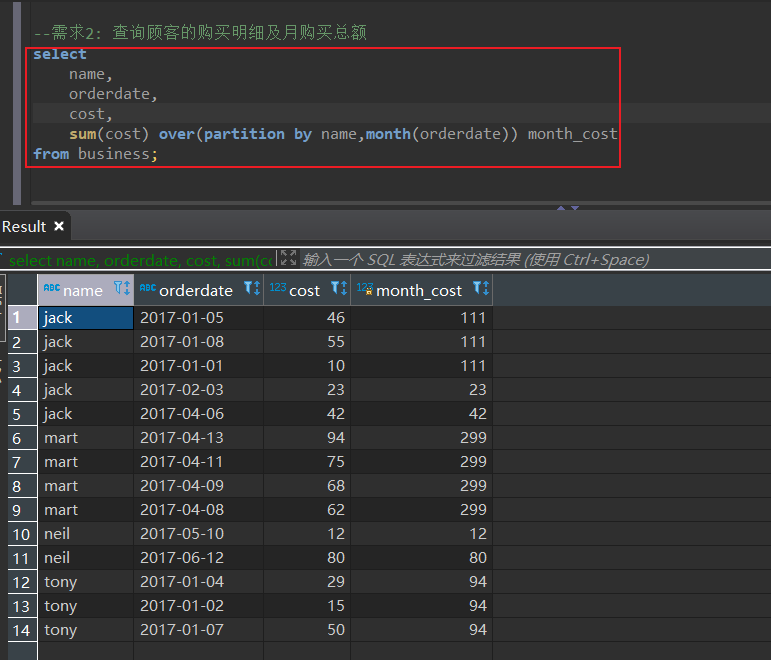
需求2
查询顾客的购买明细及月购买总额
select
name,
orderdate,
cost,
sum(cost) over(partition by name,month(orderdate)) month_cost
from business;
lag,lead
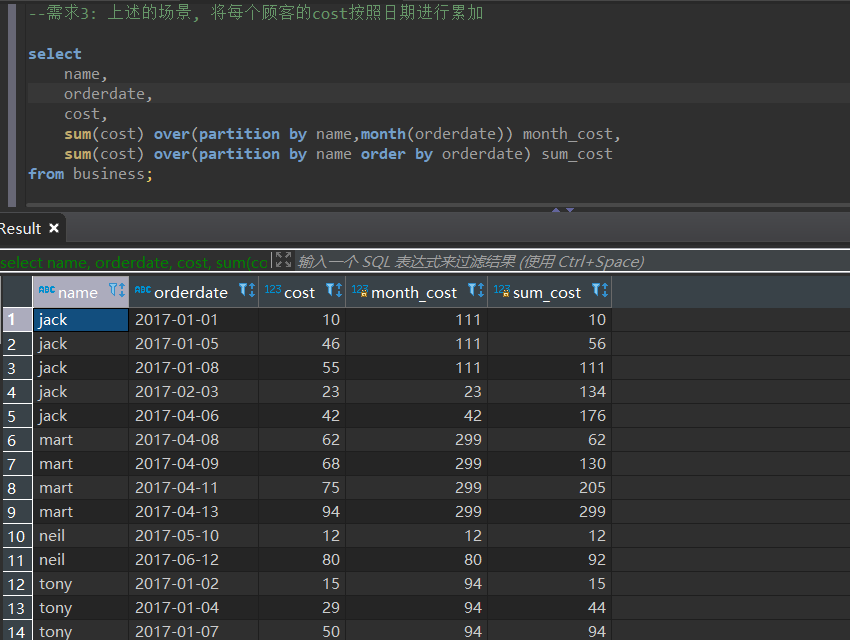
需求3
上述的场景,将每个顾客的cost按照日期进行累加
select
name,
orderdate,
cost,
sum(cost) over(partition by name,month(orderdate)) month_cost,
sum(cost) over(partition by name order by orderdate) sum_cost
from business;
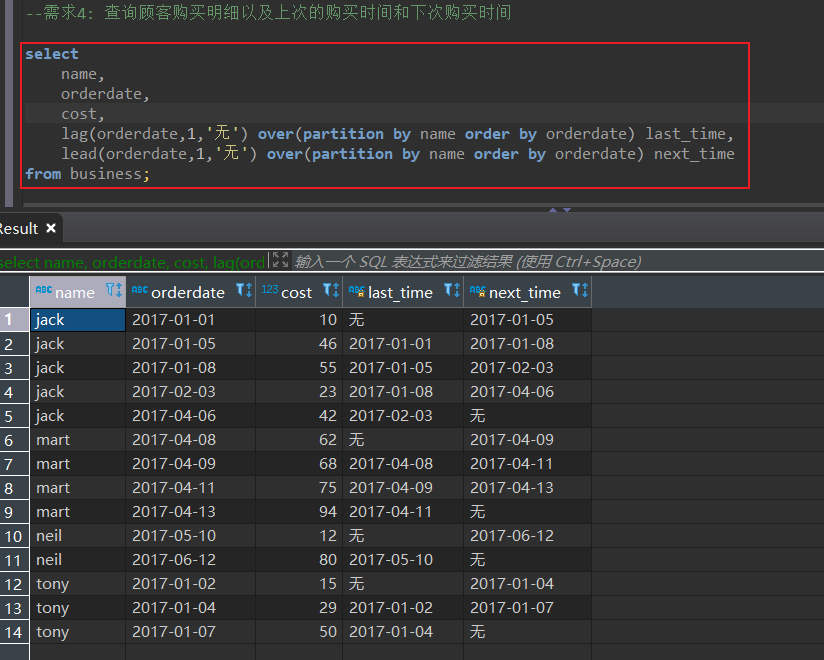
需求4
查询顾客购买明细以及上次的购买时间和下次购买时间
select
name,
orderdate,
cost,
lag(orderdate,1,'无') over(partition by name order by orderdate) last_time,
lead(orderdate,1,'无') over(partition by name order by orderdate) next_time
from business;
first_value,last_value
需求5
注意:LAST_VALUE和FIRST_VALUE 需要自定义windows字句,否则出现错误
select
name,
orderdate,
first_value(orderdate,false) over(partition by name order by orderdate rows between UNBOUNDED PRECEDING and UNBOUNDED FOLLOWING) first_time,
