SparkCore
一、概述
1,定义
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象。代码中是一个抽象类,它代表一个不可变、可分区、里面的元素可并行计算的集合。
2,RDD的特点
RDD表示制度的分区的数据集,对RDD进行改动,只能通过RDD的转换操作,由一个RDD得到一个新的RDD,新的RDD包含了从其他RDD衍生所必须的信息。RDDs之间存在依赖,RDD的执行是按照血缘关系延时计算的。如果血缘关系长,可以通过持久化RDD来切断血缘关系。
a)分区
RDD逻辑上是分区的,每个分区的数据是抽象存在的,计算的时候会通过一个compute函数得到每个分区的数据。
如果RDD是通过已有的文件系统构建,则compute函数是读取指定文件系统中的数据,如果RDD是通过其他RDD转换而来,则compute函数是执行转换逻辑将其他RDD的数据进行转换。
b)只读
RDD是只读的,要想改变RDD中的数据,只能在现有的RDD基础上创建新的RDD。
RDD的操作算子包括两类,一类叫做transformations(转换算子),它是用来将RDD进行转化,构建RDD的血缘关系;
另一类叫做actions(行动算子),它是用来触发RDD的计算,得到RDD的相关计算结果或者将RDD保存的文件系统中。
c)依赖
RDDs通过操作算子进行转换,转换得到的新RDD包含了其他RDDs衍生所必须的信息,RDDs之间维护着这种血缘关系,也称之为依赖。
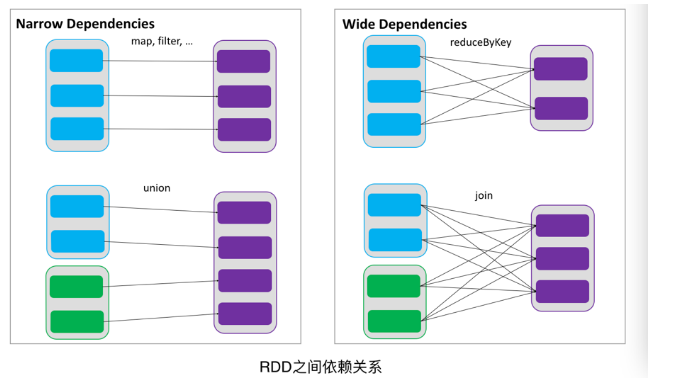
依赖分为两种:一种是窄依赖,RDDs之间分区是一一对应的;另一种是宽依赖,下游RDD的每个分区与上游的RDD(也称之为父RDD)的每个分区都有关,是多对多的关系。
d)缓存
如果在应用程序中多次使用同一个RDD,可以将该RDD缓存起来,该RDD只有在第一次计算的时候会根据血缘关系得到分区的数据,
在后续其他地方用到该RDD的时候,会直接从缓存处取而不用再根据血缘关系计算,这样就加速后期的重用。
如下图所示,RDD-1经过一系列的转换后得到RDD-n并保存到hdfs,RDD-1在这一过程中会有个中间结果,如果将其缓存到内存,
那么在随后的RDD-1转换到RDD-m这一过程中,就不会计算其之前的RDD-0了。

RDD通过persist方法或cache方法可以将前面的计算结果缓存,默认情况下 persist() 会把数据以序列化的形式缓存在 JVM 的堆空间中。但是并不是这两个方法被调用时立即缓存,而是触发后面的action时,该RDD将会被缓存在计算节点的内存中,并供后面重用。

e)CheckPoint
虽然RDD的血缘关系天然地可以实现容错,当RDD的某个分区数据失败或丢失,可以通过血缘关系重建。
但是对于长时间迭代型应用来说,随着迭代的进行,RDDs之间的血缘关系会越来越长,一旦在后续迭代过程中出错,则需要通过非常长的血缘关系去重建,势必影响性能。
为此,RDD支持checkpoint将数据保存到持久化的存储中,这样就可以切断之前的血缘关系,因为checkpoint后的RDD不需要知道它的父RDDs了,它可以从checkpoint处拿到数据。 //sc.setCheckpointDir设置检查点
二、RDD的创建
1,从集合中创建
//方式一
val rdd = sc.parallelize(Array(,,,,,,,))//1 to 8
//方式二
val rdd1 = sc.makeRDD(Array(,,,,,,,))// 1 to 8
2,从外部存储系统的数据集创建
val rdd2= sc.textFile("hdfs://hadoop102:9000/RELEASE") //从hdfs中读取
3,从其他RDD创建(RDD的转换)
三、RDD的分类以及转换
1,value类型
a)map()和mapPartition()
map():每次处理一条数据。
mapPartition():每次处理一个分区的数据,这个分区的数据处理完后,原RDD中分区的数据才能释放,可能导致OOM。
