find()和find_all()的具体使用
在我们学会了BeautifulSoup库的用法后,我们就可以使用这个库对HTML进行解析,从网页中提取我们需要的内容。
在BeautifulSoup 文档里,find()、find_all()两者的定义如下:
find(tag, attributes, recursive, text, keywords)
find(标签,属性,递归,文本,关键词)
find_all(tag, attributes, recursive, text, limit, keywords)
find_all(标签、属性、递归、文本、限制、关键词)
find()与find_all()的区别,find()只会取符合要求的第一个元素,find_all()会根据范围限制参数limit限定的范围取元素(默认不设置代表取所有符合要求的元素,find 等价于 find_all的 limit =1 时的情形),接下来将对每个参数一一介绍。
另外,find_all()会将所有满足条件的值取出,组成一个list
下面我们就一一介绍函数中各个参数的作用:
一、标签tag
标签参数 tag 可以传一个标签的名称或多个标签名称组成的set做标签参数。例如,下面的代码将返回一个包含 HTML 文档中所有链接标签的列表: find_all("a")
下面以“百度一下”网页举例,如下图,现在要将百度页面上的所有的链接取出,观察网页源代码可以发现,标题对应的tag 是a,则soup.find_all('a')
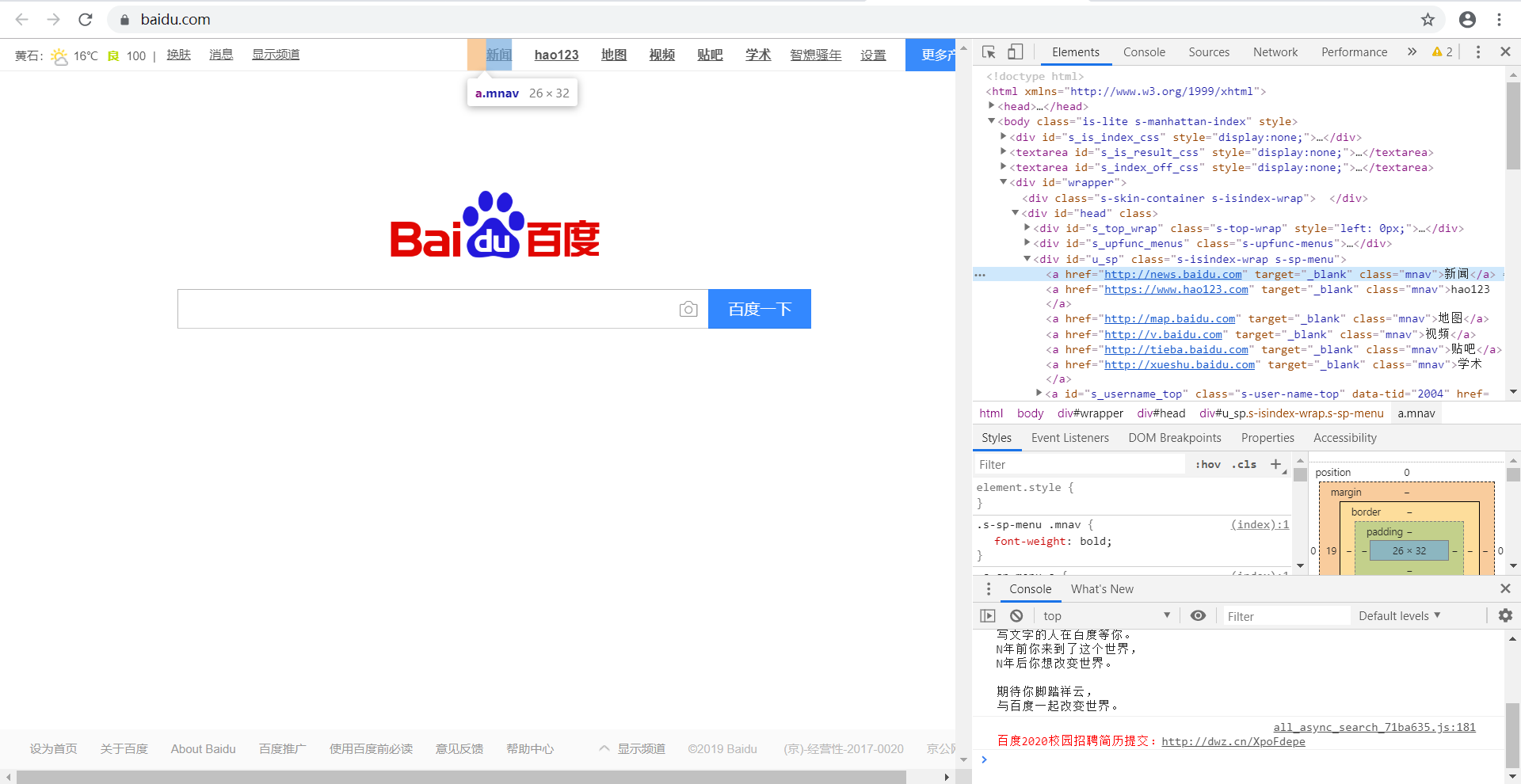
代码如下:
from bs4 import BeautifulSoup
import requests url = 'https://www.baidu.com/'
urlhtml = requests.get(url)
urlhtml.encoding = 'utf-8'
soup = BeautifulSoup(urlhtml.text, 'lxml') n = soup.find_all('a')
print(n)
结果如下,我们就找出了全部的<a>标签。

上面例子只是一个标签的情况,如果多个标签写法相同,只是注意要将所有的标签写在一个set里面
二、属性attributes
属性参数 attributes 是用字典封装一个标签的若干属性和对应的属性值。如,下面这个函数会返回 HTML 文档里“mnav”的a标签。find_all("a", {"class":{"mnav"}})
如下图,现在要获取网页中的“新闻”等信息,通过观察可知,它们的属性为"mnav",标签为a。
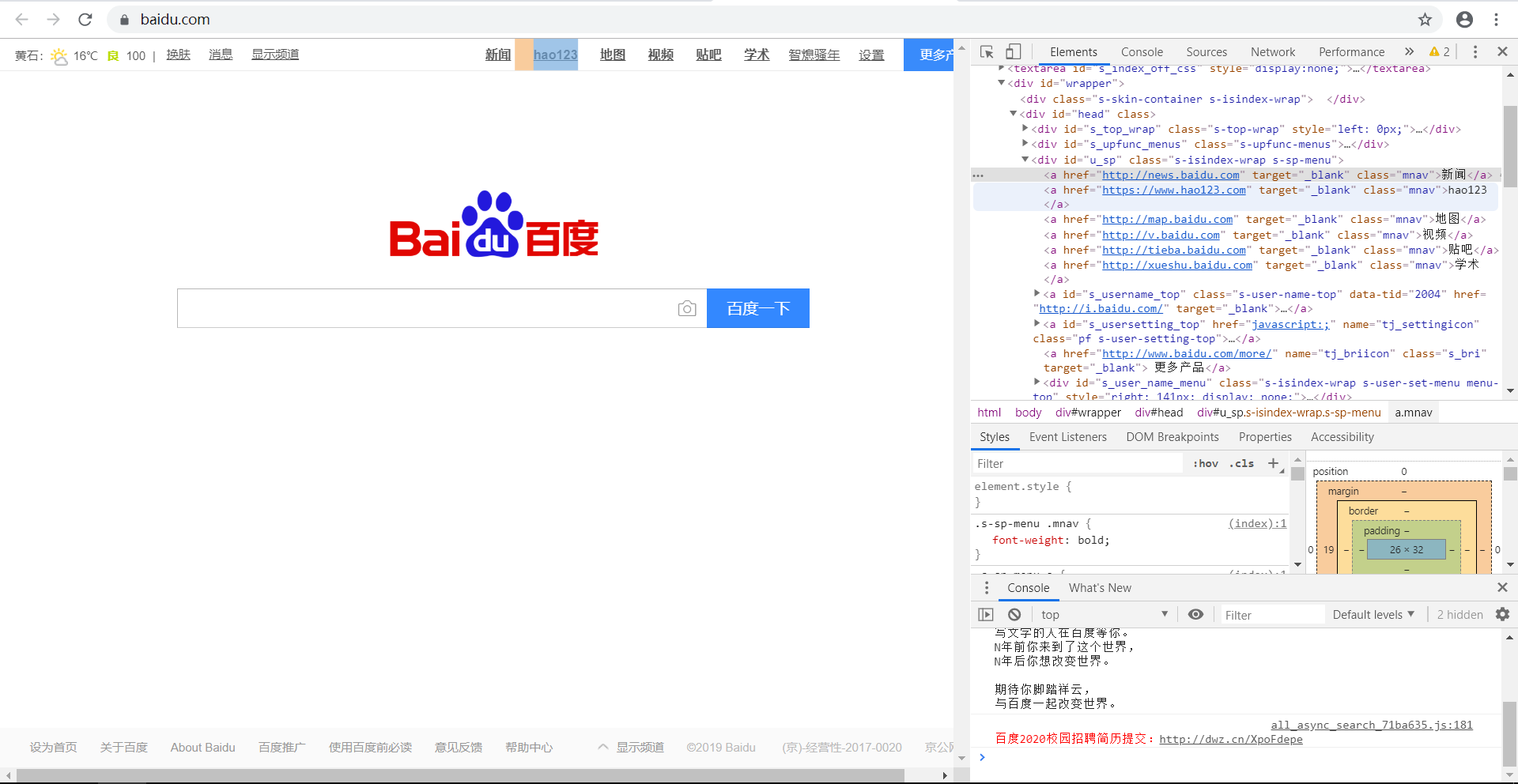
则我们可以编写代码:
from bs4 import BeautifulSoup
import requests url = 'https://www.baidu.com/'
urlhtml = requests.get(url)
urlhtml.encoding = 'utf-8'
soup = BeautifulSoup(urlhtml.text, 'lxml')
n = soup.find_all('a', {'class': 'mnav'})
print(n)
运行结果如下,可以看出输出的链接的属性全部为“mnav”。

三、递归recursive
递归参数 recursive 是一个布尔变量。你想抓取 HTML 文档标签结构里多少层的信息?如recursive 设置为 True, find_all()就会根据你的要求去查找标签参数的所有子标签,以及标签的子标签。如果 recursive 设置为 False, find_all()就只查找文档的一级标签。 find_all默认是支持递归查找的(recursive 默认值是 True),这里是很少使用的,所以我在这儿就不在举例了。
四、文本text
文本参数 text 有点不同,它是用标签的文本内容去匹配,而不是用标签的属性。
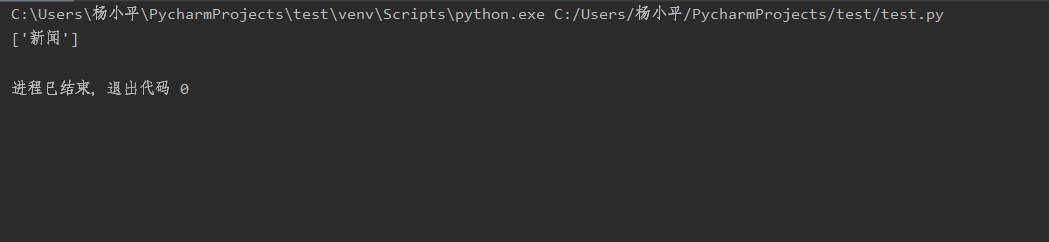