last_value(orderdate,false) over(partition by name order by orderdate rows between UNBOUNDED PRECEDING and UNBOUNDED FOLLOWING ) last_time
from business;

四.需求练习二
需求说明
计算成绩排名
name subject score
孙悟空 语文 87
孙悟空 数学 95
孙悟空 英语 68
大海 语文 94
大海 数学 56
大海 英语 84
宋宋 语文 64
宋宋 数学 86
宋宋 英语 84
婷婷 语文 65
婷婷 数学 85
婷婷 英语 78
数据准备
原始数据:score.txt
孙悟空 语文 87
孙悟空 数学 95
孙悟空 英语 68
大海 语文 94
大海 数学 56
大海 英语 84
宋宋 语文 64
宋宋 数学 86
宋宋 英语 84
婷婷 语文 65
婷婷 数学 85
婷婷 英语 78
建表
create table score(
name string,
subject string,
score int)
row format delimited fields terminated by "\t";
导数据
load data local inpath '/opt/module/hive/datas/score.txt' into table score;
验证表数据
select * from score;
rank,dense_rank,row_number
需求1
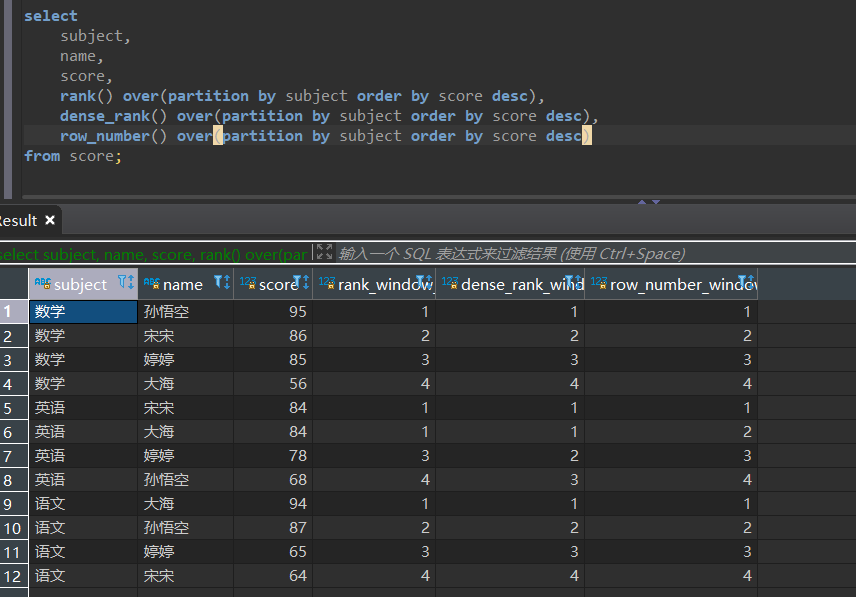
计算各科成绩排名
select
subject,
name,
score,
rank() over(partition by subject order by score desc),
dense_rank() over(partition by subject order by score desc),