开发指导:当内存空间较大的时候建议使用mapPartition(),以提高处理效率。
b)flatMap
类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素)
c)coalesce()和repartition()
coalesce重新分区,可以选择是否进行shuffle过程。由参数shuffle: Boolean = false/true决定。默认为false
repartition实际上是调用的coalesce,默认是进行shuffle的。源码如下:
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
coalesce(numPartitions, shuffle = true)
}
d)distinct(numPartitions):去重,会进行shuffle
e)glom:将每一个分区形成一个数组,形成新的RDD类型时RDD[Array[T]]
f)filter:过滤。返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成。
g)sample(withReplacement, fraction, seed):withReplacement表示抽样数据是否放回,fraction为随机比例,seed随机种子
2,双value类型交互
a)union:对源RDD和参数RDD求并集后返回一个新的RDD
b)subtract:计算差的一种函数,去除两个RDD中相同的元素,不同的RDD将保留下来
c)intersection:对源RDD和参数RDD求交集后返回一个新的RDD
d)cartesian:笛卡尔积(尽量避免使用)
e)zip:将两个RDD组合成Key/Value形式的RDD,这里默认两个RDD的partition数量以及元素数量都相同,否则会抛出异常。
3,key-value类型
a)partitionBy:对pairRDD进行分区操作,如果原有的partionRDD和现有的partionRDD是一致的话就不进行分区,否则会生成ShuffleRDD,即会产生shuffle过程。自定义分区器继承Partitioner,重写方法即可自定义分区。
b)groupByKey与reduceByKey
reduceByKey:按照key进行聚合,在shuffle之前有combine(预聚合)操作,返回结果是RDD[k,v].
groupByKey:按照key进行分组,直接进行shuffle。
开发指导:reduceByKey比groupByKey,建议使用。但是需要注意是否会影响业务逻辑。
c)aggregateByKey:(zeroValue:U,[partitioner: Partitioner])(seqOp: (U, V) => U,combOp: (U, U) => U)
()zeroValue:给每一个分区中的每一个key一个初始值;
()seqOp:函数用于在每一个分区中用初始值逐步迭代value;
()combOp:函数用于合并每个分区中的结果。
//案例
val rdd = sc.parallelize(List(("a",),("a",),("c",),("b",),("c",),("c",)),)
val agg = rdd.aggregateByKey()(math.max(_,_),_+_)

d)foldByKey:(zeroValue: V)(func: (V, V) => V): RDD[(K, V)]。作用:aggregateByKey的简化操作,seqop和combop相同。
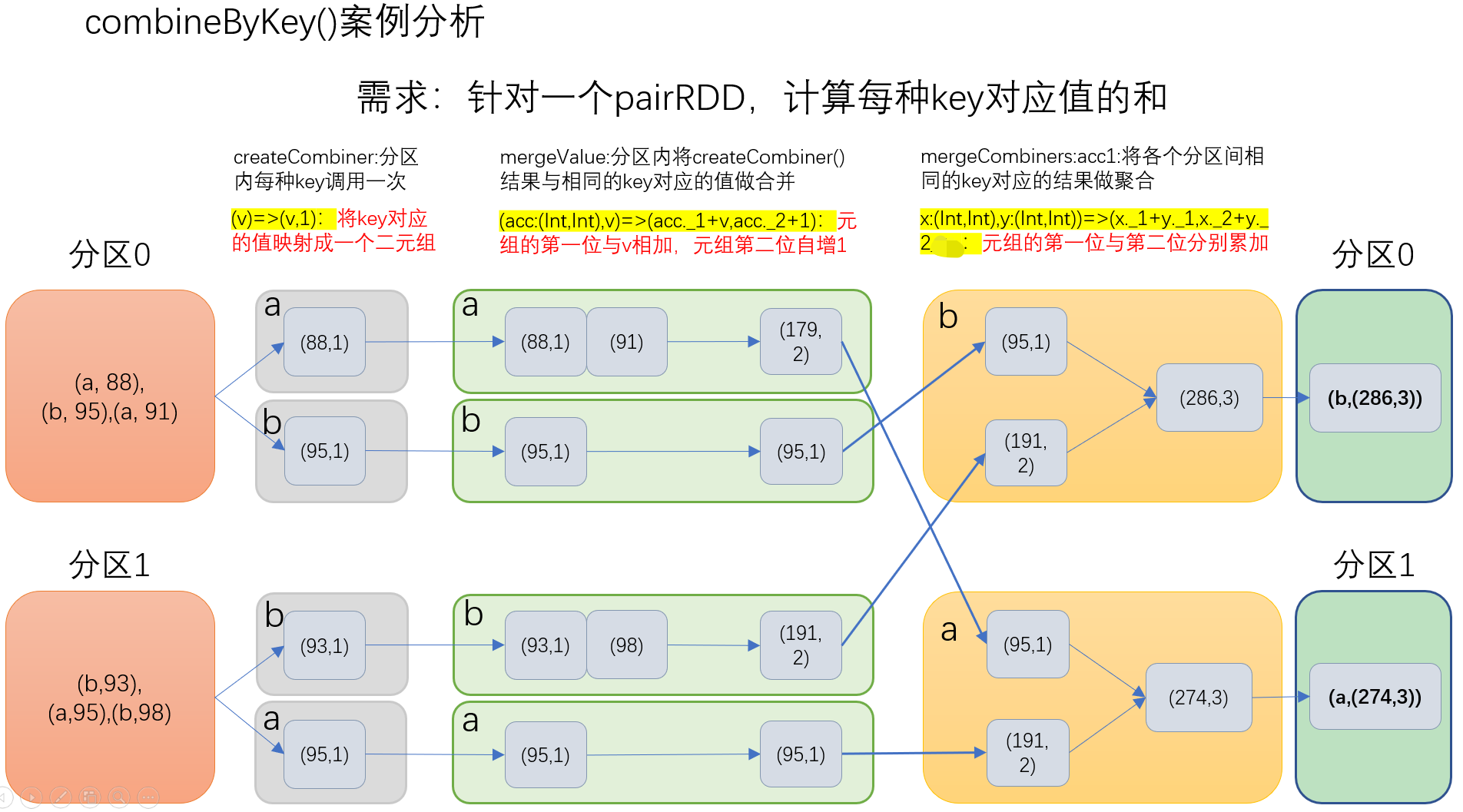
e)combineByKey:(createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C)
