CosineWarmup理论与代码实战
摘要:CosineWarmup是一种非常实用的训练策略,本次教程将带领大家实现该训练策略。教程将从理论和代码实战两个方面进行。
本文分享自华为云社区《CosineWarmup理论介绍与代码实战》,作者: 李长安。
CosineWarmup是一种非常实用的训练策略,本次教程将带领大家实现该训练策略。教程将从理论和代码实战两个方面进行。
在代码实战部分,模型采用LeNet-5模型进行测试,数据采用Cifar10数据集作为基准数据,
Warmup最早出现于这篇文章中:Accurate, Large Minibatch SGD:Training ImageNet in 1 Hour,warmup类似于跑步中的热身,在刚刚开始训练的时候进行热身,使得网络逐渐熟悉数据的分布,随着训练的进行学习率慢慢变大,到了指定的轮数,再使用初始学习率进行训练。
consine learning rate则来自于这篇文章Bag of Tricks for Image Classification with Convolutional Neural Networks,通过余弦函数对学习率进行调整
一般情况下,只在前五个Epoch中使用Warmup,并且通常情况下,把warm up和consine learning rate一起使用会达到更好的效果。
- Warmup
Warmup是在ResNet论文中提到的一种学习率预热的方法,它在训练开始的时候先选择使用一个较小的学习率,训练了一些epoches或者steps(比如4个epoches,10000steps),再修改为预先设置的学习来进行训练。由于刚开始训练时,模型的权重(weights)是随机初始化的,此时若选择一个较大的学习率,可能带来模型的不稳定(振荡),选择Warmup预热学习率的方式,可以使得开始训练的几个epoches或者一些steps内学习率较小,在预热的小学习率下,模型可以慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练,使得模型收敛速度变得更快,模型效果更佳。
- 余弦退火策略
当我们使用梯度下降算法来优化目标函数的时候,当越来越接近Loss值的全局最小值时,学习率应该变得更小来使得模型尽可能接近这一点,而余弦退火(Cosine annealing)可以通过余弦函数来降低学习率。余弦函数中随着x的增加余弦值首先缓慢下降,然后加速下降,再次缓慢下降。这种下降模式能和学习率配合,以一种十分有效的计算方式来产生很好的效果。
- 带Warmup的余弦退火策略
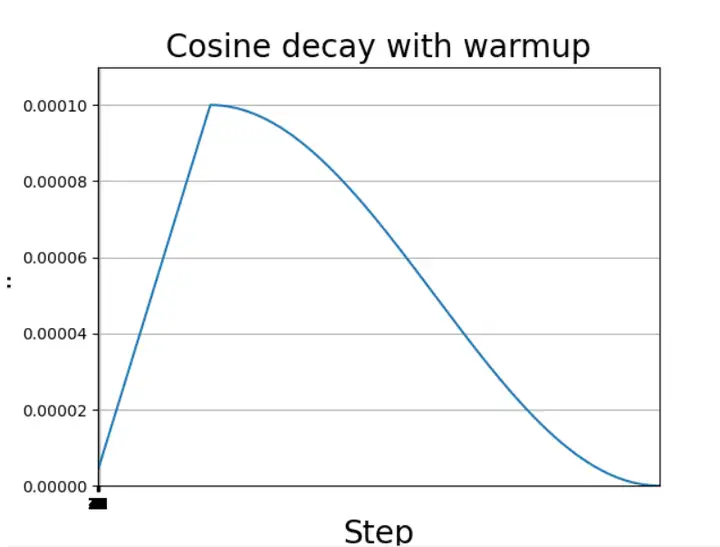
- 单个周期余弦退火衰减图形
以单个周期余弦退火衰减为例,介绍带Warmup的余弦退火策略,如下图所示,学习率首先缓慢升高,达到设定的最高值之后,通过余弦函数进行衰减调整。但是通常面对大数据集的时候,学习率可能会多次重复上述调整策略。
代码实现
from paddle.optimizer.lr import LinearWarmup
from paddle.optimizer.lr import CosineAnnealingDecay
class Cosine(CosineAnnealingDecay):
"""
Cosine learning rate decay
lr = 0.05 * (math.cos(epoch * (math.pi / epochs)) + 1)
Args:
lr(float): initial learning rate
step_each_epoch(int): steps each epoch
epochs(int): total training epochs
"""
def __init__(self, lr, step_each_epoch, epochs, **kwargs):
super(Cosine, self).__init__(
learning_rate=lr,
T_max=step_each_epoch * epochs, )
self.update_specified = False
class CosineWarmup(LinearWarmup):
"""
Cosine learning rate decay with warmup
[0, warmup_epoch): linear warmup
[warmup_epoch, epochs): cosine decay
Args:
lr(float): initial learning rate
step_each_epoch(int): steps each epoch
epochs(int): total training epochs
warmup_epoch(int): epoch num of warmup
"""
def __init__(self, lr, step_each_epoch, epochs, warmup_epoch=5, **kwargs):
assert epochs > warmup_epoch, "total epoch({}) should be larger than warmup_epoch({}) in CosineWarmup.".format(
epochs, warmup_epoch)
warmup_step = warmup_epoch * step_each_epoch
start_lr = 0.0
end_lr = lr
lr_sch = Cosine(lr, step_each_epoch, epochs - warmup_epoch)
super(CosineWarmup, self).__init__(
learning_rate=lr_sch,
warmup_steps=warmup_step,
start_lr=start_lr,
end_lr=end_lr)
self.update_specified = False
实战
import paddle
import paddle.nn.functional as F
from paddle.vision.transforms import ToTensor
from paddle import fluid
import paddle.nn as nn
print(paddle.__version__)
2.0.2
transform = ToTensor()
cifar10_train = paddle.vision.datasets.Cifar10(mode='train',
transform=transform)
cifar10_test = paddle.vision.datasets.Cifar10(mode='test',
transform=transform)
# 构建训练集数据加载器
train_loader = paddle.io.DataLoader(cifar10_train, batch_size=64, shuffle=True)
# 构建测试集数据加载器
test_loader = paddle.io.DataLoader(cifar10_test, batch_size=64, shuffle=True)
Cache file /home/aistudio/.cache/paddle/dataset/cifar/cifar-10-python.tar.gz not found, downloading https://dataset.bj.bcebos.com/cifar/cifar-10-python.tar.gz
Begin to download
Download finished
class MyNet(paddle.nn.Layer):
def __init__(self, num_classes=10):
super(MyNet, self).__init__()
self.conv1 = paddle.nn.Conv2D(in_channels=3, out_channels=32, kernel_size=(3, 3), stride=1, padding = 1)
