使用AWS Glue进行 ETL 工作
数据湖
数据湖的产生是为了存储各种各样原始数据的大型仓库。这些数据根据需求,进行存取、处理、分析等。对于存储部分来说,开源版本常见的就是 hdfs。而各大云厂商也提供了各自的存储服务,如 Amazon S3,Azure Blob 等。
而由于数据湖中存储的数据全部为原始数据,一般需要对数据做ETL(Extract-Transform-Load)。对于大型数据集,常用的框架是 Spark、pyspark。在数据做完 ETL 后,再次将清洗后的数据存储到存储系统中(如hdfs、s3)。基于这部分清洗后的数据,数据分析师或是机器学习工程师等,可可以基于这些数据进行数据分析或是训练模型。在这些过程中,还有非常重要的一点是:如何对数据进行元数据管理?
在 AWS 中,Glue 服务不仅提供了 ETL 服务,还提供的元数据的管理。下面我们会使用 S3+Glue +EMR 来展示一个数据湖+ETL+数据分析的一个简单过程。
准备数据
此次使用的是GDELT数据,地址为:
https://registry.opendata.aws/gdelt/
此数据集中,每个文件名均显示了此文件的日期。作为原始数据,我们首先将2015年的数据放在一个year=2015 的s3目录下:
aws s3 cp s3://xxx/data/20151231.export.csv s3://xxxx/gdelt/year=2015/20151231.export.csv
使用Glue爬取数据定义
通过glue 创建一个爬网程序,爬取此文件中的数据格式,指定的数据源路径为s3://xxxx/gdelt/ 。

此部分功能及具体介绍可参考aws 官方文档:
https://docs.aws.amazon.com/zh_cn/glue/latest/dg/console-crawlers.html
爬网程序结束后,在Glue 的数据目录中,即可看到新创建的 gdelt 表:

原数据为csv格式,由于没有header,所以列名分别为col0、col1…、col57。其中由于s3下的目录结构为year=2015,所以爬网程序自动将year 识别为分区列。
至此,这部分原数据的元数据即保存在了Glue。在做ETL 之前,我们可以使用AWS EMR 先验证一下它对元数据的管理。
AWS EMR
AWS EMR 是 AWS 提供的大数据集群,可以一键启动带Hive、HBase、Presto、Spark 等常用框架的集群。
启动AWS EMR,勾选 Hive、Spark,并使用Glue作为它们表的元数据。EMR 启动后,登录到主节点,启动Hive:
> show tables;
gdelt
Time taken: 0.154 seconds, Fetched: 1 row(s)
可以看到在 hive 中已经可以看到此表,执行查询:
> select * from gdelt where year=2015 limit 3; OK 498318487 20060102 200601 2006 2006.0055 CVL COMMUNITY CVL 1 53 53 5 1 3.8 3 1 3 -2.42718446601942 1 United States US US 38.0 -97.0 US 0 NULL NULL 1 United States US US 38.0 -97.0 US 20151231 http://www.inlander.com/spokane/after-dolezal/Content?oid=2646896 2015 498318488 20060102 200601 2006 2006.0055 CVL COMMUNITY CVL USA UNITED STATES USA 1 51 51 5 1 3.4 3 1 3 -2.42718446601942 1 United States US US 38.0 -97.0 US 1 United States US US 38.0 -97.0 US 1 United States US US 38.0 -97.0 US 20151231 http://www.inlander.com/spokane/after-dolezal/Content?oid=2646896 2015 498318489 20060102 200601 2006 2006.0055 CVL COMMUNITY CVL USA UNITED STATES USA 1 53 53 5 1 3.8 3 1 3 -2.42718446601942 1 United States US US 38.0 -97.0 US 1 United States US US 38.0 -97.0 US 1 United States US US 38.0 -97.0 US 20151231 http://www.inlander.com/spokane/after-dolezal/Content?oid=2646896 2015
可以看到原始数据的列非常多,假设我们所需要的仅有4列:事件ID、国家代码、日期、以及网址,并基于这些数据做分析。那我们下一步就是做ETL。
GLUE ETL
Glue 服务也提供了 ETL 的工具,可以编写基于spark 或是 python 的脚本,提交给 glue etl 执行。在这个例子中,我们会抽取col0、col52、col56、col57、以及year这些列,并给它们重命名。然后从中抽取仅包含“UK”的记录,最终以date=current_day 的格式写入到最终s3 目录,存储格式为parquet。可以通过 python 或是 scala 语言调用 GLUE 编程接口,在本文中使用的是 scala:
import com.amazonaws.services.glue.ChoiceOption
import com.amazonaws.services.glue.GlueContext
import com.amazonaws.services.glue.DynamicFrame
import com.amazonaws.services.glue.MappingSpec
import com.amazonaws.services.glue.ResolveSpec
import com.amazonaws.services.glue.errors.CallSite
import com.amazonaws.services.glue.util.GlueArgParser
import com.amazonaws.services.glue.util.Job
import com.amazonaws.services.glue.util.JsonOptions
import org.apache.spark.SparkContext
import scala.collection.JavaConverters._
import java.text.SimpleDateFormat
import java.util.Date object Gdelt_etl {
def main(sysArgs: Array[String]) { val sc: SparkContext = new SparkContext()
val glueContext: GlueContext = new GlueContext(sc)
val spark = glueContext.getSparkSession // @params: [JOB_NAME]
val args = GlueArgParser.getResolvedOptions(sysArgs, Seq("JOB_NAME").toArray)
Job.init(args("JOB_NAME"), glueContext, args.asJava) // db and table
val dbName = "default"
val tblName = "gdelt" // s3 location for output
val format = new SimpleDateFormat("yyyy-MM-dd")
val curdate = format.format(new Date())
val outputDir = "s3://xxx-xxx-xxx/cleaned-gdelt/cur_date=" + curdate + "/" // Read data into DynamicFrame
val raw_data = glueContext.getCatalogSource(database=dbName, tableName=tblName).getDynamicFrame() // Re-Mapping Data
val cleanedDyF = raw_data.applyMapping(Seq(("col0", "long", "EventID", "string"), ("col52", "string", "CountryCode", "string"), ("col56", "long", "Date", "String"), ("col57", "string", "url", "string"), ("year", "string", "year", "string"))) // Spark SQL on a Spark DataFrame
val cleanedDF = cleanedDyF.toDF()
cleanedDF.createOrReplaceTempView("gdlttable") // Get Only UK data
val only_uk_sqlDF = spark.sql("select * from gdlttable where CountryCode = 'UK'") val cleanedSQLDyF = DynamicFrame(only_uk_sqlDF, glueContext).withName("only_uk_sqlDF") // Write it out in Parquet
glueContext.getSinkWithFormat(connectionType = "s3", options = JsonOptions(Map("path" -> outputDir)), format = "parquet").writeDynamicFrame(cleanedSQLDyF) Job.commit()
}
}
将此脚本保存为gdelt.scala 文件,并提交给 GLUE ETL作业执行。等待执行完毕后,我们可以在s3看到生成了输出文件:
> aws s3 ls s3://xxxx-xxx-xxx/cleaned-gdelt/ date=2020-04-12/
part-00000-d25201b8-2d9c-49a0-95c8-f5e8cbb52b5b-c000.snappy.parquet
然后我们再对此/cleaned-gdelt/目录执行一个新的 GLUE 网爬程序:
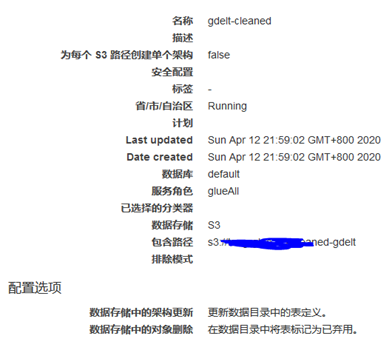
执行完成后,可以在GLUE 看到生成了新表,此表结构为:
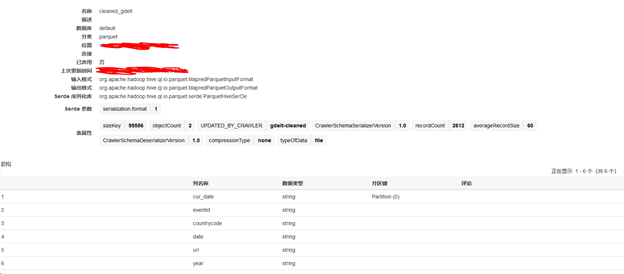
可以看到输入输出格式均为parquet,分区键为cur_date,且仅包含了我们所需的列。
