selenium自动化方式爬取豆瓣热门电影
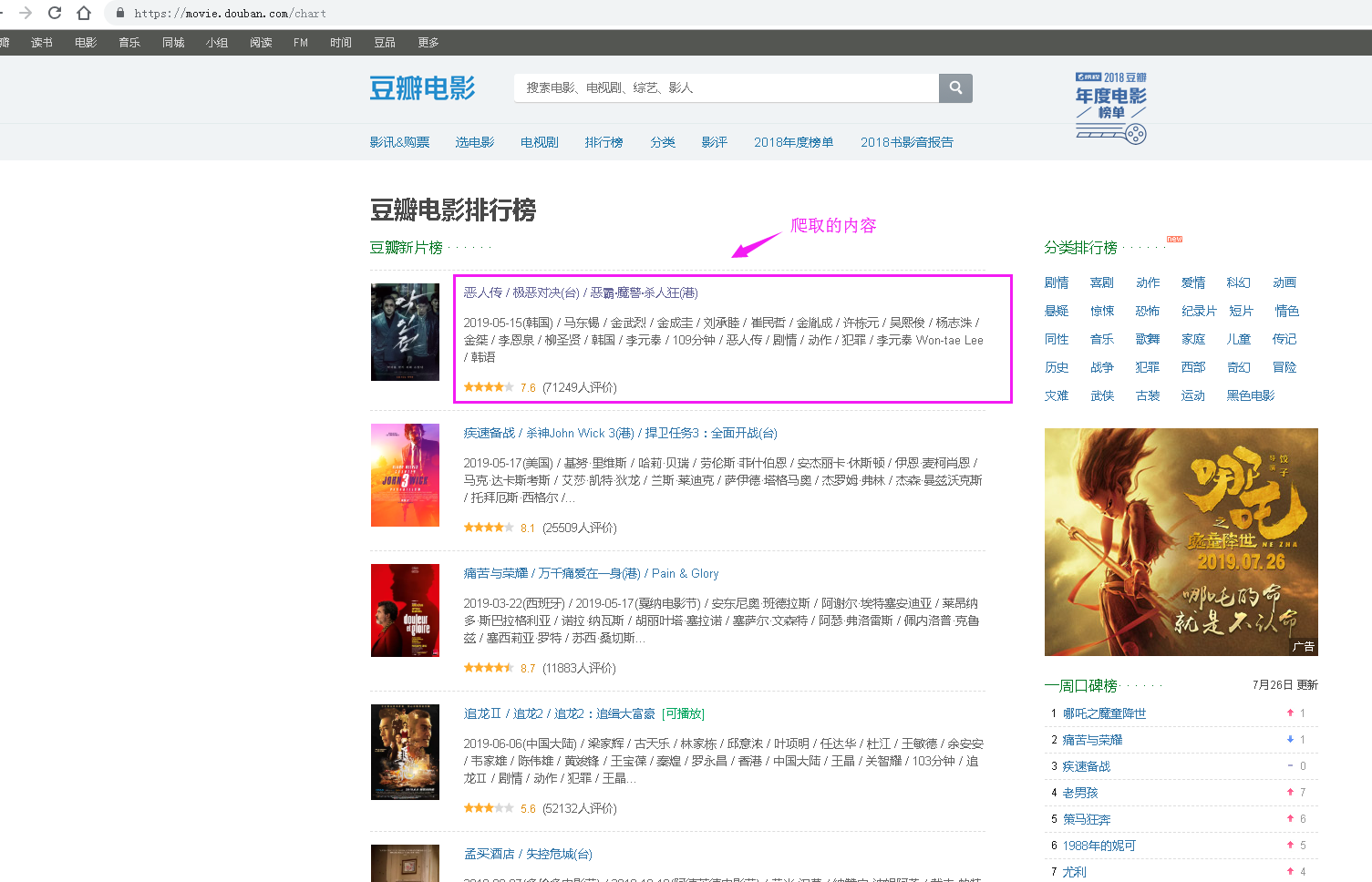
爬取的代码如下:
from selenium import webdriver
from bs4 import BeautifulSoup
import time
#发送请求,获取响应
def get_PageItem():
# 准备url
url='https://movie.douban.com/chart'
#创建一个浏览器对象
driver=webdriver.Chrome()
#发送请求
driver.get(url)
#print(driver.page_source)
page_code=BeautifulSoup(driver.page_source,"lxml")
#print(page_code)
#获取所有的inden类下面的所有table标签
items=page_code.select('.indent table')
return items def start():
"""启动程序"""
#获取当前时间
start_time=time.time()
#接收table标签
items=get_PageItem()
print("用时:",time.time()-start_time,"秒")
for item in items:
#查找电影标题 找到P12的div里面的a标签
name1=item.select("div.pl2 a")[0].text #也可以写成:name=item.select(".p12 a")[0].text
name2=name1.replace(" ","").replace("\n","")
#获取演员列表,上映时间和电影类型
time_person=item.select(".pl")[0].text
#获取评价人数
num=item.select("span.pl")[0].text
#获取评分
score=item.select("span.rating_nums")[0].text
get_star(score)
with open("a.txt",'a',encoding = 'utf-8')as f:#使用with open在使用完成后会直接进行关闭,而直接使用open在使用完成后需要进行关闭,否则会占用内存
f.write("%s\n%s\n%s\n%s\n"%
("电影名称:%s"%name2,
"演员列表:%s"%time_person,
"评分和人数%s%s%s"%(get_star(score),score,num),
"*"*200)) #根据评分显示星星数量
def get_star(score):
#打印出score的数据类型,在python中只有相同的数据类型才能进行乘法和除法操作。
#print(type(score))#打印出来,score是str类型,str类型是不能进行乘法和除法的操作
str1=''
for i in range(0,5):
# # 把score进行强转,转成float类型
if int(float(score)/2 )>i:
str1+="★"
else:
str1 += "☆"
return str1 start()
执行代码后,在a.txt文档中存放爬取的内容如下:

selenium自动化方式爬取豆瓣热门电影的更多相关文章
- 基础爬虫,谁学谁会,用requests、正则表达式爬取豆瓣Top250电影数据!