# self.pool1 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.conv2 = paddle.nn.Conv2D(in_channels=32, out_channels=64, kernel_size=(3,3), stride=2, padding = 0)
# self.pool2 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.conv3 = paddle.nn.Conv2D(in_channels=64, out_channels=64, kernel_size=(3,3), stride=2, padding = 0)
# self.DropBlock = DropBlock(block_size=5, keep_prob=0.9, name='le')
self.conv4 = paddle.nn.Conv2D(in_channels=64, out_channels=64, kernel_size=(3,3), stride=2, padding = 1)
self.flatten = paddle.nn.Flatten()
self.linear1 = paddle.nn.Linear(in_features=1024, out_features=64)
self.linear2 = paddle.nn.Linear(in_features=64, out_features=num_classes)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
# x = self.pool1(x)
# print(x.shape)
x = self.conv2(x)
x = F.relu(x)
# x = self.pool2(x)
# print(x.shape)
x = self.conv3(x)
x = F.relu(x)
# print(x.shape)
# x = self.DropBlock(x)
x = self.conv4(x)
x = F.relu(x)
# print(x.shape)
x = self.flatten(x)
x = self.linear1(x)
x = F.relu(x)
x = self.linear2(x)
return x
# 可视化模型
cnn2 = MyNet()
model2 = paddle.Model(cnn2)
model2.summary((64, 3, 32, 32))
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv2D-1 [[64, 3, 32, 32]] [64, 32, 32, 32] 896
Conv2D-2 [[64, 32, 32, 32]] [64, 64, 15, 15] 18,496
Conv2D-3 [[64, 64, 15, 15]] [64, 64, 7, 7] 36,928
Conv2D-4 [[64, 64, 7, 7]] [64, 64, 4, 4] 36,928
Flatten-1 [[64, 64, 4, 4]] [64, 1024] 0
Linear-1 [[64, 1024]] [64, 64] 65,600
Linear-2 [[64, 64]] [64, 10] 650
===========================================================================
Total params: 159,498
Trainable params: 159,498
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 0.75
Forward/backward pass size (MB): 25.60
Params size (MB): 0.61
Estimated Total Size (MB): 26.96
---------------------------------------------------------------------------
{'total_params': 159498, 'trainable_params': 159498}
# 配置模型
from paddle.metric import Accuracy
scheduler = CosineWarmup(
lr=0.5, step_each_epoch=100, epochs=8, warmup_steps=20, start_lr=0, end_lr=0.5, verbose=True)
optim = paddle.optimizer.SGD(learning_rate=scheduler, parameters=model2.parameters())
model2.prepare(
optim,
paddle.nn.CrossEntropyLoss(),
Accuracy()
)
# 模型训练与评估
model2.fit(train_loader,
test_loader,
epochs=10,
verbose=1,
)
The loss value printed in the log is the current step, and the metric is the average value of previous step.
Epoch 1/3
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:77: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
return (isinstance(seq, collections.Sequence) and
step 782/782 [==============================] - loss: 1.9828 - acc: 0.2280 - 106ms/step
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 157/157 [==============================] - loss: 1.5398 - acc: 0.3646 - 35ms/step
Eval samples: 10000
Epoch 2/3
step 782/782 [==============================] - loss: 1.7682 - acc: 0.3633 - 106ms/step
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 157/157 [==============================] - loss: 1.7934 - acc: 0.3867 - 34ms/step
Eval samples: 10000
Epoch 3/3
step 782/782 [==============================] - loss: 1.3394 - acc: 0.4226 - 105ms/step
Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 157/157 [==============================] - loss: 1.4539 - acc: 0.3438 - 35ms/step
Eval samples: 10000
总结
之前一直提到这个CosineWarmup,但是一直没有实现过,这次也算是填了一个很早之前就挖的坑。同样,这里也不再设置对比实验,因为这个东西确实很管用。小模型和小数据集可能不太能够体现该训练策略的有效性。大家如果有兴趣可以使用更大的模型、更大的数据集测试一下。
CosineWarmup理论与代码实战的更多相关文章
- Scala 深入浅出实战经典 第64讲:Scala中隐式对象代码实战详解
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-87讲)完整视频.PPT.代码下载:百度云盘:http://pan.baidu.com/s/1c0noOt6 ...