()createCombiner: combineByKey() 会遍历分区中的所有元素,因此每个元素的键要么还没有遇到过,要么就和之前的某个元素的键相同。如果这是一个新的元素,combineByKey()会使用一个叫作createCombiner()的函数来创建那个键对应的累加器的初始值
()mergeValue: 如果这是一个在处理当前分区之前已经遇到的键,它会使用mergeValue()方法将该键的累加器对应的当前值与这个新的值进行合并
()mergeCombiners: 由于每个分区都是独立处理的, 因此对于同一个键可以有多个累加器。如果有两个或者更多的分区都有对应同一个键的累加器, 就需要使用用户提供的 mergeCombiners() 方法将各个分区的结果进行合并。
//案例
val input = sc.parallelize(Array(("a", ), ("b", ), ("a", ), ("b", ), ("a", ), ("b", )),)
val combine = input.combineByKey((_,),(acc:(Int,Int),v)=>(acc._1+v,acc._2+),(acc1:(Int,Int),acc2:(Int,Int))=>(acc1._1+acc2._1,acc1._2+acc2._2)) //Array((b,(286,3)), (a,(274,3)))
f)sortByKey:在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD
val rdd = sc.parallelize(Array((,"aa"),(,"cc"),(,"bb"),(,"dd")))
//正序
rdd.sortByKey(true).collect()
//res9: Array[(Int, String)] = Array((1,dd), (2,bb), (3,aa), (6,cc))
g)mapValues:针对(K,V)形式的类型只对V进行操作
val rdd3 = sc.parallelize(Array((,"a"),(,"d"),(,"b"),(,"c")))
rdd3.mapValues(_+"|||").collect()
//res26: Array[(Int, String)] = Array((1,a|||), (1,d|||), (2,b|||), (3,c|||))
h)join:在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD
i)cogroup:在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable<V>,Iterable<W>))类型的RDD
4,Action
reduce、collect、count、first、take(n)、takeOrdered(n)、aggregate、fold、saveAsTextFile、saveAsSequenceFile、saveAsObjectFile、countByKey、foreach
四、RDD依赖关系
1,窄依赖
窄依赖指的是每一个父RDD的Partition最多被子RDD的一个Partition使用,窄依赖我们形象的比喻为独生子女
2,宽依赖
宽依赖指的是多个子RDD的Partition会依赖同一个父RDD的Partition,会引起shuffle,总结:宽依赖我们形象的比喻为超生
3,DAG有向无环图
原始的RDD通过一系列的转换就就形成了DAG,根据RDD之间的依赖关系的不同将DAG划分成不同的Stage,对于窄依赖,partition的转换处理在Stage中完成计算。对于宽依赖,由于有Shuffle的存在,只能在parent RDD处理完成后,才能开始接下来的计算,因此宽依赖是划分Stage的依据。
4,任务划分
application:一个application就是一个应用程序,包含了客户端所有的代码和计算资源SparkContext
