kettle从入门到精通 第六十六课 ETL之kettle kettle阻塞教程,轻松获取最后一行数据,so easy
场景:ETL沟通交流群内有小伙伴反馈,如何在同步一批数据完成之后记录下同步结果呢?或者是调用后续步骤、存储过程、三方接口等。
解决:使用步骤Blocking step进行阻塞处理即可。
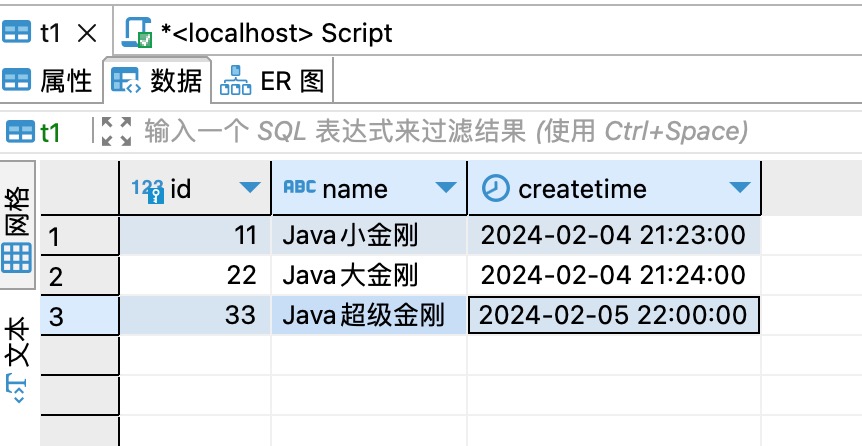
1、下面的demo演示从表t1同步数据至表t2(t1表中有三条数据,t2为空表,两个表表结构相同),然后数据同步完毕之后进行其他操作,这里的只是打个日志记录下最后一行数据,如下图所示:
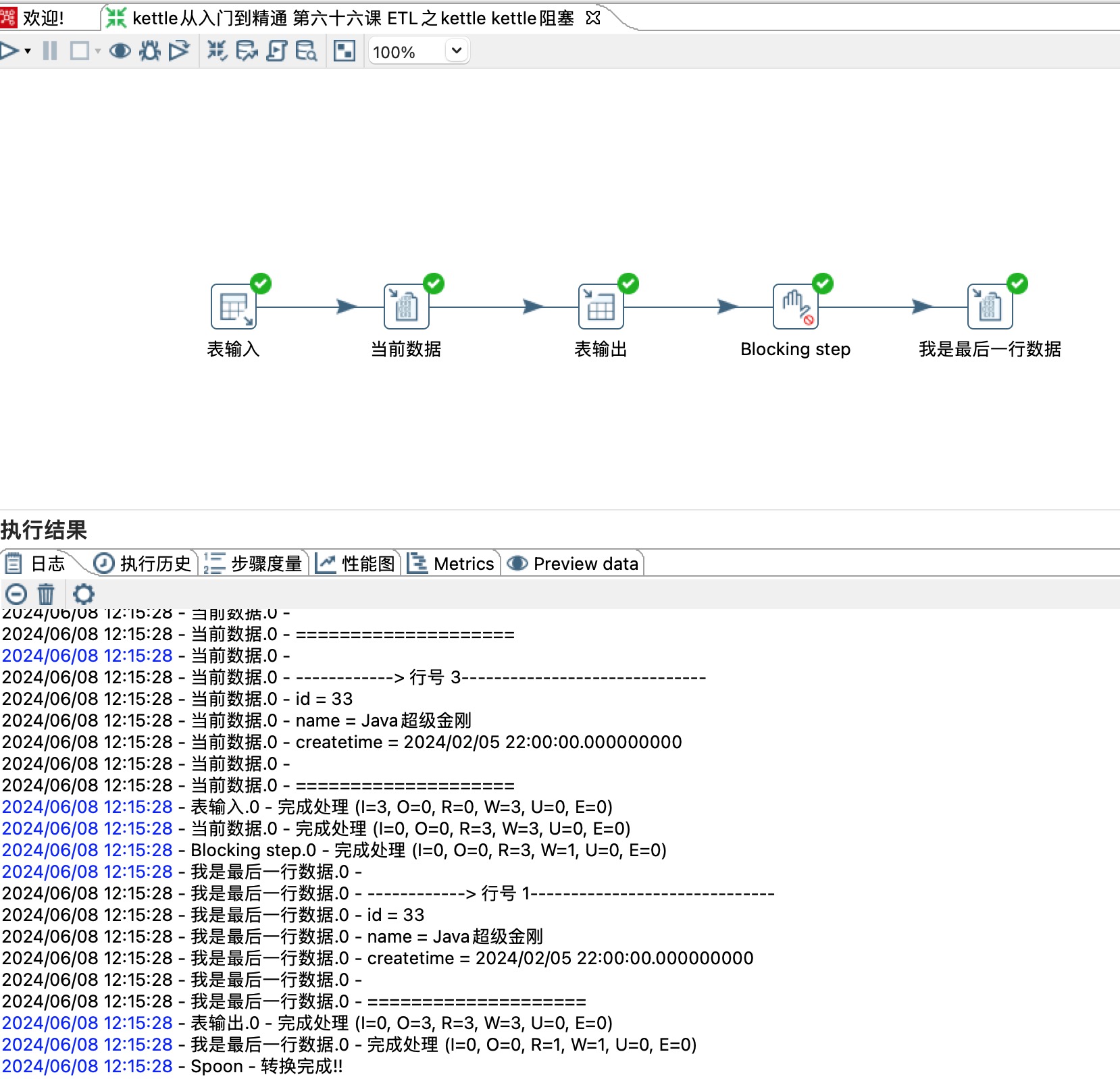
1)从图片日志可以很清晰的看到,当前数据打印了三次,表输入和表输出也都执行了3次。
2)从图片日志可以很清晰的看到,Blocking step 读取了三条数据,只写了一条数据。
