[深度学习] tf.keras入门2-分类
目录
主要介绍基于tf.keras的Fashion MNIST数据库分类,
官方文档地址为:https://tensorflow.google.cn/tutorials/keras/basic_classification
文本分类类似,官网文档地址为https://tensorflow.google.cn/tutorials/keras/basic_text_classification
首先是函数的调用,对于tensorflow只有在版本1.2以上的版本才有tf.keras库。另外推荐使用python3,而不是python2。
# TensorFlow and tf.keras
import tensorflow as tf
from tensorflow import keras
# 其他库
import numpy as np
import matplotlib.pyplot as plt
#查看版本
print(tf.__version__)
#1.9.0Fashion MNIST数据库
fashion mnist数据库是mnist数据库的一个拓展。目的是取代mnist数据库,类似MINST数据库,fashion mnist数据库为训练集60000张,测试集10000张的28X28大小的服装彩色图片。具体分类如下:
| 标注编号 | 描述 |
|---|---|
| 0 | T-shirt/top(T恤) |
| 1 | Trouser(裤子) |
| 2 | Pullover(套衫) |
| 3 | Dress(裙子) |
| 4 | Coat(外套) |
| 5 | Sandal(凉鞋) |
| 6 | Shirt(汗衫) |
| 7 | Sneaker(运动鞋) |
| 8 | Bag(包) |
| 9 | Ankle boot(踝靴) |
样本描述如下:
| 名称 | 描述 | 样本数量 | 文件大小 | 链接 |
|---|---|---|---|---|
train-images-idx3-ubyte.gz |
训练集的图像 | 60,000 | 26 MBytes | 下载 |
train-labels-idx1-ubyte.gz |
训练集的类别标签 | 60,000 | 29 KBytes | 下载 |
t10k-images-idx3-ubyte.gz |
测试集的图像 | 10,000 | 4.3 MBytes | 下载 |
t10k-labels-idx1-ubyte.gz |
测试集的类别标签 | 10,000 | 5.1 KBytes | 下载 |
单张图像展示代码:
#分类标签
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
#单张图像展示,推荐使用python3
plt.figure()
plt.imshow(train_images[0])
#添加颜色渐变条
plt.colorbar()
#不显示网格线
plt.gca().grid(False)效果图:
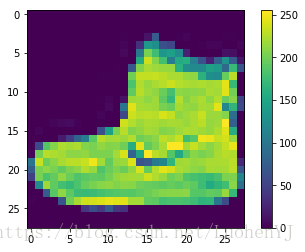
样本的展示代码:
#图像预处理
train_images = train_images / 255.0
test_images = test_images / 255.0
#样本展示
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid('off')
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])效果图:

分类模型的建立
检测模型输入数据为28X28,1个隐藏层节点数为128,输出类别10类,代码如下:
#检测模型
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation=tf.nn.relu),
keras.layers.Dense(10, activation=tf.nn.softmax)
]) 模型训练参数设置:
model.compile(optimizer=tf.train.AdamOptimizer(),
loss='sparse_categorical_crossentropy', #多分类的对数损失函数
metrics=['accuracy']) #准确度模型的训练:
model.fit(train_images, train_labels, epochs=5)模型预测
预测函数:
predictions = model.predict(test_images)分类器是softmax分类器,输出的结果一个predictions是一个长度为10的数组,数组中每一个数字的值表示其所对应分类的概率值。如下所示:
predictions[0]
array([2.1840347e-07, 1.9169457e-09, 4.5915922e-08, 5.3185740e-08,
6.6372898e-08, 2.6090498e-04, 6.5197796e-06, 4.7861701e-03,
2.9425648e-06, 9.9494308e-01], dtype=float32)对于predictions[0]其中第10个值最大,则该值对应的分类为class[9]ankle boot。
np.argmax(predictions[0]) #9
test_labels[0] #9
前25张图的分类效果展示:
#前25张图分类效果
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid('off')
plt.imshow(test_images[i], cmap=plt.cm.binary)
predicted_label = np.argmax(predictions[i])
true_label = test_labels[i]
if predicted_label == true_label:
color = 'green'
else:
color = 'red'
plt.xlabel("{} ({})".format(class_names[predicted_label],
class_names[true_label]),
color=color)效果图,绿色标签表示分类正确,红色标签表示分类错误:

对于单个图像的预测,需要将图像28X28的输入转换为1X28X28的输入,转换函数为np.expand_dims。函数使用如下:https://www.zhihu.com/question/265545749
#格式转换
img = (np.expand_dims(img,0))
print(img.shape) #1X28X28
predictions = model.predict(img)
prediction = predictions[0]
np.argmax(prediction) #9总体代码
# TensorFlow and tf.keras
import tensorflow as tf
from tensorflow import keras
# 其他库
import numpy as np
import matplotlib.pyplot as plt
#查看版本
print(tf.__version__)
#1.9.0
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
#分类标签
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
#单张图像展示,推荐使用python3
plt.figure()
plt.imshow(train_images[0])
#添加颜色渐变条
plt.colorbar()
#不显示网格线
plt.gca().grid(False)
#图像预处理
train_images = train_images / 255.0
test_images = test_images / 255.0
#样本展示
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid('off')
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
#检测模型
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation=tf.nn.relu),
keras.layers.Dense(10, activation=tf.nn.softmax)
])
model.compile(optimizer=tf.train.AdamOptimizer(),
loss='sparse_categorical_crossentropy', #多分类的对数损失函数
metrics=['accuracy']) #准确度
model.fit(train_images, train_labels, epochs=5)
predictions = model.predict(test_images)
#前25张图分类效果
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid('off')
plt.imshow(test_images[i], cmap=plt.cm.binary)
predicted_label = np.argmax(predictions[i])
true_label = test_labels[i]
if predicted_label == true_label:
color = 'green'
else:
color = 'red'
plt.xlabel("{} ({})".format(class_names[predicted_label],
class_names[true_label]),
color=color)
#单个图像检测
img = test_images[0]
print(img.shape) #28X28
#格式转换
img = (np.expand_dims(img,0))
print(img.shape) #1X28X28
predictions = model.predict(img)
prediction = predictions[0]
np.argmax(prediction) #9[深度学习] tf.keras入门2-分类的更多相关文章
- [深度学习] tf.keras入门1-基本函数介绍
目录 构建一个简单的模型 序贯(Sequential)模型 网络层的构造 模型训练和参数评价 模型训练 模型的训练 tf.data的数据集 模型评估和预测 基本模型的建立 网络层模型 模型子类函数构建 ...
- [深度学习] tf.keras入门4-过拟合和欠拟合
过拟合和欠拟合 简单来说过拟合就是模型训练集精度高,测试集训练精度低:欠拟合则是模型训练集和测试集训练精度都低. 官方文档地址为 https://tensorflow.google.cn/tutori ...
- [深度学习] tf.keras入门5-模型保存和载入
目录 设置 基于checkpoints的模型保存 通过ModelCheckpoint模块来自动保存数据 手动保存权重 整个模型保存 总体代码 模型可以在训练中或者训练完成后保存.具体文档参考:http ...
- [深度学习] tf.keras入门3-回归
目录 波士顿房价数据集 数据集 数据归一化 模型训练和预测 模型建立和训练 模型预测 总结 回归主要基于波士顿房价数据库进行建模,官方文档地址为:https://tensorflow.google.c ...
- 深度学习:Keras入门(一)之基础篇
1.关于Keras 1)简介 Keras是由纯python编写的基于theano/tensorflow的深度学习框架. Keras是一个高层神经网络API,支持快速实验,能够把你的idea迅速转换为结 ...
- 深度学习:Keras入门(一)之基础篇【转】
本文转载自:http://www.cnblogs.com/lc1217/p/7132364.html 1.关于Keras 1)简介 Keras是由纯python编写的基于theano/tensorfl ...
- 深度学习:Keras入门(一)之基础篇(转)
转自http://www.cnblogs.com/lc1217/p/7132364.html 1.关于Keras 1)简介 Keras是由纯python编写的基于theano/tensorflow的深 ...
- 深度学习:Keras入门(二)之卷积神经网络(CNN)
说明:这篇文章需要有一些相关的基础知识,否则看起来可能比较吃力. 1.卷积与神经元 1.1 什么是卷积? 简单来说,卷积(或内积)就是一种先把对应位置相乘然后再把结果相加的运算.(具体含义或者数学公式 ...
- 深度学习:Keras入门(二)之卷积神经网络(CNN)【转】
本文转载自:https://www.cnblogs.com/lc1217/p/7324935.html 说明:这篇文章需要有一些相关的基础知识,否则看起来可能比较吃力. 1.卷积与神经元 1.1 什么 ...
随机推荐
- .NET平台下一个你不知道的框架,我只想说两个字:“牛逼”
框架内容 零度框架是一套基于微服务和领域模型驱动设计的企业级快速开发框架,基于微软 .NET 6 + React 最新技术栈构建,容器化微服务最佳实践,零度框架的搭建以开发简单,多屏体验,前后端分离, ...
- AgileBoot - 手把手一步一步带你Run起全栈项目(SpringBoot+Vue3)
AgileBoot是笔者在业余时间基于ruoyi改造优化的前后端全栈项目. 关于AgileBoot的详细介绍:https://www.cnblogs.com/valarchie/p/16777336. ...
- String 定义一个字符串
String 定义一个字符串,要用双引号,多个字符串用+号连接 String S = "sjosajojoaf"; System.out.println(S);
- Hudi 数据湖的插入,更新,查询,分析操作示例
Hudi 数据湖的插入,更新,查询,分析操作示例 作者:Grey 原文地址: 博客园:Hudi 数据湖的插入,更新,查询,分析操作示例 CSDN:Hudi 数据湖的插入,更新,查询,分析操作示例 前置 ...
- `<jsp:getProperty>`动作和`<jsp:setProperty>`动作的使用在一个静态页面填写图书的基本信息,页面信息提交给其他页面,并且在其页面显示。要去将表单元素的值赋值给Java
<jsp:getProperty>动作和<jsp:setProperty>动作的使用 1.<jsp:getProperty>动作 语法格式: <jsp:get ...
- 27.-Django发送邮件
一.邮件相关协议-SMTP SMTP全称是Simple Mail Transfer Protocol,即简单邮件传输协议(25端口号) 它是由一组从源地址到目的地址传输邮件的规范,通过它来控制邮件的中 ...
- Java多线程-线程关键字(二)
Java中和线程相关的关键字就两:volatile和synchronized. volatile以前用得较少,以后会用得更少(后面解释).它是一种非常轻量级的同步机制,它的三大特性是: 1.保证可见性 ...
- packet Capture 手机抓包工具
packet Capture packet Capture 是一款免root的app, 运行在安卓平台上,用于捕获http/https网络流量嗅探的应用程序 特点: 捕获网络数据包,并记录太慢,使用中 ...
- Android 跨进程渲染
本项目用于验证 Android 是否能够跨进程渲染 View,最终实现了在子进程创建WebView,主进程显示的功能. 一.跨进程渲染的意义 有一些组件比如 WebView 如果在主进程初始化,会大大 ...
- sqlmap的安装及使用
前提:安装SQLMap前需安装Python环境!!!(此处不进行描述...) 一.安装 1.在官网(http://sqlmap.org/)进行SQLMap安装包下载: 2.在Python的安装目录下新 ...