ROC,AUC,PR,AP介绍及python绘制
这里介绍一下如题所述的四个概念以及相应的使用python绘制曲线:
参考博客:http://kubicode.me/2016/09/19/Machine%20Learning/AUC-Calculation-by-Python/?utm_source=tuicool&utm_medium=referral
一般我们在评判一个分类模型的好坏时,一般使用MAP值来衡量,MAP越接近1,模型效果越好;


更详细的可参考:http://www.cnblogs.com/pinard/p/5993450.html
准确率pr就是找得对,召回率rc就是找得全。
大概就是你问问一个模型,这堆东西是不是某个类的时候,准确率就是 它说是,这东西就确实是的概率吧,召回率就是, 它说是,但它漏说了(1-召回率)这么多。
(这里的P=FN+TP;N=TN+FP;而这里recall=tp rate;上述链接里的特异性其实就是fp rate)
AUC和AP分别是ROC和PR曲线下面积,map就是每个类的ap的平均值;python代码(IDE是jupyter notebook):
#绘制二分类ROC曲线
import pylab as pl
%matplotlib inline
from math import log,exp,sqrt evaluate_result = "D:/python_sth/1.txt"
db = []
pos , neg = 0 , 0
with open(evaluate_result , 'r') as fs:
for line in fs:
nonclk , clk , score = line.strip().split('\t')
nonclk = int(nonclk)
clk = int(clk)
score = float(score)
db.append([score , nonclk , clk])
pos += clk
neg += nonclk db = sorted(db , key = lambda x:x[0] , reverse = True) #降序 #计算ROC坐标点
xy_arr = []
tp , fp = 0. , 0.
for i in range(len(db)):
tp += db[i][2]
fp += db[i][1]
xy_arr.append([tp/neg , fp/pos]) #计算曲线下面积即AUC
auc = 0.
prev_x = 0
for x ,y in xy_arr:
if x != prev_x:
auc += (x - prev_x) * y
prev_x = x
print "the auc is %s."%auc
x = [_v[0] for _v in xy_arr]
y = [_v[1] for _v in xy_arr]
pl.title("ROC curve of %s (AUC = %.4f)" % ('svm' , auc))
pl.ylabel("False Positive Rate")
pl.plot(x ,y)
pl.show()
结果:(注意:ROC曲线中纵坐标是TP,横坐标是FP,下面的图有误!)
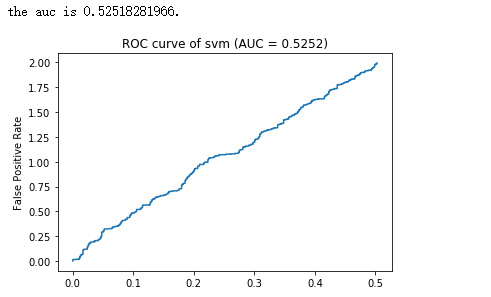
这里的.txt文件格式如:http://kubicode.me/img/AUC-Calculation-by-Python/evaluate_result.txt
形式为:

PS:该txt文件表示的意思是,比如对于第一行就是说:有一个样本得分为0.86...,并被预测为负样本;倒数第一行就是说,这么多测试样本中,有一个样本得分为0.45...,并被预测为正样本;
注意:绘制ROC和PR曲线时都是设定不同的阈值来获得对应的坐标,从而画出曲线
代码中:
nonclick:未点击的数据,可以看做负样本的数量clk:点击的数量,可以看做正样本的数量score:预测的分数,以该分数为group进行正负样本的预统计可以减少AUC的计算量- 代码中首先使用
db = sorted(db , key = lambda x:x[0] , reverse = True) 进行降序排序,然后将每一个从小到大的得分值作为阈值,每次得到一个fpr和tpr(因为最后得分大于阈值,就认为它是正样本,所以若.txt中得分为某一个阈值时nonclk为非0的数,而clk是0,则认为nonclk的值大小的样本是fp样本),最后画出曲线;
对于PR曲线也一样,只不过横坐标换成 ,纵坐标换成
,纵坐标换成 ,AP是其曲线下面积;
,AP是其曲线下面积;
上面的python代码针对二分类模型,但针对多分类模型时一样,即对于每个类都将其看做正样本,其他类看成负样本来画曲线,这样有多少类就画多少条相应的曲线,MAp值即为各类ap值的平均值;