3)从图片日志可以很清晰的看到,Blocking step 后面的日志步骤只打印了最后一行数据。
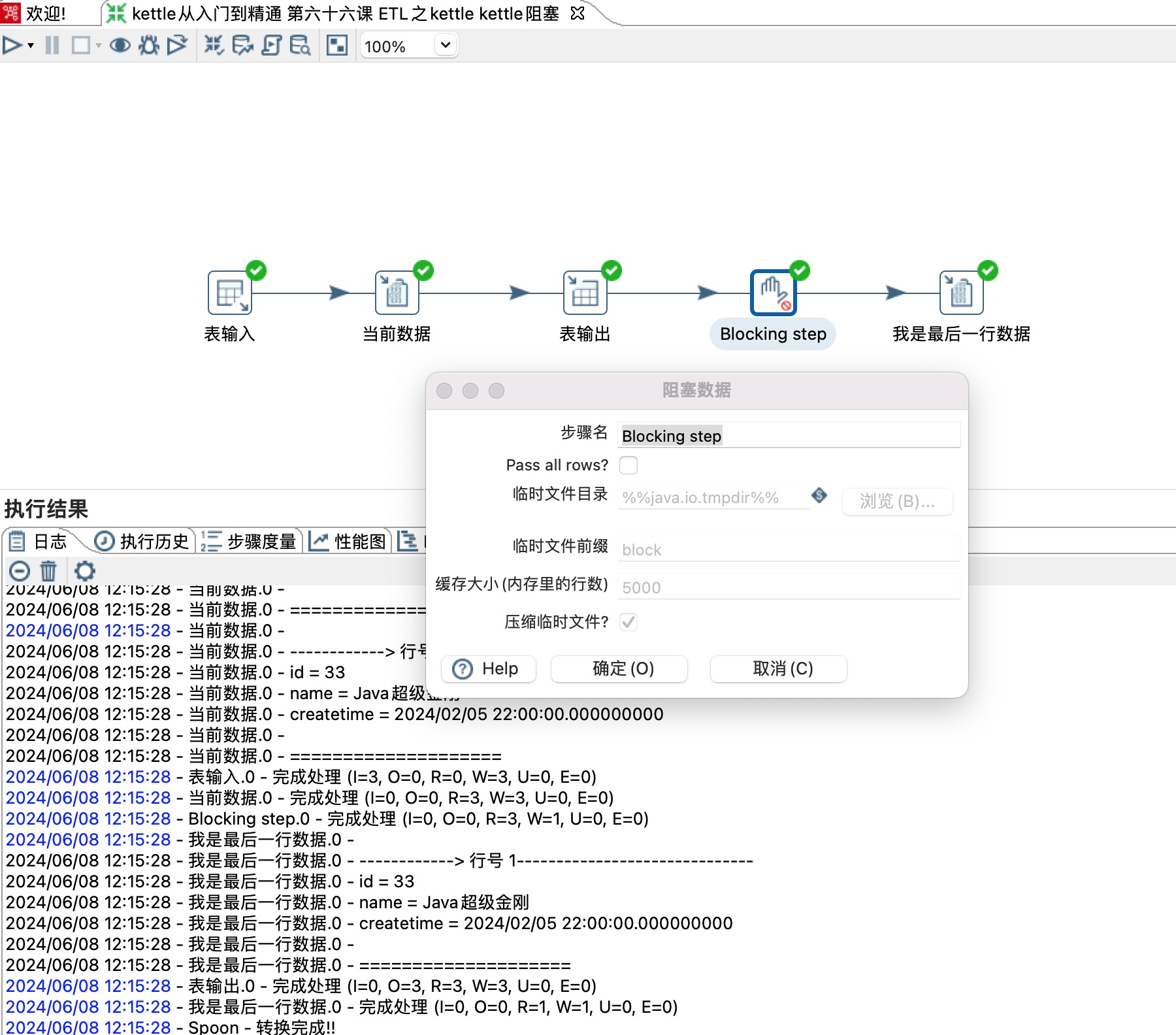
2、Blocking step配置,双击步骤打开配置项。
Pass all rows?:若不勾选,表输出步骤成功写入3条数据之后只有最后一条数据才会通过Blocking step步骤传递给之后的步骤。如下图所示:
3、Pass all rows?:若勾选,表输出步骤成功写入3条数据之后所有数据都会通过Blocking step步骤传递给之后的步骤。如下图所示:
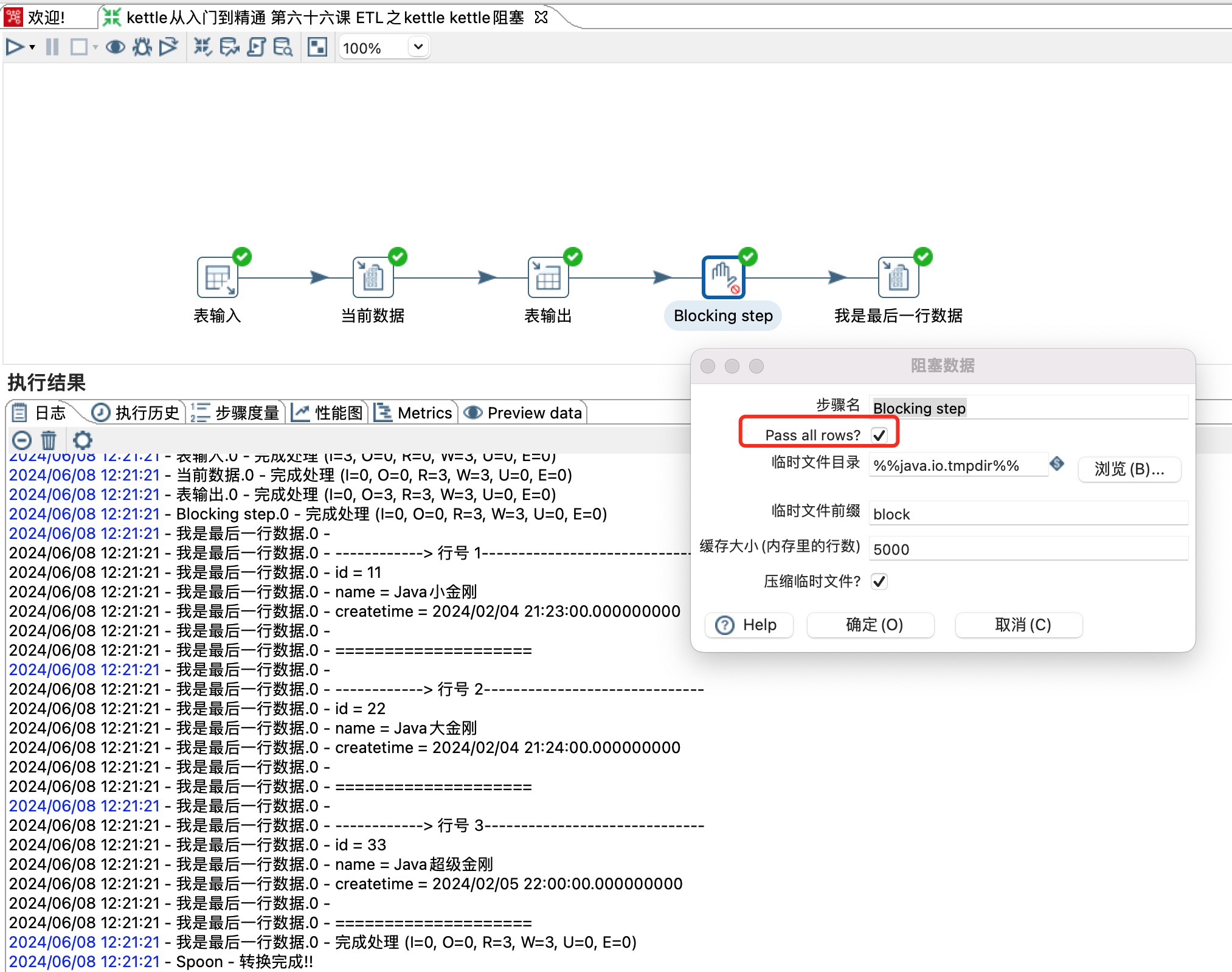
1)从图片日志可以很清晰的看到,Blocking step 读取了三条数据,写了三条数据。
2)从图片日志可以很清晰的看到,虽然Blocking step 写了三条数据,但是执行顺序依然是在Blocking step的前置步骤表输出完毕之后。
