[Scikit-learn] 1.1 Generalized Linear Models - Bayesian Ridge Regression
1.1.10. Bayesian Ridge Regression
首先了解一些背景知识:from: https://www.r-bloggers.com/the-bayesian-approach-to-ridge-regression/
In this post, we are going to be taking a computational approach to demonstrating the equivalence of the bayesian approach and ridge regression.
From: 文本语言模型的参数估计-最大似然估计、MAP及贝叶斯估计
三类参数估计方法:最大似然估计MLE、最大后验概率估计MAP、贝叶斯估计。
最大似然估计MLE
关键:写出似然函数
最大后验概率估计MAP
最大后验估计与最大似然估计相似,不同点在于估计的函数中允许加入一个先验
,也就是说此时不是要求似然函数最大,而是要求由贝叶斯公式计算出的整个后验概率最大,即
注意这里P(X)与参数无关,因此等价于要使分子最大。与最大似然估计相比,现在需要多加上一个先验分布概率的对数。
【在样本足够大时,结果逼近MLE】
【加了先验没什么神秘的,效果很类似l正则项】
贝叶斯估计
贝叶斯估计是在MAP上做进一步拓展,此时不直接估计参数的值,而是允许参数服从一定概率分布。回顾一下贝叶斯公式
现在不是要求后验概率最大,这样就需要求,即观察到的evidence的概率,由全概率公式展开可得
当新的数据被观察到时,后验概率可以自动随之调整。但是通常这个全概率的求法是贝叶斯估计比较有技巧性的地方。
那么如何用贝叶斯估计来做预测呢?如果我们想求一个新值的概率,可以由
来计算。注意此时第二项因子在上的积分不再等于1,这就是和MLE及MAP很大的不同点。
我们仍然以扔硬币的伯努利实验为例来说明。和MAP中一样,我们假设先验分布为Beta分布,
但是构造贝叶斯估计时,
- 不是要求用后验最大时的参数来近似作为参数值,
- 而是求满足Beta分布的参数p的期望,有

注意这里用到了公式
当T为二维的情形可以对Beta分布来应用;T为多维的情形可以对狄利克雷分布应用
根据结果可以知道,根据贝叶斯估计,参数p服从一个新的Beta分布。回忆一下,我们为p选取的先验分布是Beta分布,然后以p为参数的二项分布用贝叶斯估计得到的后验概率仍然服从Beta分布,由此我们说二项分布和Beta分布是共轭分布。在概率语言模型中,通常选取共轭分布作为先验,可以带来计算上的方便性。最典型的就是LDA中每个文档中词的Topic分布服从Multinomial分布,其先验选取共轭分布即Dirichlet分布;每个Topic下词的分布服从Multinomial分布,其先验也同样选取共轭分布即Dirichlet分布。
根据Beta分布的期望和方差计算公式,我们有

可以看出此时估计的p的期望和MLE ,MAP中得到的估计值都不同,此时如果仍然是做20次实验,12次正面,8次反面,那么我们根据贝叶斯估计得到的p满足参数为12+5和8+5的Beta分布,其均值和方差分别是17/30=0.567, 17*13/(31*30^2)=0.0079。可以看到此时求出的p的期望比MLE和MAP得到的估计值都小,更加接近0.5。
结论:
综上所述我们可以可视化MLE,MAP和贝叶斯估计对参数的估计结果如下