再次进入到 EMR Hive 中,可以看到新表已出现:
hive> describe cleaned_gdelt;
OK
eventid string
countrycode string
date string
url string
year string
date string # Partition Information
# col_name data_type comment
cur_date string
查询此表:
hive> select * from cleaned_gdelt limit 10;
OK
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
498318821 UK 20151231 http://wmpoweruser.com/microsoft-denies-lumia-950-xl-withdrawn-due-issues-says-stock-due-strong-demand/ 2015
498319466 UK 20151231 http://www.princegeorgecitizen.com/news/police-say-woman-man-mauled-by-2-dogs-in-home-in-british-columbia-1.2142296 2015
498319777 UK 20151231 http://www.catchnews.com/life-society-news/happy-women-do-not-live-any-longer-than-sad-women-1451420391.html 2015
498319915 UK 20151231 http://www.nationalinterest.org/feature/the-perils-eu-army-14770 2015
…
Time taken: 0.394 seconds, Fetched: 10 row(s)
可以看到出现的结果均的 CountryCode 均为 UK,达到我们的目标。
自动化
下面是将 GLUE 网爬 + ETL 进行自动化。在GLUE ETL 的工作流程中,创建一个工作流,创建完后如下所示:

如图所示,此工作流的过程为:
- 每晚11点40开始触发工作流
- 触发 gdelt 的网爬作业,爬取原始数据的元数据
- 触发gdelt的ETL作业
- 触发gdelt-cleaned 网爬程序,爬取清洗后的数据的元数据
下面我们添加一个新文件到原始文件目录,此新数据为 year=2016 的数据:
aws s3 cp s3://xxx-xxxx/data/20160101.export.csv s3://xxx-xxx-xxx/gdelt/year=2016/20160101.export.csv
然后执行此工作流。
期间我们可以看到ETL job 在raw_crawler_done 之后,被正常触发:

作业完成后,在Hive 中即可查询到 2016 年的数据:
select * from cleaned_gdelt where year=2016 limit 10;
OK
498554334 UK 20160101 http://medicinehatnews.com/news/national-news/2015/12/31/support-overwhelming-for-bc-couple-mauled-by-dogs-on-christmas-day/ 2016
498554336 UK 20160101 http://medicinehatnews.com/news/national-news/2015/12/31/support-overwhelming-for-bc-couple-mauled-by-dogs-on-christmas-day/ 2016
…
使用AWS Glue进行 ETL 工作的更多相关文章
- 在AWS Glue中使用Apache Hudi
1. Glue与Hudi简介 AWS Glue AWS Glue是Amazon Web Services(AWS)云平台推出的一款无服务器(Serverless)的大数据分析服务.对于不了解该产品的读 ...
- 简化ETL工作,编写一个Canal胶水层
前提 这是一篇憋了很久的文章,一直想写,却又一直忘记了写.整篇文章可能会有点流水账,相对详细地介绍怎么写一个小型的"框架".这个精悍的胶水层已经在生产环境服役超过半年,这里尝试把耦 ...
- 聊聊Lambda架构
定义 在数据分析场景中,我们可能会遇到这样的问题.例如,我们要做一个推荐系统,如果我们用批处理任务去做,一天或者一小时的推荐频次明显延迟太大.如果用流处理任务,虽然延迟的问题解决了,然而只用实时数据而 ...
- AWS产品目录
计算 Amazon EC2:弹性虚拟机 AWS Batch:批处理计算 Amazon ECR:Docker容器管理 Amazon ECS:高度可扩展的快速容器管理服务 Amazon EKS:在AWS上 ...
- [AWS] 01 - What is Amazon EMR
[DE] ML on Big data: MLlib 关于 Amazon EMR 发布版本 利用 Amazon EMR 分析大数据 Amazon Athena 是一种交互式查询服务,让您能够轻松使用标 ...
- aws产品整理
计算 Amazon EC2:弹性虚拟机 AWS Batch:批处理计算 Amazon ECR:Docker容器管理 Amazon ECS:高度可扩展的快速容器管理服务 Amazon EKS:在AWS上 ...
