为什么样本方差的分母是n-1?为什么它又叫做无偏估计?

为什么样本方差的分母是n-1?最简单的原因,是因为因为均值已经用了n个数的平均来做估计在求方差时,只有(n-1)个数和均值信息是不相关的。而你的第n个数已经可以由前(n-1)个数和均值 来唯一确定,实际上没有信息量。所以在计算方差时,只除以(n-1)。
那么更严格的证明呢?请耐心的看下去。
样本方差计算公式里分母为 的目的是为了让方差的估计是无偏的。
的目的是为了让方差的估计是无偏的。
无偏的估计(unbiased estimator)比有偏估计(biased estimator)更好是符合直觉的,尽管有的统计学家认为让mean square error即MSE最小才更有意义,这个问题我们不在这里探讨;不符合直觉的是,为什么分母必须得是 而不是才能使得该估计无偏。
而不是才能使得该估计无偏。
首先,我们假定随机变量的数学期望是已知的,然而方差未知。在这个条件下,根据方差的定义我们有
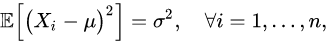
由此可得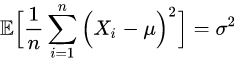
因此

是方差的一个无偏估计,注意式中的分母不偏不倚正好是!这个结果符合直觉,并且在数学上也是显而易见的。
现在,我们考虑随机变量 的数学期望是未知
的数学期望是未知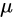 的情形。这时,我们会倾向于无脑直接用样本均值
的情形。这时,我们会倾向于无脑直接用样本均值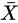 替换掉上面式子中的
替换掉上面式子中的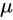 。这样做有什么后果呢?后果就是,如果直接使用
。这样做有什么后果呢?后果就是,如果直接使用
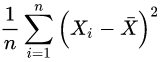
作为估计,那么你会倾向于低估方差!这是因为:
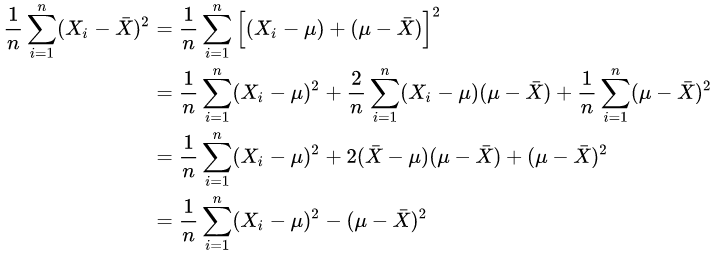
换言之,除非正好,否则我们一定有
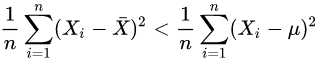
而不等式右边的那位才是的对方差的“正确”估计!这个不等式说明了,为什么直接使用
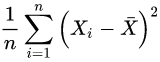
会导致对方差的低估。
那么,在不知道随机变量真实数学期望的前提下,如何“正确”的估计方差呢?答案是把上式中的分母n换成n-1,通过这种方法把原来的偏小的估计“放大”一点点,我们就能获得对方差的正确估计了:
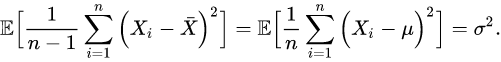
至于为什么分母是n-1而不是n-2或者别的什么数,最好还是去看真正的数学证明,因为数学证明的根本目的就是告诉人们“为什么”;暂时我没有办法给出更“初等”的解释了。
更多机器学习、编程、AI相关知识,也欢迎关注我的公众号“图灵的猫”。关注公众号,点击“学习资料”菜单,即可获得海量机器学习、深度学习书籍等免费PDF资源~