4、缓存大小配置,行数设置的越大,该步骤执行的效率也就越高,否则会频繁操作临时文件。
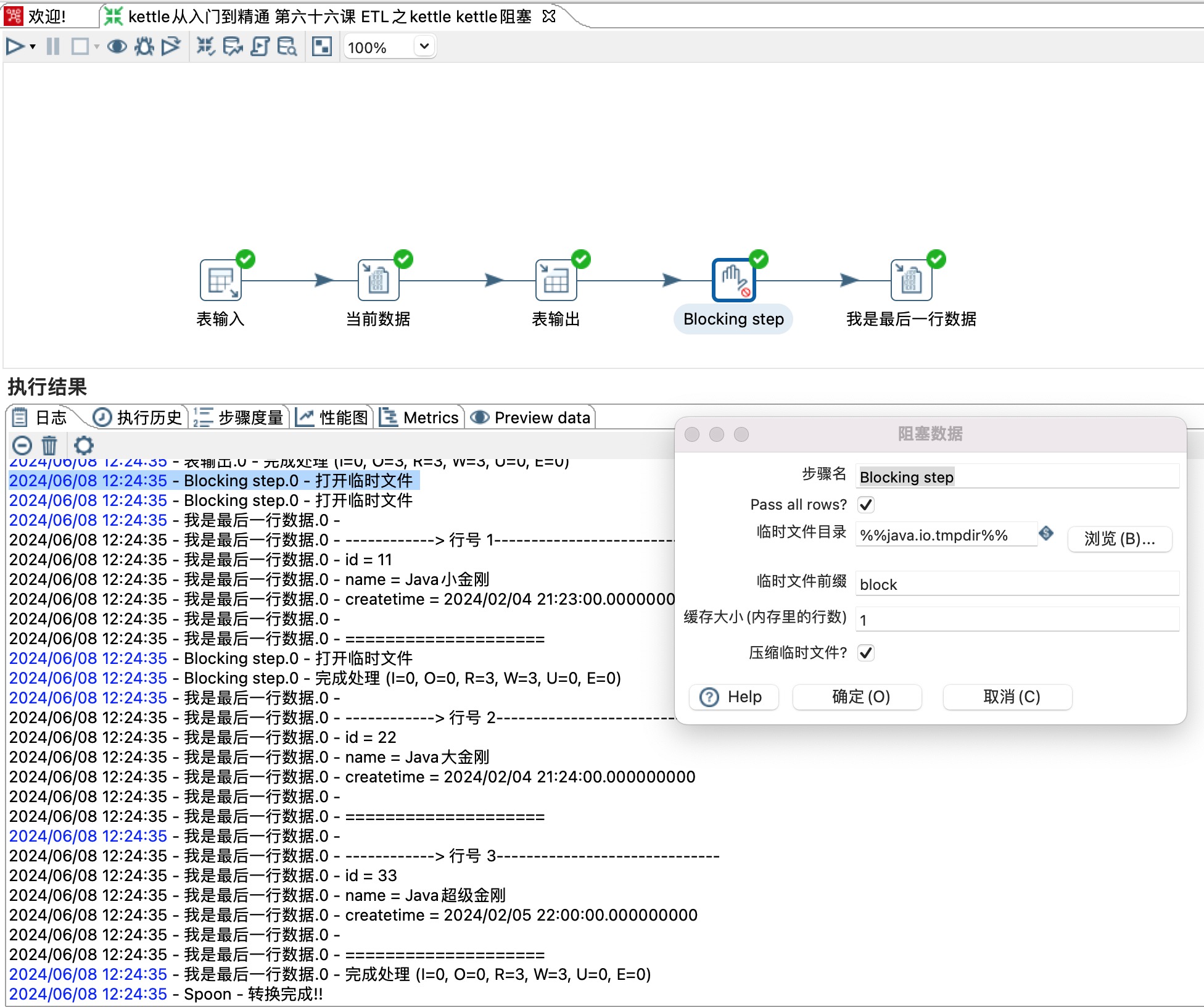
上图步骤中将缓存大小设置为1,从日志来看Blocking step步骤就打印了“打开临时文件”,很显然缓存大小设置的行数太小会降低性能。这里使用的时候根据自己的机器实际内存情况来定。

kettle从入门到精通 第六十六课 ETL之kettle kettle阻塞教程,轻松获取最后一行数据,so easy的更多相关文章
- Jmeter(三十九) - 从入门到精通进阶篇 - Jmeter配置文件的刨根问底 - 上篇(详解教程)
------------------------------------------------------------------- 转载自:北京-宏哥 https://www.cnblogs.co ...