job:一个action操作对应一个DAG有向无环图,即一个action操作就是一个job
stage:一个job中包含了大量的宽依赖,按照宽依赖进行stage划分,一个job产生了很多个stage
task:一个stage中有很多分区,一个分区就是一个task,即一个stage中有很多个task
sc.textFile("xx").flatMap(_.split(" ")).map((_,)).reduceByKey(_+_).saveAsTextFile("yy")
sc对应有个application
saveAsTextFile为一个Action
reduceByKey为一个shuffle,故而将当前job分为两个stage
五、RDD的分区器
Spark目前支持Hash分区和Range分区,用户也可以自定义分区,Hash分区为当前的默认分区,Spark中分区器直接决定了RDD中分区的个数、RDD中每条数据经过Shuffle过程属于哪个分区和Reduce的个数。
1,Hash分区
HashPartitioner分区的原理:对于给定的key,计算其hashCode,并除以分区的个数取余,如果余数小于0,则用余数+分区的个数(否则加0),最后返回的值就是这个key所属的分区ID。
2,Ranger分区
HashPartitioner分区弊端:可能导致每个分区中数据量的不均匀,极端情况下会导致某些分区拥有RDD的全部数据。
RangePartitioner作用:将一定范围内的数映射到某一个分区内,尽量保证每个分区中数据量的均匀,而且分区与分区之间是有序的,一个分区中的元素肯定都是比另一个分区内的元素小或者大,但是分区内的元素是不能保证顺序的。简单的说就是将一定范围内的数映射到某一个分区内。实现过程为:
第一步:先从整个RDD中抽取出样本数据,将样本数据排序,计算出每个分区的最大key值,形成一个Array[KEY]类型的数组变量rangeBounds;
第二步:判断key在rangeBounds中所处的范围,给出该key值在下一个RDD中的分区id下标;该分区器要求RDD中的KEY类型必须是可以排序的
3,自定义分区
要实现自定义的分区器,你需要继承 org.apache.spark.Partitioner 类并实现下面三个方法。
(1)numPartitions: Int:返回创建出来的分区数。
(2)getPartition(key: Any): Int:返回给定键的分区编号(0到numPartitions-1)。
(3)equals():Java 判断相等性的标准方法。这个方法的实现非常重要,Spark 需要用这个方法来检查你的分区器对象是否和其他分区器实例相同,这样 Spark 才可以判断两个 RDD 的分区方式是否相同。
六、RDD扩展
1,累加器:
分布式共享写变量:累加器用来对信息进行聚合,通常在向 Spark传递函数时,比如使用 map() 函数或者用 filter() 传条件时,可以使用驱动器程序中定义的变量,但是集群中运行的每个任务都会得到这些变量的一份新的副本,更新这些副本的值也不会影响驱动器中的对应变量。如果我们想实现所有分片处理时更新共享变量的功能,那么累加器可以实现我们想要的效果。
a)系统累加器
val longAccumulator = sc.longAccumulator
val doubleAccumulator = sc.doubleAccumulator
val accumulator = sc.collectionAccumulator[String]
b)自定义累加器
/**
* 用map存储,当输入的key在累加器中就将该key的value+1,不在就将累加器中就设置为1
* String作为输入,,mutable.HashMap[String,Long]作为输出
*/
class MapAccumulator extends AccumulatorV2[String,mutable.HashMap[String,Long]]{ val hashMap = new mutable.HashMap[String,Long]()