row_number() over(partition by subject order by score desc)
from score;
ntile
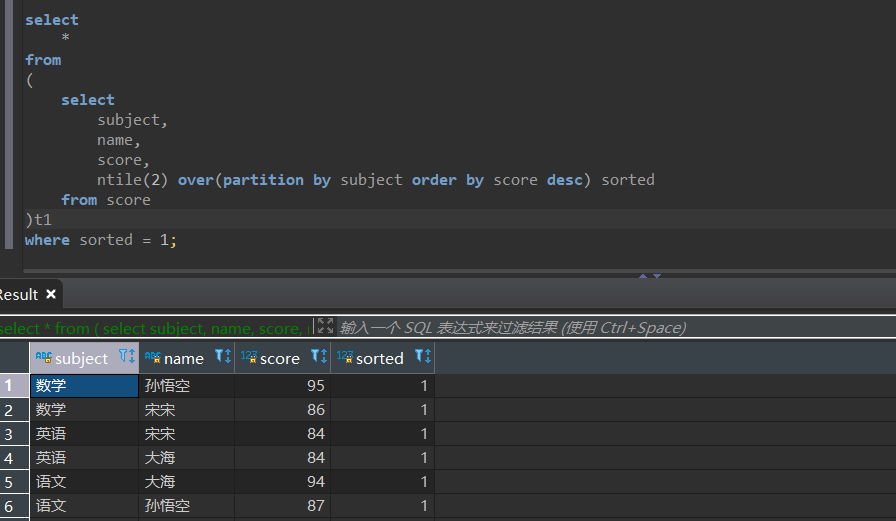
需求2
查看各科成绩前50%的学生成绩
select
*
from
(
select
subject,
name,
score,
ntile(2) over(partition by subject order by score desc) sorted
from score
)t1
where sorted = 1;
Hive(十)【窗口函数】的更多相关文章
- Hive分析窗口函数(一) SUM,AVG,MIN,MAX
Hive分析窗口函数(一) SUM,AVG,MIN,MAX Hive分析窗口函数(一) SUM,AVG,MIN,MAX Hive中提供了越来越多的分析函数,用于完成负责的统计分析.抽时间将所有的分析窗 ...
- 【Hadoop离线基础总结】hive的窗口函数
hive的窗口函数 概述 hive中一般求取TopN时就需要用到窗口函数 专业窗口函数一般有三个 rank() over dense rank() over row_number() over 实例 ...
- Hive学习之路 (十六)Hive分析窗口函数(四) LAG、LEAD、FIRST_VALUE和LAST_VALUE
数据准备 数据格式 cookie4.txt cookie1, ::,url2 cookie1, ::,url1 cookie1, ::,1url3 cookie1, ::,url6 cookie1, ...
- Hive学习之路 (十五)Hive分析窗口函数(三) CUME_DIST和PERCENT_RANK
这两个序列分析函数不是很常用,这里也练习一下. 数据准备 数据格式 cookie3.txt d1,user1, d1,user2, d1,user3, d2,user4, d2,user5, 创建表 ...