个人理解是,从MLE到MAP再到贝叶斯估计,对参数的表示越来越精确【应该是表达越来越丰富,毕竟由一个值变为了一个分布,减少了推断过程中信息的损失】,得到的参数估计结果也越来越接近0.5这个先验概率,越来越能够反映基于样本的真实参数情况。【一般都用贝叶斯估计】
链接:https://www.zhihu.com/question/22007264/answer/20014371
过去的线性归回,比如使用最小二乘,其实就是相当于最大似然的感觉,容易overfitting。
采用了贝叶斯,假设了高斯分布,也就等价于Ridge Regression。
如果假设是拉普拉斯分布,就等价于LASSO。
Train:
>>> from sklearn import linear_model
>>> X = [[0., 0.], [1., 1.], [2., 2.], [3., 3.]]
>>> Y = [0., 1., 2., 3.]
>>> reg = linear_model.BayesianRidge()
>>> reg.fit(X, Y)
BayesianRidge(alpha_1=1e-06, alpha_2=1e-06, compute_score=False, copy_X=True,
fit_intercept=True, lambda_1=1e-06, lambda_2=1e-06, n_iter=300,
normalize=False, tol=0.001, verbose=False)
Predict:
>>> reg.predict ([[1, 0.]])
array([ 0.50000013])
Demo:
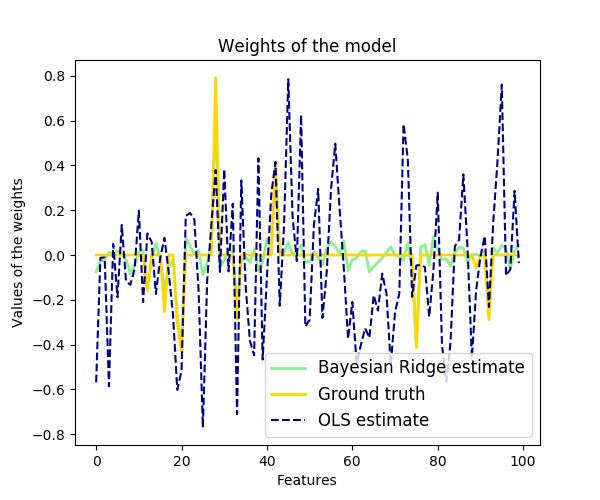
[Scikit-learn] 1.1 Generalized Linear Models - Bayesian Ridge Regression的更多相关文章
- [Scikit-learn] 1.5 Generalized Linear Models - SGD for Regression
梯度下降 一.亲手实现“梯度下降” 以下内容其实就是<手动实现简单的梯度下降>. 神经网络的实践笔记,主要包括: Logistic分类函数 反向传播相关内容 Link: http://pe ...
- Regression:Generalized Linear Models
作者:桂. 时间:2017-05-22 15:28:43 链接:http://www.cnblogs.com/xingshansi/p/6890048.html 前言 本文主要是线性回归模型,包括: ...
- Generalized Linear Models
作者:桂. 时间:2017-05-22 15:28:43 链接:http://www.cnblogs.com/xingshansi/p/6890048.html 前言 主要记录python工具包:s ...
- 广义线性模型(Generalized Linear Models)
前面的文章已经介绍了一个回归和一个分类的例子.在逻辑回归模型中我们假设: 在分类问题中我们假设: 他们都是广义线性模型中的一个例子,在理解广义线性模型之前需要先理解指数分布族. 指数分布族(The E ...
- Andrew Ng机器学习公开课笔记 -- Generalized Linear Models
网易公开课,第4课 notes,http://cs229.stanford.edu/notes/cs229-notes1.pdf 前面介绍一个线性回归问题,符合高斯分布 一个分类问题,logstic回 ...
- [Scikit-learn] 1.1 Generalized Linear Models - from Linear Regression to L1&L2
Introduction 一.Scikit-learning 广义线性模型 From: http://sklearn.lzjqsdd.com/modules/linear_model.html#ord ...
- [Scikit-learn] 1.5 Generalized Linear Models - SGD for Classification
NB: 因为softmax,NN看上去是分类,其实是拟合(回归),拟合最大似然. 多分类参见:[Scikit-learn] 1.1 Generalized Linear Models - Logist ...
- [Scikit-learn] 1.1 Generalized Linear Models - Logistic regression & Softmax
二分类:Logistic regression 多分类:Softmax分类函数 对于损失函数,我们求其最小值, 对于似然函数,我们求其最大值. Logistic是loss function,即: 在逻 ...
- Popular generalized linear models|GLMM| Zero-truncated Models|Zero-Inflated Models|matched case–control studies|多重logistics回归|ordered logistics regression
============================================================== Popular generalized linear models 将不同 ...
随机推荐
- springboot 学习小结
springboot 默认自动扫描和配置根包下面的类.如果启动配置不在根包目录下,得把对应的类进行配置扫描生成对应的bean. 主要的扫描注解有: @SpringBootApplication //s ...
- webpack中使用WebpackDevServer实现请求转发
index.html <!DOCTYPE html> <html lang="en"> <head> <meta charset=&quo ...
- [USACO07MAR]面对正确的方式Face The Right Way
题目概括 题目描述 Farmer John has arranged his N (1 ≤ N ≤ 5,000) cows in a row and many of them are facing f ...
- Maya cmds polyOptions() 获取和设置 mesh 的属性
Maya cmds polyOptions() 获取和设置 mesh 的属性 举例: cmds.polyOptions(dt = True) # 显示所有选择的 mesh 的三角化线(四边形的对角虚线 ...
- 算法设计与分析 - 李春葆 - 第二版 - pdf->word v3
1.1 第1章─概论 练习题 . 下列关于算法的说法中正确的有( ). Ⅰ.求解某一类问题的算法是唯一的 Ⅱ.算法必须在有限步操作之后停止 Ⅲ.算法的每一步操作必须是明确的,不能有歧义或含义模糊 Ⅳ. ...
- 新安装的Ubuntu如何切换到root的方法
Ubuntu中root用户和user用户的相互切换Ubuntu是最近很流行的一款Linux系统,因为Ubuntu默认是不启动root用户,现在介绍如何进入root的方法. (1)从user用户切 ...
- 2019牛客多校C Governing sand——桶&&思维题
题意 有 $n$ 种树,每种树都有高度 $H_i$,费用 $C_i$,数量 $P_i$,现要砍掉一些树,使得剩下的树中最高的树的数量超过一般,求最小的费用.($1 \leq n \leq 10^5, ...
- Nginx location规则匹配
^~ 标识符匹配后面跟-一个字符串.匹配字符串后将停止对后续的正则表达式进行匹配,如location ^~ /images/ , 在匹配了/images/这个字符串后就停止对后续的正则匹配 = 精 ...
- Jquery的toggle()与trigger()方法
我一直分不清楚toggle()与trigger()两个各自的作用,所以今天抽时间记录一些,以加深印象. 1.toggle() 定义和用法: toggle() 方法切换元素的可见状态.如果被选元素可见, ...
- left
left 语法: left: auto | <length> | <percentage> 默认值:auto 适用于:定位元素.即定义了 <' position '> ...