JAVA中使用最广泛的本地缓存?Ehcache的自信从何而来3 —— 本地缓存变身分布式集群缓存,打破本地缓存天花板

大家好,又见面了。
本文是笔者作为掘金技术社区签约作者的身份输出的缓存专栏系列内容,将会通过系列专题,讲清楚缓存的方方面面。如果感兴趣,欢迎关注以获取后续更新。
上一篇文章中,我们知晓了如何在项目中通过不同的方式来集成Ehcache并在业务逻辑中进行使用。作为JAVA本地缓存框架综合实力天花板级别的Ehcache,除了在本地缓存方面具有强悍的实力外,还具有一个其它对手所不具备的特色功能,即Ehcache提供了对于集群能力的支持,这也使得Ehcache不仅仅是个本地单机缓存,更是一个分布式缓存。
分布式缓存的意义是什么?集群方案又可以解决哪些问题?它与单机缓存有啥区别?与Redis等集中式缓存有啥不同?如何去选择、又该如何使用?带着这一连串的疑问,让我们一起探讨下Ehcache的各种不同集群方案,找出上述问题的答案。

本地缓存或者集中缓存的问题
在正式开始阐述Ehcache的集群解决方案前,先来做个铺垫,了解下单机缓存与集中式缓存各自存在的问题。
单机缓存不可言说的痛
对于单机缓存而言,缓存数据维护在进程中,应用系统部署完成之后,各个节点进程就会自己维护自己内存中的数据。在集群化部署的业务场景中,各个进程独自维护自己内存中的数据,而经由负载均衡器分发到各个节点进行处理的请求各不相同,这就导致了进程内缓存数据不一致,进而出现各种问题 —— 比较典型的就是缓存漂移问题。
缓存漂移,是单机缓存在分布式系统下无法忽视的一个问题。在这种情况下,大部分的项目使用中会选择避其锋芒、或者自行实现同步策略进行应对。常见的策略有:
本地缓存中仅存储一些固定不变、或者不常变化的数据。
通过过期重新加载、定时refresh等策略定时更新本地的缓存,忍受数据有一定时间内的不一致。
对于少量更新的场景,借助MQ构建更新机制,有变更就发到MQ中然后所有节点消费变更事件然后更新自身数据。
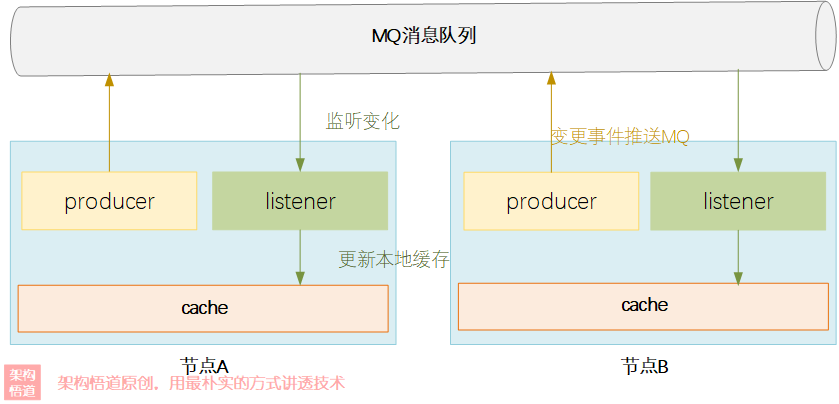
集中式缓存也并非万能银弹
在集群部署的场景下,为了简化缓存数据一致性方面的处理逻辑,大部分的场景会直接选择使用Redis等集中式缓存。集中式缓存的确是为分布式集群场景而生的,通过将缓存数据集中存放,使得每个业务节点读取与操作的都是同一份缓存记录。这样只需要由缓存服务保证并发原子性即可。
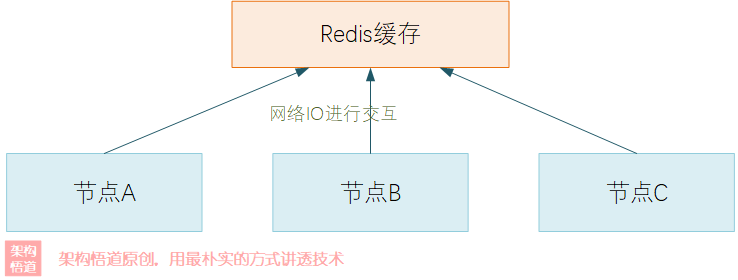
但集中式缓存也并非是分布式场景下缓存方案的万能银弹。
