一个神奇的Python库:Evidently,机器学习必备
Evidently 是一个面向数据科学家和机器学习工程师的开源 Python 库。它有助于评估、测试和监控从验证到生产的数据和 ML 模型。它适用于表格、文本数据和嵌入。
简介
Evidently 是一个开源的 Python 工具,旨在帮助构建对机器学习模型的监控,以确保它们的质量和在生产环境运行的稳定性。
它可以用于模型生命周期的多个阶段:作为 notebook 中检查模型的仪表板,作为 pipeline 的一部分,或者作为部署后的监控。
Evidently 特别关注模型漂移,同时也提供了模型质量检查、数据质量检查和目标漂变监测等功能。此外,它还提供了多种内置的指标、可视化图形和测试,可以轻松地放入报告、仪表板或测试驱动的 pipeline 中。
功能
Evidently采用了由 3 个组件组成的模块化方法:报告、测试套件和监控仪表板。
它们涵盖不同的使用场景:从临时分析到自动化管道测试和持续监控。
1. 测试套件:批量模型检查
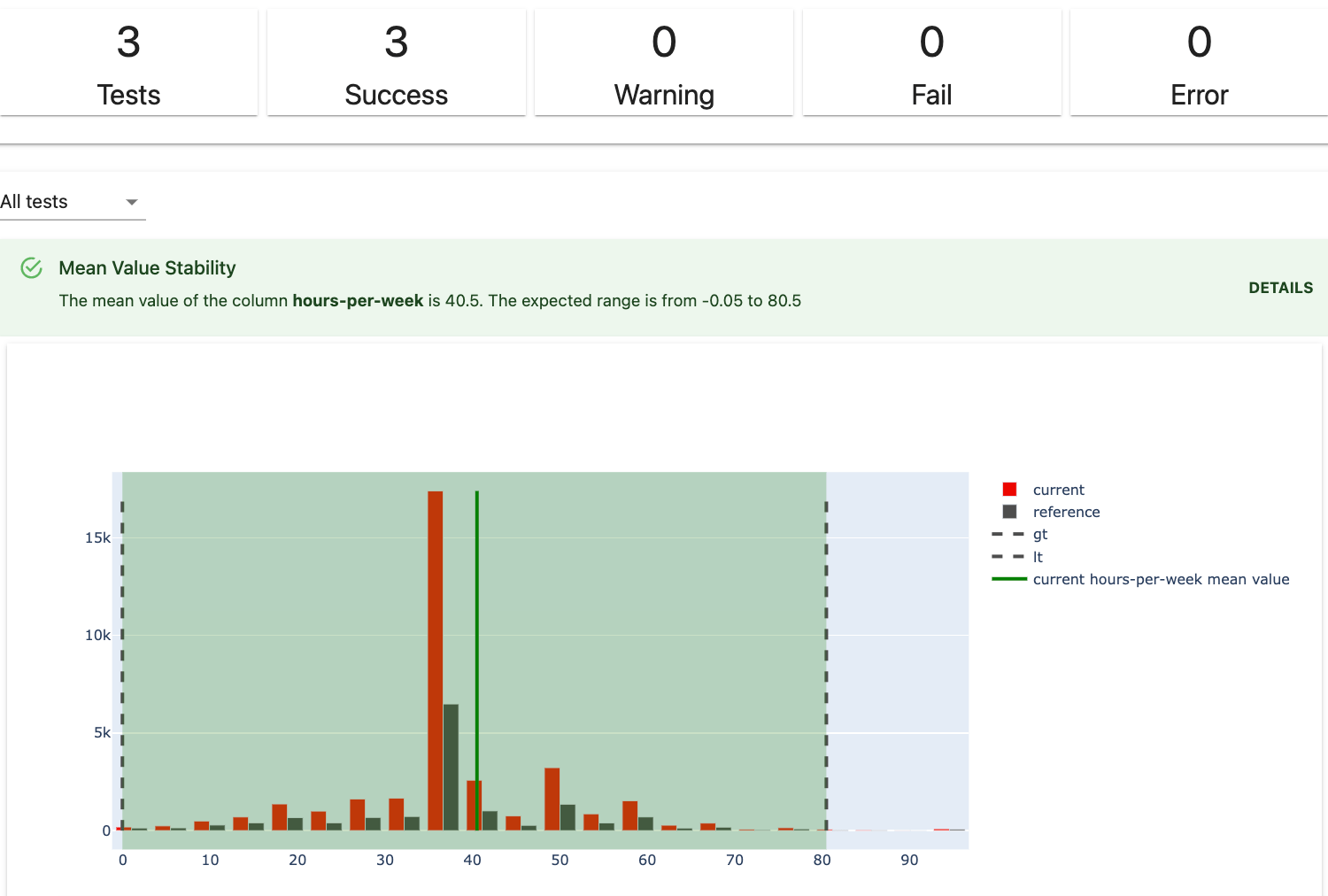
测试执行结构化数据和机器学习模型质量检查,可以手动设置条件,也可以让 Evidently 根据参考数据集生成条件,返回明确的通过或失败结果。可以从 50 多个测试创建测试套件或运行预设之一。例如,测试数据稳定性或回归性能。
输入:一个或两个数据集,如 pandas.DataFrames 或 csv。
获取输出:在 Jupyter Notebook 或 Colab 中,导出 HTML、JSON 或 Python 字典。
主要用例:基于测试的机器学习监控,以将测试作为机器学习管道中的一个步骤来运行。例如,当收到一批新的数据、标签或生成预测时。可以根据结果构建条件工作流程,例如触发警报、重新训练或获取报告。
2. 报告:交互式可视化

计算各种指标并提供丰富的交互式可视化报告,可以根据各个指标创建自定义报告,或运行涵盖模型或数据性能特定方面的预设。例如,数据质量或分类性能。
输入:一个或两个数据集,如 pandas.DataFrames 或 csv。
如何获取输出:在 Jupyter Notebook 或 Colab 中,导出 HTML 文件、JSON 或 Python 字典。
主要用例:分析和探索,有助于直观地评估数据或模型性能。例如,在探索性数据分析期间、对训练集进行模型评估、调试模型质量衰减时或比较多个模型时。
3. 机器学习监控仪表板

您可以自行托管机器学习监控仪表板,以随着时间的推移可视化指标和测试结果。此功能位于报告和测试套件之上,必须将它们的输出存储为 Evidently JSON snapshots,作为 Evidently Monitoring UI 的数据源。
输入:snapshots,记录到对象存储中。
输出:可作为网络应用程序使用的自托管仪表板。
主要用例:当需要实时仪表板来查看一段时间内的所有模型和指标时,持续监控。
安装&使用
pip install evidently
pip install jupyter
# 安装 jupyter Nbextion
pip install jupyter_contrib_nbextensions
# 在 jupyter 扩展中安装并启用 evidently
jupyter nbextension install --sys-prefix --symlink --overwrite --py evidently
jupyter nbextension enable evidently --py --sys-prefix
大部分情况下,需要在Jupyter notebook中使用。
使用步骤很简单,一般分三步:1、导入模块 2、处理数据 3、获取报告