我们再以“百度一下”的网页举例吧,在这个网页中,我们查找一下“新闻”在该网页中出现了多少个(其实只出现了一个)
from bs4 import BeautifulSoup
import requests url = 'https://www.baidu.com/'
urlhtml = requests.get(url)
urlhtml.encoding = 'utf-8'
soup = BeautifulSoup(urlhtml.text, 'lxml') n = soup.find_all(text='新闻')
print(n)
结果如下:
需要特别注意一点,这里查找是用的是完全匹配原则,意思是如果这里你用了find_all(text=“新”),得到的结果会是0个
五、关键词keywords
关键词参数 keyword,自己选择那些具有指定属性的标签
上面网页的内容,现在要取id='wrapper'的内容,则
from bs4 import BeautifulSoup
import requests url = 'https://www.baidu.com/'
urlhtml = requests.get(url)
urlhtml.encoding = 'utf-8'
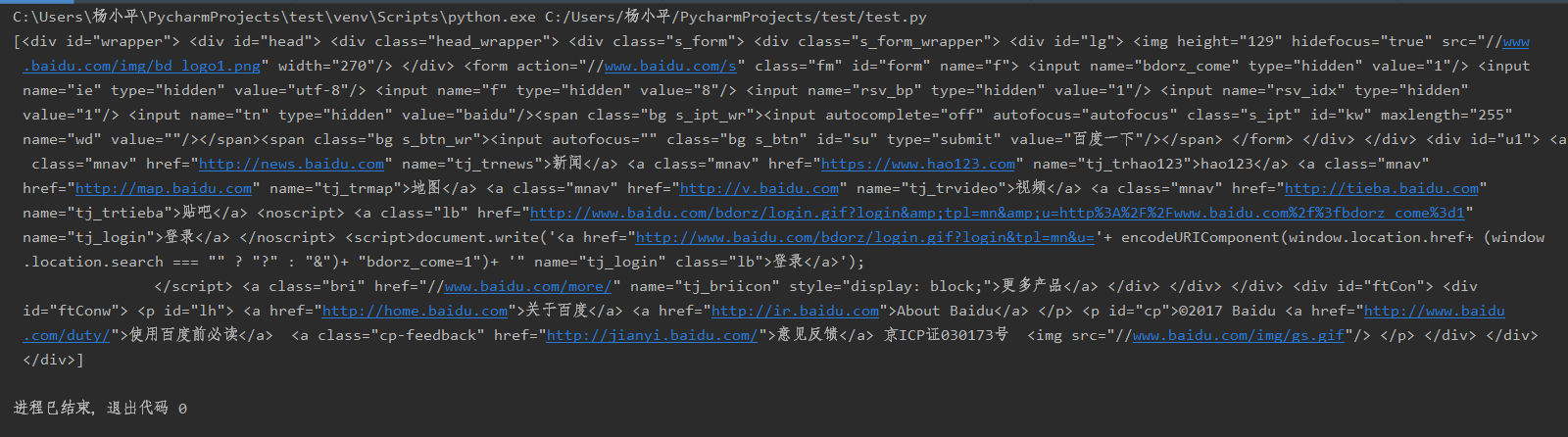
soup = BeautifulSoup(urlhtml.text, 'lxml') n = soup.find_all(id='wrapper')
print(n)
结果如下,也就是选中的<div>中的内容
注意:如果是class、id等参数,用keywords 或者attributes用法一样,如果是一些其他参数,则用keywords
find()和find_all()的具体使用的更多相关文章
- python3爬虫(find_all用法等)
#read1.html文件 # <html><head><title>The Dormouse's story</title></head> ...