项目中使用缓存的目的,主要是为了提升整体的运算处理效率,降低对外的IO请求等等。而集中式缓存是独立于进程之外部署的远端服务,需要基于网络IO交互的方式来获取,如果一个业务逻辑中涉及到非常频繁的缓存操作,势必会导致引入大量的网络IO交互,进而导致非常严重的性能损耗。
为了解决这个问题,很多时候还是需要本地缓存结合集中式缓存的方式,构建多级缓存的方式来解决。
Ehcache分布式集群方案
相比纯粹的本地缓存,Ehcache自带集群解决方案,通过相应的配置可以让本地缓存变身集群版本,以此来应付分布式场景下各个节点缓存数据不一致的问题,并且由于数据都缓存在进程内部,所以也可以避免集中是缓存频繁在业务流程中频繁网络交互的弊端。
Ehcache官方提供了多种集群方案供选择,下面一起看下。
RMI组播
RMI是一种点对点(P2P)的通信交互机制,Ehcache利用RMI来实现多个节点之间数据的互通有无,相互知会彼此更新数据。对于集群场景下,这就要求集群内所有节点之间要两两互通,组成一张网状结构。
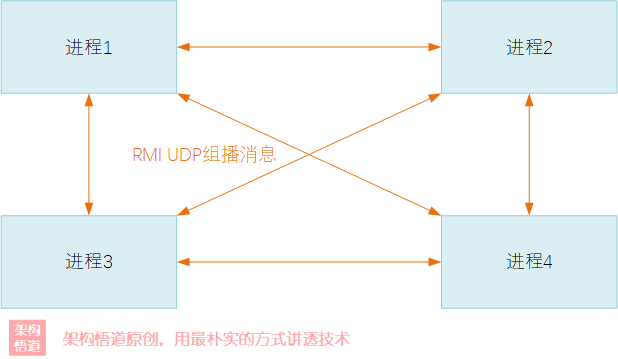
在集群方式下进行数据通信交互,要求被传输的数据一定是要可序列化与反序列化的,对于JAVA而言,直白的说,就是对象一定是要实现了Serializable接口。
基于RMI组播的方式,Ehcache会向对应地址发送RMI UDP组播包,由于Ehcache对于组播的实现较为简单,所以在一些网络情况较为复杂的场景的支持度不是很完善,方案选择的时候需注意。此外,由于是即时消息模式,如果中途某个进程由于某些原因不可达,也可能会导致同步消息的丢失。所以对于可靠性以及数据一致性要求较高的场景需要慎选。
JMS消息
JMS消息方案是一种很常用的Ehcache集群方案。JMS是一套JAVA中两个进程之间的异步通信API,定义了消息通讯所必须的一组通用能力接口,比如消息的创建、发送、接收读取等。
JMS也支持构建基于事件触发模型的消息交互机制,也即生产者消费者模式(又称发布订阅模式),其核心就是一个消息队列,集群内各个业务节点都订阅对应的消息队列topic主题,如果有数据变更事件,也发送到消息队列的对应的topic主题下供其它节点消费。
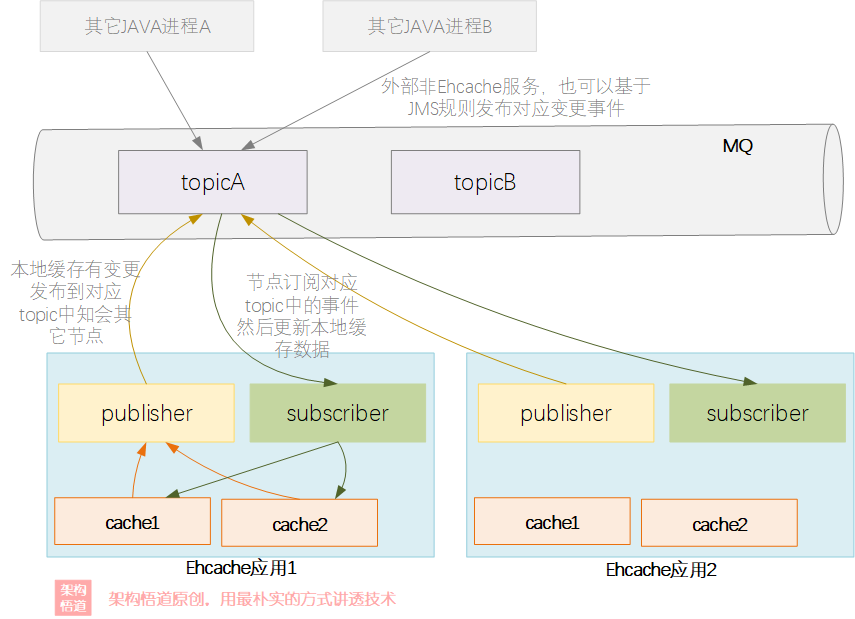
相比于RMI组播方式,JMS消息方式有个很大的优势在于不需要保证所有节点都全部同时在线,因为是基于发布订阅模式,所以即使有节点中途某些原因宕机又重启了,重启之后仍然可以接收其他节点已发布的变更,然后保证自己的缓存数据与其它节点一致。
Ehcache支持对接多种不同的MQ来实现基于JMS消息的集群组网方案,默认使用ActiveMQ,也可以切换为Kafka或者RabbitMQ等消息队列组件。
Cache Server模式