- Scala 深入浅出实战经典 第63讲:Scala中隐式类代码实战详解
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-87讲)完整视频.PPT.代码下载:百度云盘:http://pan.baidu.com/s/1c0noOt6 ...
- Scala 深入浅出实战经典 第52讲:Scala中路径依赖代码实战详解
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-64讲)完整视频.PPT.代码下载:百度云盘:http://pan.baidu.com/s/1c0noOt6 ...
- Scala 深入浅出实战经典 第51讲:Scala中链式调用风格的实现代码实战及其在Spark中应用
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-64讲)完整视频.PPT.代码下载:百度云盘:http://pan.baidu.com/s/1c0noOt6 ...
- Scala 深入浅出实战经典 第49课 Scala中Variance代码实战(协变)
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-64讲)完整视频.PPT.代码下载:百度云盘:http://pan.baidu.com/s/1c0noOt6 ...
- Scala 深入浅出实战经典 第48讲:Scala类型约束代码实战及其在Spark中的应用源码解析
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-64讲)完整视频.PPT.代码下载:百度云盘:http://pan.baidu.com/s/1c0noOt6 ...
- Scala 深入浅出实战经典 第47讲:Scala多重界定代码实战及其在Spark中的应用
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-64讲)完整视频.PPT.代码下载:百度云盘:http://pan.baidu.com/s/1c0noOt6 ...
- Scala 深入浅出实战经典 第40讲:Set、Map、TreeSet、TreeMap操作代码实战
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-64讲)完整视频.PPT.代码下载:百度云盘:http://pan.baidu.com/s/1c0noOt6 ...
- Scala 深入浅出实战经典 第39讲:ListBuffer、ArrayBuffer、Queue、Stack操作代码实战
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-64讲)完整视频.PPT.代码下载:百度云盘:http://pan.baidu.com/s/1c0noOt6 ...
- Scala深入浅出实战经典之 List的foldLeft、foldRight、sort操作代码实战
Scala 深入浅出实战经典(1-64讲)完整视频.PPT.代码下载:百度云盘:http://pan.baidu.com/s/1c0noOt6 腾讯微云:http://url.cn/TnGbdC 3 ...
随机推荐
- 如何在超星下载非资料页面的ppt
首先打开迅雷(没有就复制到网页下载) 点击f12 点击网络,筛查出输入flag,在响应模块中找到ppt,复制网址并下载
- Python基础数据类型-list(列表)
a = [1, 2, 3] a.append([1, 4]) a.append(8) a.append([8, 9, '10']) # 添加的是整体,即:将输入对象添加到列表末尾 print(a) # ...
- Notepad++中文设置
找到问题所在了,作者改了个小代码,在安装目录下打开localization找到chineseSimplified,打开后,在852行那里找到下面这段代码 <MarginsBorderEdge t ...
- 4、Redis底层原理(持久化+分布式锁)
Redis底层原理 持久化 Redis虽然是个内存数据库,但是Redis支持RDB和AOF两种持久化机制,将数据写往磁盘,可以有效地避免因进程退出造成的数据丢失问题,当下次重启时利用之前持久化的文件即 ...
- C语言——数组
一.一维数组 声明形式: type arrayName [ arraySize ]; 实例: 1 #include <stdio.h> 2 int main() 3 { 4 int Arr ...
- Codeforces Round #843 (Div. 2) Problem C
C. Interesting Sequence time limit per test 1 second memory limit per test 256 megabytes input stand ...
- uniapp中使用AntV F6 + table表格插件使用
首先看页面效果: AntV官网下载F6文件到项目中与uViewUI插件 <template> <view class="page"> <!-- 导航栏 ...
- Vue 加载显示源代码 , Vue 屏幕闪动
1.当网络较慢,网页还在加载 Vue.js ,而导致 Vue 来不及渲染,这时页面就会显示出 Vue 源代码.我们可以使用 v-cloak 指令来解决这一问题. <style> [v-cl ...
- FCC 高级算法题 验证电话号码
Validate US Telephone Numbers 如果传入字符串是一个有效的美国电话号码,则返回 true. 用户可以在表单中填入一个任意有效美国电话号码. 下面是一些有效号码的例子(还有下 ...
- 01.数据库基础、JDBC
一.数据库 数据库:用于存储和管理数据的仓库. 数据库的特点 持久化储存数据,数据库就是一个文件系统. 方便储存和管理数据. 使用了统一的方式操作数据库--SQL. 配置 Mysql 服务启动 手动 ...