- BeautifulSoup中的find,find_all
1.一般来说,为了找到BeautifulSoup对象内任何第一个标签入口,使用find()方法. 以上代码是一个生态金字塔的简单展示,为了找到第一生产者,第一消费者或第二消费者,可以使用Beautif ...
- BeautifulSoup4----利用find_all和get方法来获取信息
中文文档 官方教学网页源码: <html> <head> <title>Page title</title> </head> <bod ...
- find 和 find_all 用法
soup = BeautifulSoup(requests.get(url).text, 'html.parser') soup.find('span', class_='item_hot_topic ...
- python爬虫(1)——BeautifulSoup库函数find_all() (转)
原文地址:http://blog.csdn.net/depers15/article/details/51934210 python--BeautifulSoup库函数find_all() 一.语法介 ...
- python3爬虫03(find_all用法等)
#read1.html文件# <html><head><title>The Dormouse's story</title></head># ...
- python 学习之FAQ:find 与 find_all 使用
FAQ记录 1. 错误源码 错误源码如下 def fillUnivList(_html,_ulist): soup =BeautifulSoup(_html,'html.parser') fo ...
- BS4(BeautifulSoup4)的使用--find_all()篇
可以直接参考 BS4文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#find-all 注意的是: 1.有些 ...
- find_all的用法 Python(bs4,BeautifulSoup)
find_all()简单说明: find_all() find_all() 方法搜索当前tag的所有tag子节点,并判断是否符合过滤器的条件 用法一: rs=soup.find_all('a') 将返 ...
随机推荐
- 使用subprocessm模块管理进程
subprocess被用来替换一些老的模块和函数,如:os.system.os.spawn*.os.popen*.popen2.*.commands.*. subprocess的目的就是启动一个新的进 ...
- Tree and Permutation (HDU 6446) 题解
// 昨天打了一场网络赛,表现特别不好,当然题目难度确实影响了发挥,但还是说明自己太菜了,以后还要多多刷题. 2018 CCPC 网络赛 I - Tree and Permutation 简单说明一下 ...
- 用python打造简单的cms识别
代码 #!/usr/bin/env python3 # coding:utf-8 #lanxing #判断代码,判断是否安装requests库 try: import requests except: ...
- 《DSP using MATLAB》Problem 8.28
代码: %% ------------------------------------------------------------------------ %% Output Info about ...
- vue 使用QRcode生成二维码或在线生成二维码
参考:https://blog.csdn.net/zhuswy/article/details/80267748 1.安装qrcode.js npm install qrcodejs2 --save ...
- API 练习 第一篇
练习API CreateSemaphoreCreateEvent ReleaseSemapWaitForSingleObject CloseHandleInitializeCriticalSec ...
- 跟我一起实战美团网一之[nodemon] app crashed - waiting for file changes before starting...
环境准备 第一步安装 npm install -g npx npx create-nuxt-app at-app 与事件相关的包我们再安装一次 npm install --update-binary ...
- ubuntu 安装samba共享文件夹
安装samba sudo apt-get install samba smbclient 配置samba sudo cp /etc/samba/smb.conf /etc/samba/smb.conf ...
- [转]WPF中Binding的技巧
在WPF应用的开发过程中Binding是一个非常重要的部分. 在实际开发过程中Binding的不同种写法达到的效果相同但事实是存在很大区别的. 这里将实际中碰到过的问题做下汇总记录和理解. 1. so ...
- odoo:Actions
actions定义了系统对于用户的操作的响应:登录.按钮.选择项目等. 一:窗口action(ir.actions.act_window ) 最常用的action类型,用于将model的数据展示出来. ...