举个例子,先导入所需模块
import pandas as pd
import numpy as np
from sklearn.datasets import fetch_california_housing
from evidently import ColumnMapping
from evidently.report import Report
from evidently.metrics.base_metric import generate_column_metrics
from evidently.metric_preset import DataDriftPreset, TargetDriftPreset, DataQualityPreset, RegressionPreset
from evidently.metrics import *
from evidently.test_suite import TestSuite
from evidently.tests.base_test import generate_column_tests
from evidently.test_preset import DataStabilityTestPreset, NoTargetPerformanceTestPreset
from evidently.tests import *
导入和处理数据
data = fetch_california_housing(as_frame=True)
housing_data = data.frame
housing_data.rename(columns={'MedHouseVal': 'target'}, inplace=True)
housing_data['prediction'] = housing_data['target'].values + np.random.normal(0, 5, housing_data.shape[0])
reference = housing_data.sample(n=5000, replace=False)
current = housing_data.sample(n=5000, replace=False)
获取报告
report = Report(metrics=[
DataDriftPreset(),
])
report.run(reference_data=reference, current_data=current)
report

官方提供了很多获取报告的代码模板:https://docs.evidentlyai.com/presets/all-presets
evidently 功能十分强大,这里展示的只是其能力的冰山一角。了解更多,可以参考以下链接:
官网:https://www.evidentlyai.com/
文档:https://docs.evidentlyai.com/
开源地址:https://github.com/evidentlyai/evidently

一个神奇的Python库:Evidently,机器学习必备的更多相关文章
- 一个交互式可视化Python库——Bokeh
本篇为<Python数据可视化实战>第十篇文章,我们一起学习一个交互式可视化Python库--Bokeh. Bokeh基础 Bokeh是一个专门针对Web浏览器的呈现功能的交互式可视化Py ...
- 数据处理一条龙!这15个Python库不可不知
如果你是一名数据科学家或数据分析师,或者只是对这一行业感兴趣,那下文中这些广受欢迎且非常实用的Python库你一定得知道. 从数据收集.清理转化,到数据可视化.图像识别和网页相关,这15个Python ...