- 第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询
第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询 bool查询说明 filter:[],字段的过滤,不参与打分must:[] ...
- “全栈2019”Java第六十六章:抽象类与接口详细对比
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java第 ...
- 《手把手教你》系列技巧篇(六十六)-java+ selenium自动化测试 - 读写excel文件 - 上篇(详细教程)
1.简介 在自动化测试,有些我们的测试数据是放到excel文件中,尤其是在做数据驱动测试的时候,所以需要懂得如何操作获取excel内的内容.由于java不像python那样有直接操作Excle文件的类 ...
- Jmeter(四十) - 从入门到精通进阶篇 - Jmeter配置文件的刨根问底 - 中篇(详解教程)
1.简介 为什么宏哥要对Jmeter的配置文件进行一下讲解了,因为有的童鞋或者小伙伴在测试中遇到一些需要修改配置文件的问题不是很清楚也不是很懂,就算修改了也是模模糊糊的.更有甚者觉得那是禁地神圣不可轻 ...
- 学习C++从入门到精通的的十本最经典书籍
原文:http://blog.csdn.net/a_302/article/details/17558369 最近想学C++,找了一下网上推荐的书籍,转载过来给大家分享 转载自http://c.chi ...
- Spark入门到精通--(第十节)环境搭建(ZooKeeper和kafka搭建)
上一节搭建完了Hive,这一节我们来搭建ZooKeeper,主要是后面的kafka需要运行在上面. ZooKeeper下载和安装 下载ZooKeeper 3.4.5软件包,可以在百度网盘进行下载.链接 ...