//判空
override def isZero: Boolean = hashMap.isEmpty
//复制
override def copy(): AccumulatorV2[String, mutable.HashMap[String, Long]] = {
val accumulator = new MapAccumulator
hashMap.synchronized{
accumulator.hashMap ++= this.hashMap
}
accumulator
}
//重置
override def reset(): Unit = hashMap.empty
//添加元素
override def add(key: String): Unit = {
hashMap.put(key,hashMap.getOrElse(key,0L)+1L)
}
//两个分区进行合并
override def merge(other: AccumulatorV2[String, mutable.HashMap[String, Long]]): Unit = {
val value = other.value
value.foreach{
case (k,v)=>
hashMap.put(k,hashMap.getOrElse(k, 0L)+v)
}
}
//返回值
override def value: mutable.HashMap[String, Long] = hashMap
}
val keyRDD = sc.makeRDD(List("aaa","bbb","ccc","aaa","ccc","aaa"),)
//TODO 创建累加器
val accumulator = new MapAccumulator
//TODO 注册累加器
sc.register(accumulator)
keyRDD.foreach{
key =>
//TODO 操作累加器
accumulator.add(key)
}
//TODO 获取累加器
val result = accumulator.value
2,广播变量
分布式共享读变量:广播变量用来高效分发较大的对象。向所有工作节点发送一个较大的只读值,以供一个或多个Spark操作使用。比如,如果你的应用需要向所有节点发送一个较大的只读查询表,甚至是机器学习算法中的一个很大的特征向量,广播变量用起来都很顺手。 在多个并行操作中使用同一个变量,但是 Spark会为每个任务分别发送。
val broadcastVar = sc.broadcast(Array(, , )) //声明广播变量
//broadcastVar: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(35)
broadcastVar.value //使用共享变量
//res33: Array[Int] = Array(1, 2, 3)
SparkCore的更多相关文章
- [数据挖掘] - 聚类算法:K-means算法理解及SparkCore实现
聚类算法是机器学习中的一大重要算法,也是我们掌握机器学习的必须算法,下面对聚类算法中的K-means算法做一个简单的描述: 一.概述 K-means算法属于聚类算法中的直接聚类算法.给定一个对象(或记 ...
- 【Spark-core学习之八】 SparkShuffle & Spark内存管理
[Spark-core学习之八] SparkShuffle & Spark内存管理环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 ...
- SparkCore基础(二)
* SparkCore基础(二) 继续探讨SparkCore,开门见山,不多废话. SparkApplication结构探讨 包含关系: 之前我们运行过很多App了,其实每一个App都包含若干个Job ...