PR曲线的绘制:
这里我们用一张图片作为例子,多张图片道理一样。假设一张图片有N个需要检测的目标,分别是object1,object2,object3共分为三类,使用检测器得到了M个Bounding Box(BB),每个BB里包含BB所在的位置以及object1,object2,object3对应的分数confidence。
我把计算目标检测评价指标归为一下几步:
1,对每一类i进行如下操作:
对M个BB中每一个BB,计算其与N个GroundTruth(GT)的IoU值,且取其中的最大值MaxIoU。设定一个阈值thresh,一般设置thresh为0.5。当MaxIoU < thresh的时候,记录其类别i的分数confidencei以及fpi = 1,当MaxIoU>=thresh分为以下俩种情况:
当MaxIoU对应的GT类别为i的时候,记录其类别i的分数以及tpi = 1。
当MaxIoU对应的GT类别不为i的时候,记录其类别i的分数以及fpi = 1。
2,由步骤1我们可以得到3M个分数与tp/fp的元祖,形如(confidencei,tp或者fp),对这3M个元祖按照confidence进行排序(从大到小)。
3,按照顺序1,2,3,4。。。M截取,计算每次截取所获得的recall和precision
recall = tp/N
precision = tp/tp+fp
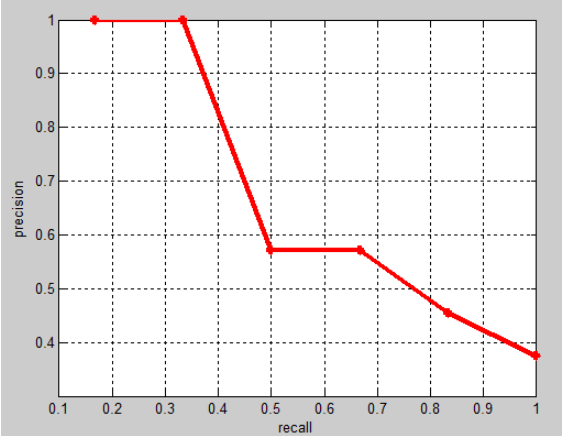
这样得到M个recall和precision点,便画出PR曲线了~
计算AP值:
由上面得到了PR曲线,即得到了n个(P,R)坐标点,利用这些坐标点我们便可以计算出AP(average precision):
方法一:11点法,此处参考的是PASCAL VOC CHALLENGE的计算方法。首先设定一组阈值,[0, 0.1, 0.2, …, 1]。然后对于recall大于每一个阈值(比如recall>0.3),我们都会得到一个对应的最大precision。这样,我们就计算出了11个precision。AP即为这11个precision的平均值。这种方法英文叫做11-point interpolated average precision。;
方法二:当然PASCAL VOC CHALLENGE自2010年后就换了另一种计算方法。新的计算方法假设这N个样本中有M个正例,那么我们会得到M个recall值(1/M, 2/M, …, M/M),对于每个recall值r,我们可以计算出对应(r’ > r)的最大precision,然后对这M个precision值取平均即得到最后的AP值。
下面给出个例子方便更加形象的理解:
假设从测试集中共检测出20个例子,而测试集中共有6个正例,则PR表如下:

相应的Precision-Recall曲线(这条曲线是单调递减的)如下:
faster rcnn中计算map的代码:https://github.com/rbgirshick/py-faster-rcnn/blob/master/lib/datasets/voc_eval.py 该代码使用的是方法二。
我看网上关于如何使用该代码并没有做出解释,我这里用voc中的几张图片计算了一下map(自己算法的测试结果,比如说对voc中的cat类,就新建一个cat.txt,其中存储“图片名 矩形框坐标”格式的信息),具体文件在链接:https://pan.baidu.com/s/1336g7ccc4gZ2EKNu9PNndQ 提取码:57yd 中,大家有需要的可以按照这个里面的格式来操作该代码计算map。
AUC和MAP之间的联系:
AUC主要考察模型对正样本以及负样本的覆盖能力(即“找的全”),而MAP主要考察模型对正样本的覆盖能力以及识别能力(即对正样本的“找的全”和“找的对”)
ROC,AUC,PR,AP介绍及python绘制的更多相关文章
- Precision/Recall、ROC/AUC、AP/MAP等概念区分
1. Precision和Recall Precision,准确率/查准率.Recall,召回率/查全率.这两个指标分别以两个角度衡量分类系统的准确率. 例如,有一个池塘,里面共有1000条鱼,含10 ...
- Python绘制3D图形
来自:https://www.jb51.net/article/139349.htm 3D图形在数据分析.数据建模.图形和图像处理等领域中都有着广泛的应用,下面将给大家介绍一下如何使用python进行 ...
- 吃瓜的正确姿势,Python绘制罗志祥词云图
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 这篇文章中向大家介绍了Python绘制词云的方法,不难看出绘制词云可以说是一 ...