- Hive学习之路 (十四)Hive分析窗口函数(二) NTILE,ROW_NUMBER,RANK,DENSE_RANK
概述 本文中介绍前几个序列函数,NTILE,ROW_NUMBER,RANK,DENSE_RANK,下面会一一解释各自的用途. 注意: 序列函数不支持WINDOW子句.(ROWS BETWEEN) 数据 ...
- hive之窗口函数
窗口函数 1.相关函数说明 COVER():指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变而变化 CURRENT ROW:当前行 n PRECEDING:往前n行数据 n FOLLO ...
- hive的窗口函数1
Hive中提供了越来越多的分析函数,用于完成负责的统计分析.抽时间将所有的分析窗口函数理一遍,将陆续发布.今天先看几个基础的,SUM.AVG.MIN.MAX.用于实现分组内所有和连续累积的统计. 1. ...
- 【Hive】窗口函数
我们都知道在sql中有一类函数叫做聚合函数,例如sum().avg().max()等等, 这类函数可以将多行数据按照规则聚集为一行,一般来讲聚集后的行数是要少于聚集前的行数的. 但是有时我们想要既显示 ...
- hive 中窗口函数row_number,rank,dense_ran,ntile分析函数的用法
hive中一般取top n时,row_number(),rank,dense_ran()这三个函数就派上用场了, 先简单说下这三函数都是排名的,不过呢还有点细微的区别. 通过代码运行结果一看就明白了. ...
随机推荐
- (转载)gcc -l参数和-L参数
-l参数就是用来指定程序要链接的库,-l参数紧接着就是库名,那么库名跟真正的库文件名有什么关系呢?就拿数学库来说,他的库名是m,他的库文件名是libm.so,很容易看出,把库文件名的头lib和尾.so ...
- cf12E Start of the season(构造,,,)
题意: 给一个偶数N. 构造出一个矩阵. 满足:主对角线上全为0.每一行是0~N-1的一个全排列.矩阵关于主对角线对称. 思路: 觉得是智商题,,,,看完题解后觉得不难,但是我就是没想出来.只想到了前 ...
- sed 替换命令使用
输入文件不会被修改,sed 只在模式空间中执行替换命令,然后输出模式空间的内容.文本文件 employee.txt 101,John Doe,CEO 102,Jason Smith,IT Manage ...
- CSS px的理解
px是像素.然而一个屏幕像素的多少是由屏幕的分辨率决定的. 取个极端的栗子:如果分辨率是1w*1w,你设置一个100px宽的输入框,你只占屏幕的1/100,但是如果屏幕的分辨率是100*100,那么你 ...
- TDSQL | 在整个技术解决方案中HTAP对应的混合交易以及分析系统应该如何实现?
从主交易到传输,到插件式解决方案,每个厂商对HTAP的理解和实验方式都有自己的独到解法,在未来整个数据解决方案当中都会往HTAP中去牵引.那么在整个技术解决方案中HTAP对应的混合交易以及分析系统应该 ...
- TypeScript 泛型及应用
TypeScript 泛型及应用 一.泛型是什么 二.泛型接口 三.泛型类 四.泛型约束 4.1 确保属性存在 4.2 检查对象上的键是否存在 五.泛型参数默认类型 六.泛型条件类型 七.泛型工具类型 ...
- Obsidian中如何记录自己的灵感?
在生活中当中你是否会在某个瞬间产生一个想法,但没过多久就想不起来了,正所谓灵感转瞬即逝,那我们不妨在灵感出现的时候顺手将他记录下来.记录的过程要求简单.方便且不会花费我们太多时间,下面我们介绍一下如何 ...
- tabulate
ValueError: headers for a list of dicts is not a dict or a keyword from: https://bitbucket.org/astan ...
- 手把手教你基于Netty实现一个基础的RPC框架(通俗易懂)
阅读这篇文章之前,建议先阅读和这篇文章关联的内容. [1]详细剖析分布式微服务架构下网络通信的底层实现原理(图解) [2][年薪60W的技巧]工作了5年,你真的理解Netty以及为什么要用吗?(深度干 ...
- jenkins内置变量的使用
参考链接: https://www.cnblogs.com/puresoul/p/4828913.html 一.查看Jenkins有哪些环境变量 1.新建任意一个job 2.增加构建步骤:Execu ...