- Redis入门到高可用(十六)—— 持久化
一.持久化概念 二.持久化方式 三.redis持久化方式之——RDB 1.什么是RDB 在 Redis 运行时, RDB 程序将当前内存中的数据库快照保存到磁盘文件中, 在 Redis 重启动时, R ...
- Dubbo入门到精通学习笔记(六):持续集成管理平台之Hudson 持续集成服务器的安装配置与使用
文章目录 安装Hudson 使用Hudson tips:自动化部署 附录:两个脚本 安装Hudson IP:192.168.4.221 8G 内存(Hudson 多个工程在同时构建的情况下比较耗内存) ...
- Jmeter(二十八) - 从入门到精通 - Jmeter Http协议录制脚本工具-Badboy1(详解教程)
1.简介 在使用jmeter自动录制脚本时会产生很多无用的请求,所以推荐使用badboy录制脚本之后保存为jmx文件,在jmeter中打开使用.因此宏哥在这里介绍一下Badboy这款工具,本来打算不做 ...
随机推荐
- 使用Databricks+Mlflow进行机器学习模型的训练和部署【Databricks 数据洞察公开课】
简介: 介绍如何使用Databricks和MLflow搭建机器学习生命周期管理平台,实现从数据准备.模型训练.参数和性能指标追踪.以及模型部署的全流程. 作者:李锦桂 阿里云开源大数据平台开发工程 ...
- 比心云平台基于阿里云容器服务 ACK 的弹性架构实践
简介:本文主要探讨比心云平台如何利用阿里云容器服务 ACK,来构建应用弹性架构,进一步优化计算成本. 作者:韩韬|比心技术 前言 应用容器化改造后,不可避免地会面临这样一个问题:Kubernetes ...
- 重磅发布 阿里云数据中台全新产品DataTrust聚焦企业数据安全保障
简介: DataTrust(隐私增强计算产品)是基于阿里云底层多项基础安全能力,经过阿里云数据中台丰富的客户业务实践,构建的一款为企业数据安全流通的产品. 随着包括零售.制造.金融等多行业数字化转型加 ...
- [FAQ] Solidity 并发执行 ? 重入攻击 ?
Solidity 实现的合约中,函数操作都是原子操作,旷工本地执行,取得共识后发布到区块链上. 实际发布到区块链上的不存在并发,全节点同步状态到本地. Solidity 中有三种方式进行转账,addr ...
- [PHP] 浅谈 Laravel Authorization 的 gates 与 policies
首先要区分 Authentication 与 Authorization,认证和授权,粗细有别. 授权(Authorization) 有两种主要方式,Gates 和 Policies. Gates 和 ...
- WPF 优化 EnsureHandle 启动性能
本文将记录一个在 WPF 应用程序启动过程中的性能优化点.如果一个窗口需要设置 WindowStyle 属性,那么在窗口 EnsureHandle 之前,设置 WindowStyle 属性将会比在 E ...
- VisualStudio 在 DebuggerDisplay 的属性更改业务逻辑将会让调试和非调试下逻辑不同
本文记录我写的逗比代码,我在 DebuggerDisplay 对应的属性的 get 方法上,在这个方法里面修改了业务逻辑,如修改界面元素,此时我在 VisualStudio 断点调试下和非断点调试下的 ...
- c++图像处理程序编译成.so动态链接库供Java调用(包含jni文件与引用第三方动态链接库opencv)
一.linux编译so文件需要准备的环境 1.安装JDK(注意:不能安装openjdk,因为openjdk没有include目录,编译时需要用到include目录的头文件) 2.安装gcc和g++ ...
- 让.NET 8 支持 Windows Vista RTM
众所周知,从 Windows 的每次更新又会新增大量 API,这使得兼容不同版本的 Windows 需要花费很大精力.导致现在大量开源项目已经不再兼容一些早期的 Windows 版本,比如 .NET ...
- SQL Server实战五:存储过程与触发器
本文介绍基于Microsoft SQL Server软件,实现数据库存储过程与触发器的创建.执行.修改与删除等操作. 目录 1 交互式创建并执行--存储过程一 2 交互式创建并执行--存储过程二 ...