Ehcache的Cache Server是一种比较特殊的存在形式,它通常是一个独立的进程进行部署,然后多个独立的进程之间组成一个分布式集群。Cache Server是一个纯粹的缓存集群,对外提供restful接口或者soap接口,各个业务可以通过接口来获取缓存 —— 这个其实已经不是本地进程内缓存的概念了,其实就是一个独立的集中式缓存,类似Redis般的感觉。
看一下一个典型的高可用水平扩容模式的Cache Server组网与业务调用的场景示意图:
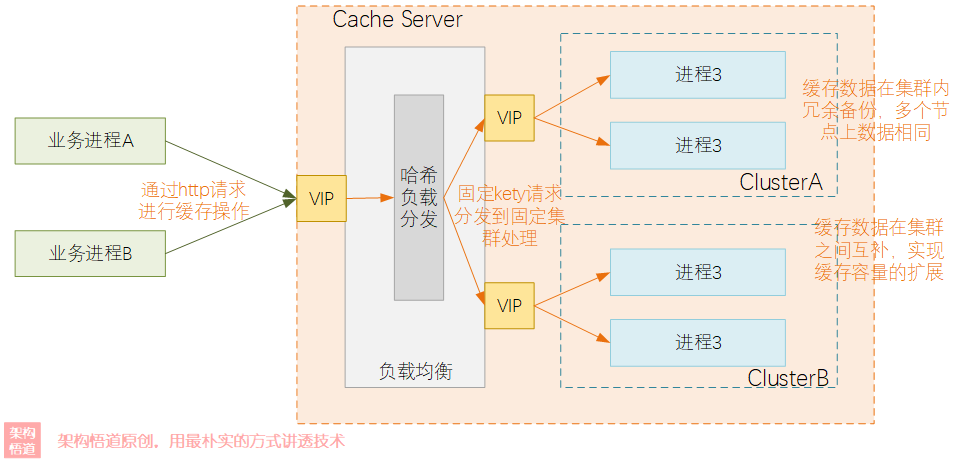
可以看到不管业务模块是用的什么编码语言,或者是什么形态的,都可以通过http接口去访问缓存数据,而Cache Server就是一个集中式缓存。在Cache Server中,集群内部可以有一个或者多个节点,这些节点具有完全相同的数据内容,做到了数据的冗余备份,而集群之间数据可以不同,实现了数据容量的水平扩展。
值得注意的一点是,如果你访问Ehcache的官网,会发现其官方提供的3.x版本的说明文档中不再有Cache Server的身影,而在2.x版本中都会作为一个单独的章节进行介绍。为什么在3.x版本中不再提供Cache Server模式呢?我在官方文档中没找到相关的说明,个人猜测主要有下面几个原因:
定位过于尴尬,如果说要作为集中式缓存来使用,完全可以直接使用redis,没有必要费事劳神的去搭建Cache Server
Terracotta方式相比而言功能上更加的完备,兼具水平扩展与本地缓存的双重优势,完全可以取代Cache Server
JGroups方式
JGroups的方式其实和RMI有点类似。JGroups是一个开源的群组通讯工具,可以用来创建一个组,这个组中的成员可以给其他成员发送消息。其工作模式基于IP组播(IP multicast),但可以在可靠性和群组成员管理上进行扩展,而且JGroups的架构上设计非常灵活,提供可以兼容多种协议的协议栈。
JGroups的可靠性体现在下面几个方面:
- 对所有接收者的消息的无丢失传输(通过丢失消息的重发)
- 大消息的分割传输和重组
- 消息的顺序发送和接收
- 保证原子性,消息要么被所有接收者接收,要么所有接收者都收不到
也正是由于JGroups具备的上述诸多优秀特性,它常常被选择作为集群内各个节点之间数据同步的解决方案。而Ehcache也一样,支持基于JGroups实现的集群方案,通过IP组播消息,保证集群内各个节点之间数据的同步。
Terracotta方式
Terracotta是什么?看下来自百度百科的介绍:
Terracotta是一款由美国Terracotta公司开发的著名开源Java集群平台。它在JVM与Java应用之间实现了一个专门处理集群功能的抽象层,以其特有的增量检测、智能定向传送、分布式协作、服务器镜像、分片等技术,允许用户在不改变现有系统代码的情况下实现单机Java应用向集群化应用的无缝迁移。使得用户可以专注于商业逻辑的开发,由Terracotta负责实现高性能、高可用性、高稳定性的企业级Java集群。
所以说,Terracotta是一个JVM层专门负责做分布式节点间协同处理的平台框架。那么当优秀的JVM级缓存框架Ehcache与同样优秀的JVM间多节点协同框架Terracotta组合到一起,势必会有不俗的表现。
看下来自Ehcache官网的对于其Terracotta集群模式的图片说明:
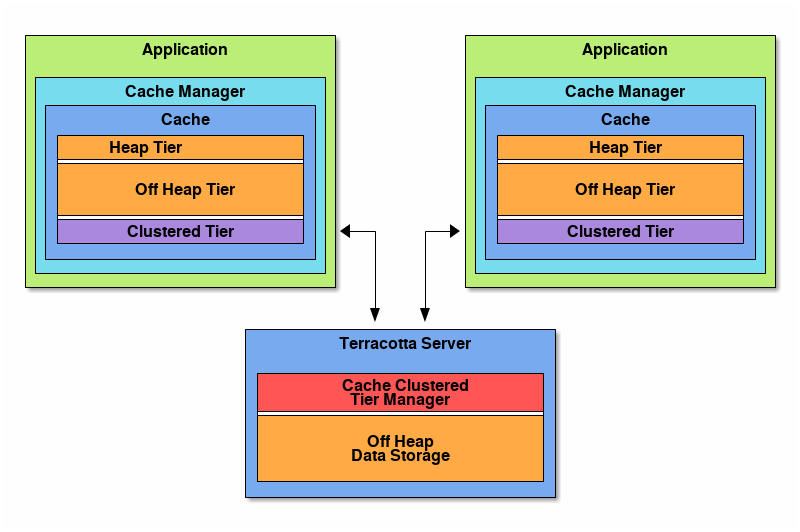
基于Terracotta方式,Ehcache可以支持:
热点数据存储在进程本地,然后根据热度进行优化存储,热度高的会优先存储在更快的位置(比如heap中)。
存储在其中一台应用节点上的缓存数据,可以被集群中其它节点访问到。
缓存数据在集群层面是完整的,也支持按照HA模式设定高可用备份。
可以说这种模式下,既保留了Ehcache本地缓存的超高处理性能,又享受到了分布式缓存带来的集群优势,不失为一种比较亮眼的组合。
引申思考 —— 本地缓存的设计边界与定位
如上所言,纵使Ehcache提供了多种集群化策略,但略显尴尬的是实际中各个公司项目并没有大面积的使用。其实分析下来也很好理解:
如果真的需要很明确的诉求去解决分布式场景下的缓存一致性问题,直接选择redis、memcache等主流的集中式缓存组件即可
所以Ehcache的整体综合功能虽然是最强大的,整体定位偏向于大而全,但也导致在各个细分场景下表现不够极致:
相比
Caffeine:略显臃肿, 因为提供了很多额外的功能,比如使用磁盘缓存、比如支持多节点间集群组网等;相比
Redis: 先天不足,毕竟是个本地缓存,纵使支持了多种组网模式,依旧无法媲美集中式缓存在分布式场景下的体验。
但在一些相对简单的集群数据同步场景下,或者对可靠性要求不高的集群缓存数据同步场景下,Ehcache还是很有优势的、尤其是Terracotta集群模式,也不啻为一个很好的选择。
小结回顾
好啦,关于Ehcache的集群相关能力,就介绍到这里咯,而关于文章开头的几个问题,我们也在文章内容中做了解答与探讨。至此呢,我们关于Ehcache的相关介绍就全部结束了。那么你对Ehcache是否还有什么自己的观点呢?欢迎评论区一起交流下,期待和各位小伙伴们一起切磋、共同成长。
随着本篇Ehcache介绍文章的结束,我们缓存专栏关于主流本地缓存框架的介绍就告一段落了。下一篇文章开始,我们将开始将目光聚焦到集中式缓存的身上,比如大家耳熟能详的Redis,以及经常在面试中会拿来与Redis做比较的Memcache等等。如有兴趣,欢迎关注。
补充说明1 :
本文属于《深入理解缓存原理与实战设计》系列专栏的内容之一。该专栏围绕缓存这个宏大命题进行展开阐述,全方位、系统性地深度剖析各种缓存实现策略与原理、以及缓存的各种用法、各种问题应对策略,并一起探讨下缓存设计的哲学。
如果有兴趣,也欢迎关注此专栏。
补充说明2 :
- 关于本文中涉及的演示代码的完整示例,我已经整理并提交到github中,如果您有需要,可以自取:https://github.com/veezean/JavaBasicSkills
我是悟道,聊技术、又不仅仅聊技术~
如果觉得有用,请点赞 + 关注让我感受到您的支持。也可以关注下我的公众号【架构悟道】,获取更及时的更新。
期待与你一起探讨,一起成长为更好的自己。

JAVA中使用最广泛的本地缓存?Ehcache的自信从何而来3 —— 本地缓存变身分布式集群缓存,打破本地缓存天花板的更多相关文章
- 使用Docker在本地搭建Hadoop分布式集群
学习Hadoop集群环境搭建是Hadoop入门必经之路.搭建分布式集群通常有两个办法: 要么找多台机器来部署(常常找不到机器) 或者在本地开多个虚拟机(开销很大,对宿主机器性能要求高,光是安装多个虚拟 ...
- Twemproxy 分布式集群缓存代理服务器
Twemproxy 分布式集群缓存代理服务器 是一个使用C语言编写.以代理的方式实现的.轻量级的Redis代理服务器, 它通过引入一个代理层,将应用程序后端的多台Redis实例进行统一管理, 使 应用 ...
- 030 分布式集群中,设定时间同步服务器,以及ntpd与ntpdate的区别
什么时候配置时间同步? 当分布式集群配置好了以后,马上配置的是SSH无密钥配置,然后就是配置时间同步. 时间同步在集群中特别重要. 一:时间同步 1.时间同步 集群中必须有一个统一的时间 如果是内网, ...
- java高级精讲之高并发抢红包~揭开Redis分布式集群与Lua神秘面纱
java高级精讲之高并发抢红包~揭开Redis分布式集群与Lua神秘面纱 redis数据库 Redis企业集群高级应用精品教程[图灵学院] Redis权威指南 利用redis + lua解决抢红包高并 ...
- Hadoop学习之路(十二)分布式集群中HDFS系统的各种角色
NameNode 学习目标 理解 namenode 的工作机制尤其是元数据管理机制,以增强对 HDFS 工作原理的 理解,及培养 hadoop 集群运营中“性能调优”.“namenode”故障问题的分 ...
- CentOS中搭建Redis伪分布式集群【转】
解压redis 先到官网https://redis.io/下载redis安装包,然后在CentOS操作系统中解压该安装包: tar -zxvf redis-3.2.9.tar.gz 编译redis c ...
- Hadoop(五)分布式集群中HDFS系统的各种角色
NameNode 学习目标 理解 namenode 的工作机制尤其是元数据管理机制,以增强对 HDFS 工作原理的 理解,及培养 hadoop 集群运营中“性能调优”.“namenode”故障问题的分 ...
- Hadoop学习笔记—13.分布式集群中节点的动态添加与下架
开篇:在本笔记系列的第一篇中,我们介绍了如何搭建伪分布与分布模式的Hadoop集群.现在,我们来了解一下在一个Hadoop分布式集群中,如何动态(不关机且正在运行的情况下)地添加一个Hadoop节点与 ...
- 分布式集群中,设定时间同步服务器,以及ntpd与ntpdate的区别
什么时候配置时间同步? 当分布式集群配置好了以后,马上配置的是SSH无密钥配置,然后就是配置时间同步. 时间同步在集群中特别重要. 一:时间同步 1.时间同步 集群中必须有一个统一的时间 如果是内网, ...
- 5 weekend01、02、03、04、05、06、07的分布式集群的HA测试 + hdfs--动态增加节点和副本数量管理 + HA的java api访问要点
weekend01.02.03.04.05.06.07的分布式集群的HA测试 1) weekend01.02的hdfs的HA测试 2) weekend03.04的yarn的HA测试 1) wee ...
随机推荐
- 虚拟化_Xen——敬请期待!
更改Workstation兼容性为12.x,选择系统版本为RHEL6-64位,安装XenServer7.6成功!
- 齐博x1APP要实现直播的关键两步
大家务必要注意,缺少这两步,你的APP将不能实现直播, 也即点击直播按钮无法启动直播推流 https://www.maxdo.tech/
- OpenStack云计算平台框架
概: OpenStack是包含很多独立组件的一个云计算平台框架.在安装组件前,需要先将框架搭建出来,才能向其中放置组件. 搭建open stack云计算平台框架 一.安装open stack云计算平 ...
- day02-HTML02
4.HTML 4.3HTML基本标签 4.3.9表格(table)标签 基本语法: <table border="边框宽度" cellspacing="空隙大小&q ...
- node.js:《接口实现文件的上传和下载》
使用node.js写上传文件和下载文件的接口 上传接口: 开始写接口前,我们先安装一个上传文件的插件:npm install multer 安装成功在package.json或package-lock ...
- 各种优化器对比--BGD/SGD/MBGD/MSGD/NAG/Adagrad/Adam
指数加权平均 (exponentially weighted averges) 先说一下指数加权平均, 公式如下: \[v_{t}=\beta v_{t-1}+(1-\beta) \theta_{t} ...
- FHQ Treap 详解
鲜花 一些鲜花放在前面,平衡树学了很久,但是每学一遍都忘,原因就在于我只能 70% 理解 + 30% 背板子,所以每次都忘.这次我采取了截然不同的策略,自己按照自己的理解打一遍,大获成功(?),大概打 ...
- Java集合精选常见面试题
前言 博主只是这篇文章的搬运工,为了加强记忆自己梳理了一遍并扩展了部分内容. 集合拓展链接:集合概述&集合之Collection接口 - 至安 - 博客园 (cnblogs.com) Java ...
- Xmake v2.7.3 发布,包组件和 C++ 模块增量构建支持
Xmake 是一个基于 Lua 的轻量级跨平台构建工具. 它非常的轻量,没有任何依赖,因为它内置了 Lua 运行时. 它使用 xmake.lua 维护项目构建,相比 makefile/CMakeLis ...
- vue 项目中,后端返回文件流,导出excel
之前写过文件流导出excel,这次直接把上次的代码拿过来复制粘贴,但是导出的表格里面没有数据,只显示undefined. 这是之前的代码 // api接口页面 // excel导出接口 export ...