爬取豆瓣Top250电影的评分.海报.影评等数据! 本项目是爬虫中最基础的,最简单的一例: 后面会有利用爬虫框架来完成更高级.自动化的爬虫程序. 此项目过程是运用requests请求库来获取h ...
- requests库爬取豆瓣热门国产电视剧数据并保存到本地
首先要做的就是去豆瓣网找对应的接口,这里就不赘述了,谷歌浏览器抓包即可,然后要做的就是分析返回的json数据的结构: https://movie.douban.com/j/search_subject ...
- Scrapy 通过登录的方式爬取豆瓣影评数据
Scrapy 通过登录的方式爬取豆瓣影评数据 爬虫 Scrapy 豆瓣 Fly 由于需要爬取影评数据在来做分析,就选择了豆瓣影评来抓取数据,工具使用的是Scrapy工具来实现.scrapy工具使用起来 ...
- requests爬取豆瓣top250电影信息
''' 1.爬取豆瓣top250电影信息 - 第一页: https://movie.douban.com/top250?start=0&filter= - 第二页: https://movie ...
- python3爬取豆瓣top250电影
需求:爬取豆瓣电影top250的排名.电影名称.评分.评论人数和一句话影评 环境:python3.6.5 准备工作: 豆瓣电影top250(第1页)网址:https://movie.douban.co ...
- Python-爬虫实战 简单爬取豆瓣top250电影保存到本地
爬虫原理 发送数据 获取数据 解析数据 保存数据 requests请求库 res = requests.get(url="目标网站地址") 获取二进制流方法:res.content ...
- Python3爬取豆瓣网电影信息
# -*- coding:utf-8 -*- """ 一个简单的Python爬虫, 用于抓取豆瓣电影Top前250的电影的名称 Language: Python3.6 ...
- 爬虫之爬取豆瓣top250电影排行榜及爬取斗图啦表情包解读及爬虫知识点补充
今日内容概要 如何将爬取的数据直接导入Excel表格 #如何通过Python代码操作Excel表格 #前戏 import requests import time from openpyxl impo ...
- 爬取豆瓣TOP250电影
自己跟着视频学习的第一个爬虫小程序,里面有许多不太清楚的地方,不如怎么找到具体的电影名字的,那么多级关系,怎么以下就找到的是那个div呢? 诸如此类的,有许多,不过先做起来再说吧,后续再取去弄懂. i ...
随机推荐
- Luogu P3802 小魔女帕琪(期望)
P3802 小魔女帕琪 题意 题目背景 从前有一个聪明的小魔女帕琪,兴趣是狩猎吸血鬼. 帕琪能熟练使用七种属性(金.木.水.火.土.日.月)的魔法,除了能使用这么多种属性魔法外,她还能将两种以上属性组 ...
- Python基础笔记_变量类型
下面是W3C学习笔记 , , ) :] ]) :]) :]) :-]) :-]) ]) :]) :]) ) , , ]) :]) :]) ) , , , ]) :]) :]) ) ] = , ])) ...
- strict
strict为3.2.3新增连贯操作,用于设置数据写入和查询是否严格检查是否存在字段.默认情况下不合法数据字段自动删除,如果设置了严格检查则会抛出异常. 例如: $model->strict(t ...
- threading.local在flask中的用法
一.介绍 threading.local的作用: 多个线程修改同一个数据,复制多份变量给每个线程用,为每个线程开辟一块空间进行数据的存储,而每块空间内的数据也不会错乱. 二.不使用threading. ...
- 83 落单的数 II
原题网址:http://www.lintcode.com/zh-cn/problem/single-number-ii/ 给出3*n + 1 个的数字,除其中一个数字之外其他每个数字均出现三次,找到这 ...
- 我能不能理解成 ssh中service就相当于与jsp+servlet+dao中的servlet???
转文 首先解释面上意思,service是业务层,dao是数据访问层.(Data Access Objects) 数据访问对象 1.Dao其实一般没有这个类,这一般是指java中MVC架构中的model ...
- jeecms v9 vue-CLI开发环境配置
vue-CLI开发环境配置 Vue.js 提供一个官方命令行工具,可用于快速搭建大型单页应用.该工具提供开箱即用的构建工具配置,带来现代化的前端开发流程.只需几分钟即可创建并启动一个带热重载.保存时静 ...
- poi 3669 meteor shower (bfs)
题目链接:http://poj.org/problem?id=3669 很基础的一道bfs的题,然而,我却mle了好多次,并且第二天才发现错在了哪里_(:з)∠)_ 写bfs或者dfs一定要记得对走过 ...
- SpringBoot 02_返回json数据
在SpringBoot 01_HelloWorld的基础上来返回json的数据,现在前后端分离的情况下多数都是通过Json来进行交互,下面就来利用SpringBoot返回Json格式的数据. 1:新建 ...
- Linux 静态IP配置
静态配置文件# vim /etc/sysconfig/network-scripts/ifcfg-不同系统不一样主要几个配置TYPE=EthernetBOOTPROTO=static/noneNAME ...