- SparkCore基础(一)
* SparkCore基础(一) 学习Spark,首先要熟悉Scala,当然你说你会Python或者Java能不能玩Spark?能!但是不推荐,首推Scala,因为Scala非常便捷,而且Scala有 ...
- [Spark] - SparkCore程序优化总结
http://spark.apache.org/docs/1.6.1/tuning.html1) 代码优化 a. 对于多次使用的RDD,进行数据持久化操作(eg: cache.persist) b. ...
- SparkCore | Rdd| 广播变量和累加器
Spark中三大数据结构:RDD: 广播变量: 分布式只读共享变量: 累加器:分布式只写共享变量: 线程和进程之间 1.RDD中的函数传递 自己定义一些RDD的操作,那么此时需要主要的是,初始化工作 ...
- SparkCore| 算子
RDD RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象.代码中是一个抽象类,它代表一个弹性的.不可变.可分区.里面的元素可并行 ...
- 【Spark-core学习之九】 Spark案例
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 scala-2.10.4(依赖jdk1.8) spark ...
- 【Spark-core学习之七】 Spark广播变量、累加器
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 scala-2.10.4(依赖jdk1.8) spark ...
- 【Spark-core学习之六】 Spark资源调度和任务调度
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 scala-2.10.4(依赖jdk1.8) spark ...
随机推荐
- Python三大器之生成器
Python三大器之生成器 生成器初识 什么是生成器 生成器本身属于迭代器.继承了迭代器的特性,惰性求值,占用内存空间极小. 为什么要有生成器 我们想使用迭代器本身惰性求值的特点创建出一个可以容纳百万 ...
- JDK8--03:lambda表达式语法
对于lambda表达式的基础语法,一个是要了解lambda表达式的基础语法,另外一个是需要了解函数式接口 一.lambda表达式基础语法描述 java8中引入了新的操作符 -> ,可以称为l ...
- 【CSGRound1】天下第一 题解
[CSGRound1]天下第一 https://www.luogu.com.cn/problem/P5635 分析题目: 题目中说明,有T组数据,但是mod只有一个.很显然,这道题可以用记忆化搜索嘛! ...
- 关于Spring Boot中的业务层(Service)是否要创建接口的分析
在借助Spring Boot框架开发web项目时,在业务层(Service)这一部分,标准做法是:定义一个接口,然后再一个或多个类去实现.那么疑问来了: 为什么我们要维护两份同构代码,而不直接使用一个 ...
- vue安装及创建项目的几种方式
原文地址:https://www.wjcms.net/archives/vue安装及创建项目的几种方式 VUE安装的方式 直接用 script标签 引入 对于制作原型或学习,你可以这样使用最新版本: ...
- 通过原生js对DOM事件的绑定的几种方式总汇
在网页开发中经常会有交互操作,比如点击一个dom元素,需要让js对该操作做出相应的响应,这就需要对Dom元素进行事件绑定来进行处理,js通常有三种常用的方法进行事件绑定:在DOM元素中直接绑定:在Ja ...
- HTML5(五)Geolocation
HTML5 Geolocation 定位用户的位置 HTML5 Geolocation API 用于获得用户的地理位置. 鉴于该特性可能侵犯用户的隐私,除非用户同意,否则用户位置信息是不可用的. 注意 ...
- let import export React入门实例教程 connect provider combineReducers 箭头函数 30分钟掌握ES6/ES2015核心内容 Rest babel
let与var的区别 http://www.cnblogs.com/snandy/archive/2015/05/10/4485832.html es6 导入导出 http://www.csdn.ne ...
- 关于display的box和flex布局
关于二者的区别于联系,在知乎上看到有人这么回答的 flex 2012年的语法,也将是以后标准的语法,大部分浏览器已经实现了无前缀版本. box是2009年的语法,已经过时,是需要加上对应前缀的. 另外 ...
- NOI 2003 逃学的小孩 (树的直径)
[NOI2003 逃学的小孩] 题目描述 Chris家的电话铃响起了,里面传出了Chris的老师焦急的声音:"喂,是Chris的家长吗?你们的孩子又没来上课,不想参加考试了吗?"一 ...