基于用户的协同过滤算法个性化推荐系统的设计与实现+springboot+vue源码
协同过滤(Collaborative Filtering, CF)是推荐系统中最经典的算法之一,其核心思想是通过用户的历史行为数据(如评分、点击、购买等)发现用户或物品的相似性,并基于这种相似性进行推荐。协同过滤分为两大类:基于用户的协同过滤和基于物品的协同过滤。
本文将介绍 基于用户的协同过滤 原理, 并设计一个简单的商品推荐系统。
算法的步骤
1. 获取所有用户行为数据,构建用户-物品评分矩阵。
2. 目标用户与其它用户的相似度计算: 将用户对商品的评分视为向量,计算余弦相似度。
3. 选取与目标用户相似度最高的 k 个用户作为邻居 。
4. 通过邻居用户的评分进行加权平均预测(权重为用户相似度)。
5. 将预测评分按降序排序,选择评分最高的N个物品作为推荐结果。
如果你还是不懂,我这里举一个通俗易懂的实例:
假设我们有3个用户(小明、小红、小张)和4个商品(手机、电脑、平板、耳机)。
小明给手机和电脑评分分别是4分和5分,小红给手机和平板评分是5分和3分,小张给电脑和耳机评分是4分和2分。
如下图描述:
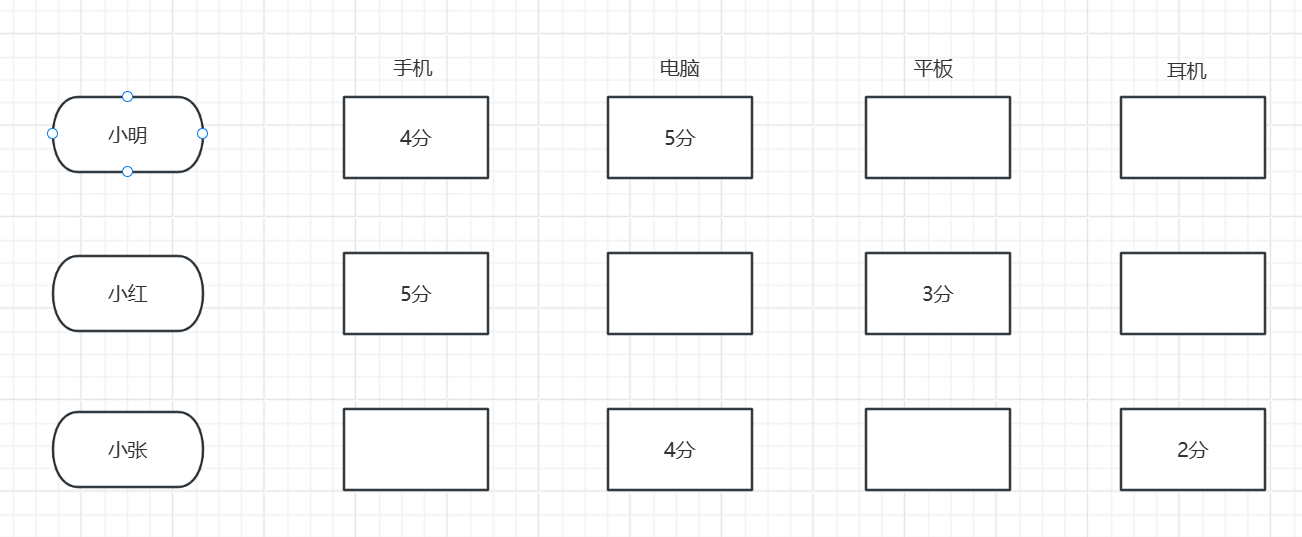
现在要为小明推荐商品,系统执行的步骤如下:
1. 构建用户-物品评分矩阵,每行代表一个用户,每列代表一个商品;
2. 计算小明与其他用户的余弦相似度,比如与小红的相似度是0.8(因为都给手机较高分),与小张的相似度是0.6;
3. 对于小明未评分的商品(平板和耳机),通过相似用户的评分进行加权预测,如平板的预测分数=(0.8×3)/(0.8)=3分,耳机的预测分数=(0.6×2)/(0.6)=2分;
4. 最后按预测分数降序排序,推荐平板给小明。
代码实现
数据库表准备
首先我们需要准备用户的行为数据表:
CREATE TABLE `user_behaviors` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '行为ID,自增主键',
`user_id` bigint NOT NULL COMMENT '用户ID',
`item_id` bigint NOT NULL COMMENT '物品ID',
`rating` decimal(3,1) DEFAULT NULL COMMENT '评分(1-5分)',
`behavior_type` varchar(20) NOT NULL COMMENT '行为类型(VIEW-浏览,LIKE-喜欢,PURCHASE-购买)',
`timestamp` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '行为发生时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB COMMENT='用户行为记录表';
之所以这里有评分字段,是因为后续要扩展 基于协同过滤算法的用户评分推荐系统。
当然这里还要有用户表和商品表:
CREATE TABLE `items` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '物品ID,自增主键',
`name` varchar(200) NOT NULL COMMENT '物品名称',
`description` text COMMENT '物品描述',
`category` varchar(50) DEFAULT NULL COMMENT '物品类别',
`price` decimal(10,2) DEFAULT NULL COMMENT '物品价格',
PRIMARY KEY (`id`)
) ENGINE=InnoDB COMMENT='商品表';
CREATE TABLE `users` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '用户ID,自增主键',
`username` varchar(50) NOT NULL COMMENT '用户名',
`email` varchar(100) NOT NULL COMMENT '用户邮箱',
`password` varchar(100) NOT NULL COMMENT '用户密码',
PRIMARY KEY (`id`)
) ENGINE=InnoDB COMMENT='用户表';
表建立好之后,我们需要写好基本的用户登录,商品列表,商品详情等基础接口,然后保证有丰富的行为数据落库,这样推荐系统才能发挥作用。
这些基本的接口我就不讲了,主要讲解一下关键的算法代码。
完整系统源码我已经整理清楚:
gitcode巅抗目/hadluo2/springboot_vue.git
用户评分矩阵的构建
需要借助 是 Apache Commons Math 库中的一个类,用于表示二维实数矩阵,并提供矩阵运算功能。Array2DRowRealMatrix算法工具, Array2DRowRealMatrix
maven依赖如下:
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-math3</artifactId>
<version>3.6.1</version>
</dependency>
构建评分矩阵的代码:
// 获取所有用户的行为数据,用于构建用户-物品评分矩阵
List<UserBehavior> allBehaviors = userBehaviorRepository.selectList(null); if(CollectionUtils.isEmpty(allBehaviors)) {
return Collections.emptyList();
} // 构建用户和物品的索引映射,方便后续构建评分矩阵
Map<Long, Integer> userIndex = new HashMap<>();
Map<Long, Integer> itemIndex = new HashMap<>();
// 提取用户id
List<Long> users = allBehaviors.stream().map(UserBehavior::getUserId).distinct().collect(Collectors.toList());
// 提取物品id
List<Long> items = allBehaviors.stream().map(UserBehavior::getItemId).distinct().collect(Collectors.toList());
for (int i = 0; i < users.size(); i++) {
userIndex.put(users.get(i), i);
}
for (int i = 0; i < items.size(); i++) {
itemIndex.put(items.get(i), i);
}
// 初始化评分矩阵,行表示用户,列表示物品 一个 users.size() x items.size() 大小的矩阵
RealMatrix ratingMatrix = new Array2DRowRealMatrix(users.size(), items.size());
// 根据用户行为数据填充评分矩阵
for (UserBehavior behavior : allBehaviors) {
if (behavior.getRating() != null) {
int uIndex = userIndex.get(behavior.getUserId());
int iIndex = itemIndex.get(behavior.getItemId());
// 设置 矩阵的 行,列 值 为 评分
ratingMatrix.setEntry(uIndex, iIndex, behavior.getRating());
}
}
余弦相似度计算
/**
* 计算两个向量的余弦相似度
* 余弦相似度用于衡量两个用户的评分模式的相似程度
* @param vector1 第一个用户的评分向量
* @param vector2 第二个用户的评分向量
* @return 相似度值,范围[-1,1],值越大表示越相似
*/
private double calculateCosineSimilarity(double[] vector1, double[] vector2) {
double dotProduct = 0.0;
double norm1 = 0.0;
double norm2 = 0.0; for (int i = 0; i < vector1.length; i++) {
dotProduct += vector1[i] * vector2[i];
norm1 += vector1[i] * vector1[i];
norm2 += vector2[i] * vector2[i];
} if (norm1 == 0 || norm2 == 0) return 0; return dotProduct / (Math.sqrt(norm1) * Math.sqrt(norm2));
}
根据余弦相似度计算取5个相似的用户作为邻居
用户uhgnoy// 计算目标用户与其他用户的相似度
int userIdx = userIndex.get(user.getId());
Map<Integer, Double> userSimilarities = new HashMap<>(); for (int i = 0; i < users.size(); i++) {
if (i != userIdx) {
// 计算 当前用户 与其他的每一个用户的评分向量的 余弦相似度
double similarity = calculateCosineSimilarity(ratingMatrix.getRow(userIdx), ratingMatrix.getRow(i));
userSimilarities.put(i, similarity);
}
} // 选择最相似的5个用户作为邻居用户
List<Integer> similarUsers = userSimilarities.entrySet().stream()
// 按相似度值降序排序
.sorted(Map.Entry.<Integer, Double>comparingByValue().reversed())
// 取前5个最相似用户
.limit(5)
// 提取用户索引
.map(Map.Entry::getKey)
.collect(Collectors.toList());
最后是计算加权平均,当中还需要进行 归一化处理, 来避免了因用户群体整体相似度偏高/偏低导致的预测偏差,使得推荐结果更贴近用户的真实偏好。
整体代码较长,我就不贴了。
最后是controller接口提供API
/**
* 推荐系统API控制器
* 提供个性化推荐、热门物品推荐等功能
*/
@RestController
@RequestMapping("/recommendations")
public class RecommendationController { @Autowired
private RecommendationService recommendationService; @Autowired
private UserRepository userRepository; @Autowired
private ItemRepository itemRepository; @Autowired
private UserBehaviorRepository userBehaviorRepository; /**
* 获取用户个性化推荐列表
* @return 推荐的物品列表
*/
@PostMapping("/user")
public V getRecommendationsForUser(@RequestBody UserBehavior item) {
User user = userRepository.selectById(item.getUserId());
if (user == null) {
return V.fail("必须登录");
}
List<Item> recommendations = recommendationService.recommendItemsForUser(user, 10);
return V.success(recommendations);
} /**
* 记录用户行为数据
* @param behavior 用户行为信息(如:浏览、评分、收藏等)
* @return 操作结果
*/
@PostMapping("/behavior")
public V recordUserBehavior(@RequestBody UserBehavior behavior) {
// 验证用户ID
User user = userRepository.selectById(behavior.getUserId());
if (user == null) {
return V.fail("用户不存在");
} // 验证物品ID
Item item = itemRepository.selectById(behavior.getItemId());
if (item == null) {
return V.fail("物品不存在");
} // 验证行为类型
if (behavior.getBehaviorType() == null ||
(!behavior.getBehaviorType().equals("VIEW") &&
!behavior.getBehaviorType().equals("LIKE") &&
!behavior.getBehaviorType().equals("PURCHASE"))) {
return V.fail("无效的行为类型");
} // 验证评分范围(如果提供了评分)
if (behavior.getRating() != null && (behavior.getRating() < 1 || behavior.getRating() > 5)) {
return V.fail("评分必须在1-5之间");
} // 设置关联实体和时间戳
behavior.setTimestamp(LocalDateTime.now());
// 检查是否存在相同的行为记录
LambdaQueryWrapper<UserBehavior> wrapper = new LambdaQueryWrapper<>();
wrapper.eq(UserBehavior::getUserId, behavior.getUserId())
.eq(UserBehavior::getItemId, behavior.getItemId())
.eq(UserBehavior::getBehaviorType, behavior.getBehaviorType()); UserBehavior existingBehavior = userBehaviorRepository.selectOne(wrapper); try {
if (existingBehavior != null) {
// 更新现有记录
behavior.setId(existingBehavior.getId());
userBehaviorRepository.updateById(behavior);
} else {
// 创建新记录
userBehaviorRepository.insert(behavior);
}
return V.success(behavior);
} catch (Exception e) {
return V.fail("保存用户行为失败:" + e.getMessage());
}
} /**
* 获取商品列表,支持分页查询
* @param page 页码,从1开始
* @param size 每页数量
* @return 分页的商品列表
*/
@GetMapping("/items")
public V getItems(
@RequestParam(defaultValue = "1") int page,
@RequestParam(defaultValue = "10") int size) {
Page<Item> pageRequest = new Page<>(page, size);
IPage<Item> items = itemRepository.selectPage(pageRequest, null);
return V.success(items);
} /**
* 商品详情
*/
@GetMapping("/item-details/{id}")
public V details(@PathVariable Long id) {
Item item = itemRepository.selectById(id);
return V.success(item);
}
}
基于用户的协同过滤算法个性化推荐系统的设计与实现+springboot+vue源码的更多相关文章
- Mahout实现基于用户的协同过滤算法
Mahout中对协同过滤算法进行了封装,看一个简单的基于用户的协同过滤算法. 基于用户:通过用户对物品的偏好程度来计算出用户的在喜好上的近邻,从而根据近邻的喜好推测出用户的喜好并推荐. 图片来源 程序 ...
- 案例:Spark基于用户的协同过滤算法
https://mp.weixin.qq.com/s?__biz=MzA3MDY0NTMxOQ==&mid=2247484291&idx=1&sn=4599b4e31c2190 ...
- 【推荐系统实战】:C++实现基于用户的协同过滤(UserCollaborativeFilter)
好早的时候就打算写这篇文章,可是还是參加阿里大数据竞赛的第一季三月份的时候实验就完毕了.硬生生是拖到了十一假期.自己也是醉了... 找工作不是非常顺利,希望写点东西回想一下知识.然后再攒点人品吧,仅仅 ...
- 基于用户的协同过滤的电影推荐算法(tensorflow)
数据集: https://grouplens.org/datasets/movielens/ ml-latest-small 协同过滤算法理论基础 https://blog.csdn.net/u012 ...
- Spark 基于物品的协同过滤算法实现
J由于 Spark MLlib 中协同过滤算法只提供了基于模型的协同过滤算法,在网上也没有找到有很好的实现,所以尝试自己实现基于物品的协同过滤算法(使用余弦相似度距离) 算法介绍 基于物品的协同过滤算 ...
- 推荐召回--基于用户的协同过滤UserCF
目录 1. 前言 2. 原理 3. 数据及相似度计算 4. 根据相似度计算结果 5. 相关问题 5.1 如何提炼用户日志数据? 5.2 用户相似度计算很耗时,有什么好的方法? 5.3 有哪些改进措施? ...
- 基于物品的协同过滤算法(ItemCF)
最近在学习使用阿里云的推荐引擎时,在使用的过程中用到很多推荐算法,所以就研究了一下,这里主要介绍一种推荐算法—基于物品的协同过滤算法.ItemCF算法不是根据物品内容的属性计算物品之间的相似度,而是通 ...
- 基于用户的协同过滤电影推荐user-CF python
协同过滤包括基于物品的协同过滤和基于用户的协同过滤,本文基于电影评分数据做基于用户的推荐 主要做三个部分:1.读取数据:2.构建用户与用户的相似度矩阵:3.进行推荐: 查看数据u.data 主要用到前 ...
- (数据挖掘-入门-3)基于用户的协同过滤之k近邻
主要内容: 1.k近邻 2.python实现 1.什么是k近邻(KNN) 在入门-1中,简单地实现了基于用户协同过滤的最近邻算法,所谓最近邻,就是找到距离最近或最相似的用户,将他的物品推荐出来. 而这 ...
- 基于用户的协同过滤(UserCF)
随机推荐
- babylon.js 学习笔记(1)
简单来说,babylon.js 是一个能跑在浏览器上的(3D)游戏渲染引擎,而且官方提供了一个友好在线交互学习平台Playground,其开源项目在github上star数截止2023.05.14高达 ...
- 将AtomicInteger对象作为方法的局部变量, 传递给其他线程, 读写操作是否是线程安全的?
目录 将AtomicInteger对象作为方法的局部变量, 传递给其他线程, 读写操作是否是线程安全的? 场景 代码 运行结果 总结 将AtomicInteger对象作为方法的局部变量, 传递给其他线 ...
- CAS 5.3.1系列之客户端对接(五)
CAS 5.3.1系列之客户端对接(五) 我们要接入客户端可以常用第三方的库cas-client-autoconfig-support来对接,比较快捷,迅速实现,或者可以用cas-client-sup ...
- PS一键图片智能添加噪点脚本 GrainLab for Photoshop安装与使用方法
GrainLab 是一款专为 Photoshop 设计的「一键智能噪点」脚本,可在 3 秒内为任意图像添加电影级颗粒.胶片杂讯或复古质感.脚本内置 8 组预设(胶片.数码.复古.粗颗粒等),支持自定义 ...
- Python函数实战之ATM与购物车系统
一.Python函数实战之ATM与购物车系统 项目需求: FUNC_MSG = { '0': '注销', '1': '登录', '2': '注册', '3': '查看余额', '4': '转账', ' ...
- ssh简单使用
本地生成ssh公钥与私钥 ssh-keygen -t ed25519 -f ~/.ssh/aliyun-ecs2 可以通过 open ./.ssh 打开 .ssh文件夹查看密钥情况 进入阿里云ecs界 ...
- 无人机RTMP推流直播及无人机GBR24视频流推流直播解决方案
LiveQing云端直播点播流媒体软件: 提供设备接入: RTMP推流服务.RTMP分发.HLS分发.HTTP-FLV分发: 云端录像.云端录像检索.云端录像点播.云端录像下载: RTMP转推.推流鉴 ...
- 好玩的 markdown 格式
markdown 欢迎来到好玩儿的Markdown游乐场! 本页面采用100%纯天然Markdown编写,不含任何防腐剂(可能含少量梗元素) 文字魔法秀 我是加粗的嚣张文字 我是倾斜的优雅文字 我是被 ...
- Oracle 11g 单实例下实例监听日志报错“WARNING: Subscription for node down event still pending”
Oracle 11g 单实例下实例监听日志[oracle@dbserver ~]$ more /u01/app/oracle/diag/tnslsnr/dbserver/listener/trace/ ...
- Pluck-CMS-Pluck-4.7.16 远程代码执行漏洞(CVE-2022-26965)
漏洞简介 Pluck CMS 4.7.16 版本的远程代码执行(RCE)漏洞(CVE-2022-26965). 该漏洞允许经过身份验证的用户通过 /admin.php?action=themeinst ...