为什么样本方差的分母是n-1?为什么它又叫做无偏估计?的更多相关文章
- 为什么样本方差自由度(分母)为n-1
一.概念.条件及目的 1.概念 要理解样本方差的自由度为什么是n-1,得先理解自由度的概念: 自由度,是指附加给独立的观测值的约束或限制的个数,即一组数据中可以自由取值的个数. 2.成立条件 所谓自由 ...
- 为什么样本方差分母是n-1
https://blog.csdn.net/qq_39521554/article/details/79633207 为什么样本方差的分母是n-1?为什么它又叫做无偏估计? 至于为什么是n-1,可以看 ...
- 样本方差的无偏估计与(n-1)的由来
一.无偏估计 所谓总体参数估计量的无偏性指的是,基于不同的样本,使用该估计量可算出多个估计值,但它们的平均值等于被估参数的真值. 在某些场合下,无偏性的要求是有实际意义的.例如,假设在某厂商与某销售商 ...
- mode|平均数|方差|标准差|变异系数|四分位数|几何平均数|异众比率|偏态|峰态
应用统计学 数据的概括性度量 集中趋势 Mode众数是唯一描述无序类别数据,由图可知众数便是图形中的峰. 对于类别变量,众数就是某一种类别. 中位数和平均数都可能不是样本中的值. 中位数不受极值影响, ...
- 样本方差:为嘛分母是n-1
在样本方差计算式中,我们使用Xbar代替随机变量均值μ. 容易证明(参考随便一本会讲述样本方差的教材),只要Xbar不等于μ,sigma(Xi-Xbar)2必定小于sigma(Xi-μ)2. 然而,要 ...
- 为什么样本方差(sample variance)的分母是 n-1?
为什么样本方差(sample variance)的分母是 n-1? (補充一句哦,題主問的方差 estimator 通常用 moments 方法估計.如果用的是 ML 方法,請不要多想不是你們想的那樣 ...
- 为什么方差的分母有时是n,有时是n-1 源于总体方差和样本方差的不同
为什么样本方差(sample variance)的分母是 n-1? 样本方差计算公式里分母为n-1的目的是为了让方差的估计是无偏的.无偏的估计(unbiased estimator)比有偏估计(bia ...
- 为什么样本方差除以(n-1)而不是n ?(自由度)
不记得第几次看见样本方差的公式,突然好奇为什么要除以(n-1)而不是n呢?看见一篇文章从定义上和无偏估计推导上讲的很清楚https://blog.csdn.net/fuming2021118535/a ...
- 样本服从正态分布,证明样本容量n乘样本方差与总体方差之比服从卡方分布x^2(n)
样本服从正态分布,证明样本容量n乘样本方差与总体方差之比服从卡方分布x^2(n) 正态分布的n阶中心矩参见: http://www.doc88.com/p-334742692198.html
随机推荐
- Android Studio(二):快捷键设置、插件安装
Android Studio相关博客: Android Studio(一):介绍.安装.配置 Android Studio(二):快捷键设置.插件安装 Android Studio(三):设置Andr ...
- Laravel实现找回密码及密码重置的例子
https://mp.weixin.qq.com/s/PO5f5OJPt5FzUZr-7Xz8-g Laravel实现找回密码及密码重置功能在php实现与在这里实现会有什么区别呢,下面我们来看看Lar ...
- Project Euler Problem 9-Special Pythagorean triplet
我是俩循环暴力 看了看给的文档,英语并不好,有点懵,所以找了个中文的博客看了看:勾股数组学习小记.里面有两个学习链接和例题. import math def calc(): for i in rang ...
- hdu 3466 Proud Merchants(有排序的01背包)
Proud Merchants Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 131072/65536 K (Java/Others) ...
- 条件随机场(CRF) - 2 - 定义和形式
版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/xueyingxue001/article/details/51498968声明: 1,本篇为个人对& ...
- java表达式和三目运算符
是由数字.运算符.数字分组符号(括号)等以能求得数值的有意义排列的序列; a + b 3.14 + a (x + y) * z + 100 boolean b= i < 10 && ...
- Django入门7--博客撰写页面开发
- HDU 3974 Assign the task
Assign the task Problem Description There is a company that has N employees(numbered from 1 to N),ev ...
- yum安装gcc和gcc-c++
本次总结参考 博客:http://blog.csdn.net/robertkun/article/details/8466700 ,非常 感谢他的博客,帮我解决了问题. 今天安装gcc-c++时出现 ...
- es6笔记 day3---对象简介语法以及对象新增
以前的老写法↓ 新写法来了↓ 提示:千万不要手贱,在里面去用箭头函数!!! -------------------------------------------------------------- ...