- 模型评估【PR|ROC|AUC】
这里主要讲的是对分类模型的评估. 1.准确率(Accuracy) 准确率的定义是:[分类正确的样本] / [总样本个数],其中分类正确的样本是不分正负样本的 优点:简单粗暴 缺点:当正负样本分布不均衡 ...
- 一文让你彻底理解准确率,精准率,召回率,真正率,假正率,ROC/AUC
参考资料:https://zhuanlan.zhihu.com/p/46714763 ROC/AUC作为机器学习的评估指标非常重要,也是面试中经常出现的问题(80%都会问到).其实,理解它并不是非常难 ...
- 机器学习之类别不平衡问题 (2) —— ROC和PR曲线
机器学习之类别不平衡问题 (1) -- 各种评估指标 机器学习之类别不平衡问题 (2) -- ROC和PR曲线 完整代码 ROC曲线和PR(Precision - Recall)曲线皆为类别不平衡问题 ...
- ROC AUC
1.什么是性能度量? 我们都知道机器学习要建模,但是对于模型性能的好坏(即模型的泛化能力),我们并不知道是怎样的,很可能这个模型就是一个差的模型,泛化能力弱,对测试集不能很好的预测或分类.那么如何知道 ...
- 使用python绘制根轨迹图
最近在学自动控制原理,发现根轨迹这一张全是绘图的,然而书上教的全是使用matlab进行计算机辅助绘图.但国内对于使用python进行这种绘图的资料基本没有,后来发现python-control包已经将 ...
- 用Python绘制一套“会跳舞”的动态图形给你看看
在读技术博客的过程中,我们会发现那些能够把知识.成果讲透的博主很多都会做动态图表.他们的图是怎么做的?难度大吗?这篇文章就介绍了 Python 中一种简单的动态图表制作方法. 看这优美的舞姿 很多人学 ...
随机推荐
- 如何安装/卸载workflow manager 1.0
安装 1. 配置文件: <Workflow> <!--http://msdn.microsoft.com/en-us/library/windowsazure/jj193269(v= ...
- 用DotNetOpenAuth实现基于OAuth 2.0的web api授权 (一)Getting Start
1. 下载 源码下载 2. build solution,创建虚拟目录: 右健MyContatacts/MyPromo项目,选择Properties,点击左边的Web,点击 Create Virtua ...
- 全面解析Java类加载器
深入理解和探究Java类加载机制---- 1.java.lang.ClassLoader类介绍 java.lang.ClassLoader类的基本职责就是根据一个指定的类的名称,找到或者生成其对应的字 ...
- POJ 1459 Power Network / HIT 1228 Power Network / UVAlive 2760 Power Network / ZOJ 1734 Power Network / FZU 1161 (网络流,最大流)
POJ 1459 Power Network / HIT 1228 Power Network / UVAlive 2760 Power Network / ZOJ 1734 Power Networ ...
- 【洛谷P1248】加工生产调度
题目大意:某工厂收到了n个产品的订单,这n个产品分别在A.B两个车间加工,并且必须先在A车间加工后才可以到B车间加工.某个产品i在A.B两车间加工的时间分别为Ai.Bi.怎样安排这n个产品的加工顺序, ...
- 快速幂&快速乘法
尽管快速幂与快速乘法好像扯不上什么关系,但是东西不是很多,就一起整理到这里吧 快速幂思想就是将ax看作x个a相乘,用now记录当前答案,然后将指数每次除以2,然后将当前答案平方,如果x的2进制最后一位 ...
- BellmanFord 最短路
时间复杂度:O(VE) 最多循环V次,每次循环对每一条边(共E条边)判断是否可以进行松弛操作 最多V次:一个点的最短路,最多包含V-1个点(不包含该点), 如d1->d2->d3-> ...
- Gradle 从svn 中检出的父项目后处理配置【我】
前提: 一个用gradle配置的 类似maven的聚合项目的项目,然后它在svn上就是一个父工程的目录. 检出方式: 在eclipse中,直接用svn资源库检出 父项目 的目录. 然后,在父项目下面的 ...
- Hadoop基础-网络拓扑机架感知及其实现
Hadoop基础-网络拓扑机架感知及其实现 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.网络拓扑结构 在本地网络中,两个节点被称为“彼此近邻”是什么意思?在海量数据处理中,其 ...
- 启动eclipse弹出提示Version 1.7.0_79 of the JVM is not suitable for this product. Version: 1.8 or greater is required怎样解决
启动eclipse时弹出如下弹出框: 解决办法: 在eclipse安装目录下找到eclipse.ini文件,并在 -vmargs-Dosgi.requiredJavaVersion=1.8 前面加上 ...