- 官宣!AWS Athena正式可查询Apache Hudi数据集
1. 引入 Apache Hudi是一个开源的增量数据处理框架,提供了行级insert.update.upsert.delete的细粒度处理能力(Upsert表示如果数据集中存在记录就更新:否则插入) ...
- 划重点!AWS的湖仓一体使用哪种数据湖格式进行衔接?
此前Apache Hudi社区一直有小伙伴询问能否使用Amazon Redshift查询Hudi表,现在它终于来了. 现在您可以使用Amazon Redshift查询Amazon S3 数据湖中Apa ...
- 使用Apache Hudi + Amazon S3 + Amazon EMR + AWS DMS构建数据湖
1. 引入 数据湖使组织能够在更短的时间内利用多个源的数据,而不同角色用户可以以不同的方式协作和分析数据,从而实现更好.更快的决策.Amazon Simple Storage Service(amaz ...
- ETL之增量抽取方式
1.触发器方式 触发器方式是普遍采取的一种增量抽取机制.该方式是根据抽取要求,在要被抽取的源表上建立插入.修改.删除3个触发器,每当源表中的数据发生变化,就被相应的触发器将变化的数据写入一个增量日志表 ...
随机推荐
- 他又来了,.net开源智能家居之小米米家的c#原生sdk【MiHome.Net】1.0.0发布,快来打造你的私人智能家居吧
背景介绍 hi 大家好,我是三合,作为一个非著名懒人,智能家居简直刚需,在上一篇文章他来了他来了,.net开源智能家居之苹果HomeKit的c#原生sdk[Homekit.Net]1.0.0发布,快来 ...
- Solution Set - SAM
讲解一些 SAM 经典的应用.可以结合 字 符 串 全 家 桶 中 SAM 的部分食用. 洛谷P2408 求不同子串个数.在 SAM 中,所有结点是一个等价类,包含的字符串互不相同.结点 \(u\) ...
- JSON字符串数据转换指定实体对象数据
一.引入需要的maven依赖 <dependency> <groupId>org.projectlombok</groupId> <artifactId> ...
- 开发环境需要同时安装2个nodejs版本
由于同时有vue2和vue3的项目开发情况,vue2项目的nodejs版本是12,vue3项目在node12版本下运行不了,要求最低14版本,因此要用nvm同时安装和控制2个版本. 安装步骤: 1.卸 ...
- 远程控制软件 TeamViewer 的局限性和替代方案
TeamViewer 公司创建于2005年,总部位于德国,客户遍及全球,其中企业用户居多,其各方面性能都很不错,但价格却非常贵.针对个人用户,TeamViewer 提供免费版软件,但时不时会提示&qu ...
- C语言:生成单词列表----使用单链表实现
解决之前用结构体数组导致内存过剩问题,使用动态分配内存优化单词列表. txt文本内容不允许出现其他字符形式,这个仅限于判断在txt网页文件已经删除了超链接等,文本里面只允许出现单词才能进行判断和进行单 ...
- 13-flask博客项目之restful api详解1-概念
一 传统的开发模式 前后端分类概念 前端只需要独立编写客户端代码,后端也只需要独立编写服务端代码提供数据接口即可前端通过AJAX请求来访问后端的数据接口,将Model展示到View中即可 前后端开发者 ...
- 【知识点】深入浅出STL标准模板库
前几天谈论了许多关于数论和数据结构的东西,这些内容可能对初学者而言比较晦涩难懂(毕竟是属于初高等算法/数据结构的范畴了).今天打算来讲一些简单的内容 - STL 标准模板库. STL 标准模板库 C+ ...
- Android OpenMAX(八)如何学习OMXNodeInstance
前面一篇文章中我们看到media.codec service创建OMX组件后会把组件传递给一个OMXNodeInstance对象,并且把OMXNodeInstance对象返回到Framework层,F ...
- 安装、学习protobuf
Protobuf是什么? 类似于json的一种数据格式,独立于语言,而且是二进制方式,所以比json更快,而且还可以直接存储一些图.树 序列化和反序列化 持久化(存到磁盘硬盘)领域中,数据存到磁盘叫序 ...