爬取千千小说 -- xpath
今天以其中一本小说为例,讲一下下载小说的主体部分,了解正常的爬取步骤,用到的是request和xpath。
爬取数据三步走:访问url --》爬取数据 --》保存数据
一、访问千千小说网址: https://www.qqxsnew.com/
二、随便选一部小说,打开章节目录界面(比方说魔道祖师):https://www.qqxsnew.com/18/18991/
三、开始编写代码。
a. 利用request访问网页,是get请求还是post请求要看网页上面写的是啥
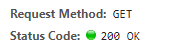 右击检查,选择network,随便找个页面,看下request Method方法是什么。
右击检查,选择network,随便找个页面,看下request Method方法是什么。
url = "https://www.qqxsnew.com/18/18991/"
html = requests.get(url, headers=headers).text
b. 得到网页的html页面(html页面 == 在网页鼠标右击“查看网页源代码”),获取章节名字和章节链接。
章节名字和章节链接获取需要用到XPath --》在网页鼠标右击检查 --》定位到任意章节(如第一章)--》copy --》copy XPath --》 //*[@id="list"]/dl/dd[13]/a

如果安装过XPath插件的话,可以将上面复制的XPath在插件里面查询,可以看到只查询到了一个

我们的目的是获取到所有章节的名字和链接,分析上面XPath的字串,发现dd[13]这个地方是定位,每个dd都是一个章节,所以我们模糊定位看看

咦,可以看出来dd里面的内容都出来了,但是前面12章的内容不是我们需要的,我们要的是从第一章开始,所以需要把它们过滤掉,position是一个定位的函数,大于12是说从第13位开始,也就是第一章

这数据正好是我们想要提取的文字,所以我们已经得到了文字提取的XPath字串://*[@id="list"]/dl/dd[position()>12]/a
文字和链接都在a标签里面,链接在href属性里面,所以链接的XPath字串://*[@id="list"]/dl/dd[position()>12]/a/@href

好了,前面是在分析XPath字串是怎么得到的,如果自己对XPath语法熟的话,也可以自己写提取字串,然后用插件去验证,或者直接用代码验证都是可以的。现在我们把它放到代码中去
# 获取a标签对象
chapter_titles_obj = datas.xpath('//*[@id="list"]/dl/dd[position()>12]/a')
for chapter_title_obj in chapter_titles_obj:
# 获取a标签文本
chapter_title_text = chapter_title_obj.xpath('./text()')[0]
# 获取a标签的链接
chapter_url = chapter_title_obj.xpath('./@href')[0]
打印出来看看结果
c. 每个章节的链接都拿到了,接下来就是请求了,这个不多说,和上面请求的方法一样,XPath获取方法也相同。

d. 存储获取到的数据
for content_chapter_text in content_chapter:
print(content_chapter_text)
with open("魔道祖师/" + chapter_title_text + ".txt", 'a', encoding='utf-8') as f:
f.write(content_chapter_text)
这样,一篇小说从访问到下载的过程就结束了。
完整代码
#!/usr/bin/env python
# _*_ coding: UTF-8 _*_
"""=================================================
@Project -> File : six-dialog_design -> qianqian.py
@IDE : PyCharm
@Author : zihan
@Date : 2020/5/25 14:50
@Desc :
================================================="""
import requests
from lxml import etree headers = {
'User-Agent': ""
} def main():
url = "https://www.qqxsnew.com/18/18991/"
html = requests.get(url, headers=headers).text
datas = etree.HTML(html)
chapter_titles_obj = datas.xpath('//*[@id="list"]/dl/dd[position()>12]/a')
for chapter_title_obj in chapter_titles_obj:
chapter_title_text = chapter_title_obj.xpath('./text()')[0]
chapter_url = chapter_title_obj.xpath('./@href')[0]
chapter_url = "https://www.qqxsnew.com" + chapter_url # 对每一章的链接发送请求
html_chapter = requests.get(chapter_url, headers=headers).text
datas_chapter = etree.HTML(html_chapter)
content_chapter = datas_chapter.xpath('//*[@id="content"]/text()')
print(chapter_title_text, "开始下载")
for content_chapter_text in content_chapter:
print(content_chapter_text)
with open("魔道祖师/" + chapter_title_text + ".txt", 'a', encoding='utf-8') as f:
f.write(content_chapter_text) if __name__ == '__main__':
main()
OK。如果想要批量下载,或者选择下载等,只是改变url而已,了解主体方法后,这些都不难。
爬取千千小说 -- xpath的更多相关文章
- 如何用python爬虫从爬取一章小说到爬取全站小说
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取http ...
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- python之如何爬取一篇小说的第一章内容
现在网上有很多小说网站,但其实,有一些小说网站是没有自己的资源的,那么这些资源是从哪里来的呢?当然是“偷取”别人的数据咯.现在的问题就是,该怎么去爬取别人的资源呢,这里便从简单的开始,爬取一篇小说的第 ...
- 爬虫入门(四)——Scrapy框架入门:使用Scrapy框架爬取全书网小说数据
为了入门scrapy框架,昨天写了一个爬取静态小说网站的小程序 下面我们尝试爬取全书网中网游动漫类小说的书籍信息. 一.准备阶段 明确一下爬虫页面分析的思路: 对于书籍列表页:我们需要知道打开单本书籍 ...
- scrapy进阶(CrawlSpider爬虫__爬取整站小说)
# -*- coding: utf-8 -*- import scrapy,re from scrapy.linkextractors import LinkExtractor from scrapy ...
- Python的scrapy之爬取6毛小说网的圣墟
闲来无事想看个小说,打算下载到电脑上看,找了半天,没找到可以下载的网站,于是就想自己爬取一下小说内容并保存到本地 圣墟 第一章 沙漠中的彼岸花 - 辰东 - 6毛小说网 http://www.6ma ...
- 使用scrapy爬取金庸小说目录和章节url
刚接触使用scrapy的时候,如果一开始就想实现特别复杂的配置,显然是不太现实的,用一些小的例子可以帮助自己理解各个模块. 今天的目标:爬取http://www.luoxia.com/shendiao ...
- 网络字体反爬之pyspider爬取起点中文小说
前几天跟同事聊到最近在看什么小说,想起之前看过一篇文章说的是网络十大水文,就想把起点上的小说信息爬一下,搞点可视化数据看看.这段时间正在看爬虫框架-pyspider,觉得这种网站用框架还是很方便的,所 ...
- 使用requests+BeautifulSoup爬取龙族V小说
这几天想看龙族最新版本,但是搜索半天发现 没有网站提供 下载, 我又只想下载后离线阅读(写代码已经很费眼睛了).无奈只有自己 爬取了. 这里记录一下,以后想看时,直接运行脚本 下载小说. 这里是从 ...
- 爬虫入门实例:利用requests库爬取笔趣小说网
w3cschool上的来练练手,爬取笔趣看小说http://www.biqukan.com/, 爬取<凡人修仙传仙界篇>的所有章节 1.利用requests访问目标网址,使用了get方法 ...
随机推荐
- 安全Web服务器
https协议: 443 端口 虚拟Server0: 1.部署 网站证书(营业执照)# cd /etc/pki/tls/certs/ # wget http://classroom.example.c ...
- 【NX二次开发】Block UI 微定位
属性说明 属性 类型 描述 常规 BlockID String 控件ID Enable Logical 是否可操作 Group ...
- DB2 SQL0805N解决和思考
一.报错现象 这是一个在使用 DB2数据库过程中比较常见的错误, 报错信息如下 Exception stack trace: com.ibm.db2.jcc.am.SqlException: DB2 ...
- csp-s模拟测试49(9.22)养花(分块/主席树)·折射(神仙DP)·画作
最近有点头晕........... T1 养花 考场我没想到正解,后来打的主席树,对于每个摸数查找1-(k-1),k-(2k-1)...的最大值,事实上还是很容易被卡的但是没有数据好像还比较友善, 对 ...
- 可扩展的 Web 架构与分布式系统
作者:Kate Matsudaira 译者:尹星 本文介绍了分布式架构是如何解决系统扩展性问题的粗略方法,适合刚刚入门分布式系统的同学,我把整篇文章翻译如下,希望给你一些启发. 备注:[idea]标注 ...
- .NET解密得到UnionID
由于微信没有提供.NET的解码示例代码,自己搜索写了一个,下面的代码是可用的 var decryptBytes = Convert.FromBase64String(encrypdata); var ...
- 19、lnmp_mysql、nfs组件分离
19.1.LNMP一体机的数据库分离成独立的数据库: 1.根据以上学习过的方法在db01服务器上安装独立的mysql数据库软件: 2.在web01服务器上导出原先的数据库: [root@web01 t ...
- centos 8.3安装 一键安装部署gitlab
安装和配置gitlab必须的依赖包 [root@gitlabdev ~]#dnf install -y curl policycoreutils openssh-server perl 设置开机自启s ...
- 010_Mybatis简介
目录 Mybatis简介 什么是 MyBatis? 如何获得Mybatis 持久化 持久层 为什么需要Mybatis 第一个Mybatis程序 搭建环境 建库建表 新建父工程 新建普通maven项目 ...
- Centos-Springboot项目jar包自启动
CentOS环境下部署Springboot项目的jar包开机自启动. 部署环境 Centos 7.5 Springboot 2.1.x 操作步骤 修改pom 在pom.xml文件中<plugin ...