- python库-Arrow处理时间
Arrow是一个处理时间的python库,能一键转换dates/times/timestamps等时间格式而不需要大量导致各种时间模块和格式转换函数,十分快捷方便 使用Arrow需要两步转换操作: 1 ...
- 初识TPOT:一个基于Python的自动化机器学习开发工具
1. TPOT介绍 一般来讲,创建一个机器学习模型需要经历以下几步: 数据预处理 特征工程 模型选择 超参数调整 模型保存 本文介绍一个基于遗传算法的快速模型选择及调参的方法,TPOT:一种基于Pyt ...
- 机器学习 python库 介绍
开源机器学习库介绍 MLlib in Apache Spark:Spark下的分布式机器学习库.官网 scikit-learn:基于SciPy的机器学习模块.官网 LibRec:一个专注于推荐算法的j ...
- 推荐5个机器学习Python 库,国内外评价超高
机器学习令人无比神往,但从事这个工作的人可能并不这么想. 机器学习的工作内容往往复杂枯燥又困难——通过大量重复工作进行提升必不可少: 汇总工作流及传输渠道.设置数据源以及在内部部署和云部署的资源之间来 ...
- sopt:一个简单的python最优化库
引言 最近有些朋友总来问我有关遗传算法的东西,我是在大学搞数学建模的时候接触过一些最优化和进化算法方面的东西,以前也写过几篇博客记录过,比如遗传算法的C语言实现(一):以非线性函数求极值为例和 ...
- 程序员用于机器学习数据科学的3个顶级 Python 库
NumPy NumPy(数值 Python 的简称)是其中一个顶级数据科学库,它拥有许多有用的资源,从而帮助数据科学家把 Python 变成一个强大的科学分析和建模工具.NumPy 是在 BSD 许可 ...
- #华为云·寻找黑马程序员# 如何实现一个优雅的Python的Json序列化库
在Python的世界里,将一个对象以json格式进行序列化或反序列化一直是一个问题.Python标准库里面提供了json序列化的工具,我们可以简单的用json.dumps来将一个对象序列化.但是这种序 ...
- 从开发属于你自己的第一个 Python 库,做一名真正的程序员「双语版」
你好,我是悦创.之前我在 CSDN 编写了一篇开发 Python 库的教程,有人加我提问到的一些问题,我来更新一下这篇文章:https://blog.csdn.net/qq_33254766/arti ...
随机推荐
- [ORB/BEBLID] 利用OpenCV(C++)实现尺度不变性与角度不变性的特征找图算法
本文只发布于利用OpenCV实现尺度不变性与角度不变性的特征找图算法和知乎 一般来说,利用OpenCV实现找图功能,用的比较多的是模板匹配(matchTemplate).笔者比较喜欢里面的NCC算法. ...
- webpack 从 v4 升级到 v5
准备工作 Node.js 至少升级到 v10.13.x 以上. 其它 修改 webpack.config.js 配置,以及部分老的 webpack 插件要更新. 参考 中文版 从 v4 升级到 v5 ...
- 文心一言 VS 讯飞星火 VS chatgpt (141)-- 算法导论12.1 1题
一.用go语言,对于关键字集合(1,4,5,10,16,17,21),分别画出高度为 2.3.4.5和6的二又搜索树. 文心一言: 以下是用Go语言为给定的关键字集合(1, 4, 5, 10, 16, ...
- PX4安装环境测试
1.ROS环境测试 安装ROS版本:melodic roscore // 注意下面是打开一个新的终端,roscore一直在运行 rosrun turtlesim turtlesim_node // 再 ...
- 明解Java第二章练习题答案
练习2-1 请对代码清单2-6的2处进行修改,将带有小数部分的实数值赋给x和y,查看结果如何? 答案:编译器会报错,因为小数的默认类型double是比int更大的类型.如果给double类型的变量赋值 ...
- HTTPClients使用
一. 创建httpclient对象用于发送get.post等请求 1. HttpClients.custom()的方式--自定义httpclient对象,多用于含有cookie的请求 1. Cooki ...
- Optional源码分析(涉及Objects源码和Stream源码)
研究Optional源码之前先谈一谈Objects源码. 主要代码: @ForceInline public static <T> T requireNonNull(T obj) { if ...
- [ABC263G] Erasing Prime Pairs
Problem Statement There are integers with $N$ different values written on a blackboard. The $i$-th v ...
- scroll-view和swiper的使用
源码: <template> <viex class="out"> <view class="b ...
- CompletableFuture异步编程
1.创建 /** * public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier ...