elasticsearch中使用bucket script进行聚合
1、背景
此篇文档简单的记录一下在es使用bucket script来进行聚合的一个例子。
2、需求
假设我们有一个简单的卖车数据,记录每个月month在卖了brand品牌的车salesVolume的数量。
此处我们需要聚合出 每个月brand=宝马的车在每个月的销售占比
3、准备数据
3.1 mapping
PUT /index_bucket_script
{
"mappings": {
"properties": {
"month": {
"type": "keyword"
},
"brand": {
"type": "keyword"
},
"salesVolume": {
"type": "integer"
}
}
}
}
3.2 插入数据
PUT /index_bucket_script/_bulk
{"index":{"_id":1}}
{"month":"2023-01","brand":"宝马","salesVolume":100}
{"index":{"_id":3}}
{"month":"2023-02","brand":"大众","salesVolume":80}
{"index":{"_id":4}}
{"month":"2023-02","brand":"宝马","salesVolume":20}
注意: 此处2023-02月份的数据插入了2个品牌的数据。
4、bucket_script聚合的语法

5、聚合
5.1 根据月份分组排序
GET index_bucket_script/_search
{
"query": {
"match_all": {}
},
"size": 0,
"aggs": {
"根据月份分组": {
"terms": {
"field": "month",
"order": {
"_key": "asc"
}
}
}
}
}
5.2 统计每个月卖了多少辆车
GET index_bucket_script/_search
{
"query": {
"match_all": {}
},
"size": 0,
"aggs": {
"根据月份分组": {
"terms": {
"field": "month",
"order": {
"_key": "asc"
}
},
"aggs": {
"统计每个月卖了多少辆车": {
"sum": {
"field": "salesVolume"
}
}
}
}
}
}
5.3 统计每个月卖了多少宝马车
GET index_bucket_script/_search
{
"query": {
"match_all": {}
},
"size": 0,
"aggs": {
"根据月份分组": {
"terms": {
"field": "month",
"order": {
"_key": "asc"
}
},
"aggs": {
"统计每个月卖了多少辆车": {
"sum": {
"field": "salesVolume"
}
},
"统计每个月卖了多少宝马车": {
"filter": {
"term": {
"brand": "宝马"
}
},
"aggs": {
"每个月卖出的宝马车辆数": {
"sum": {
"field": "salesVolume"
}
}
}
}
}
}
}
}
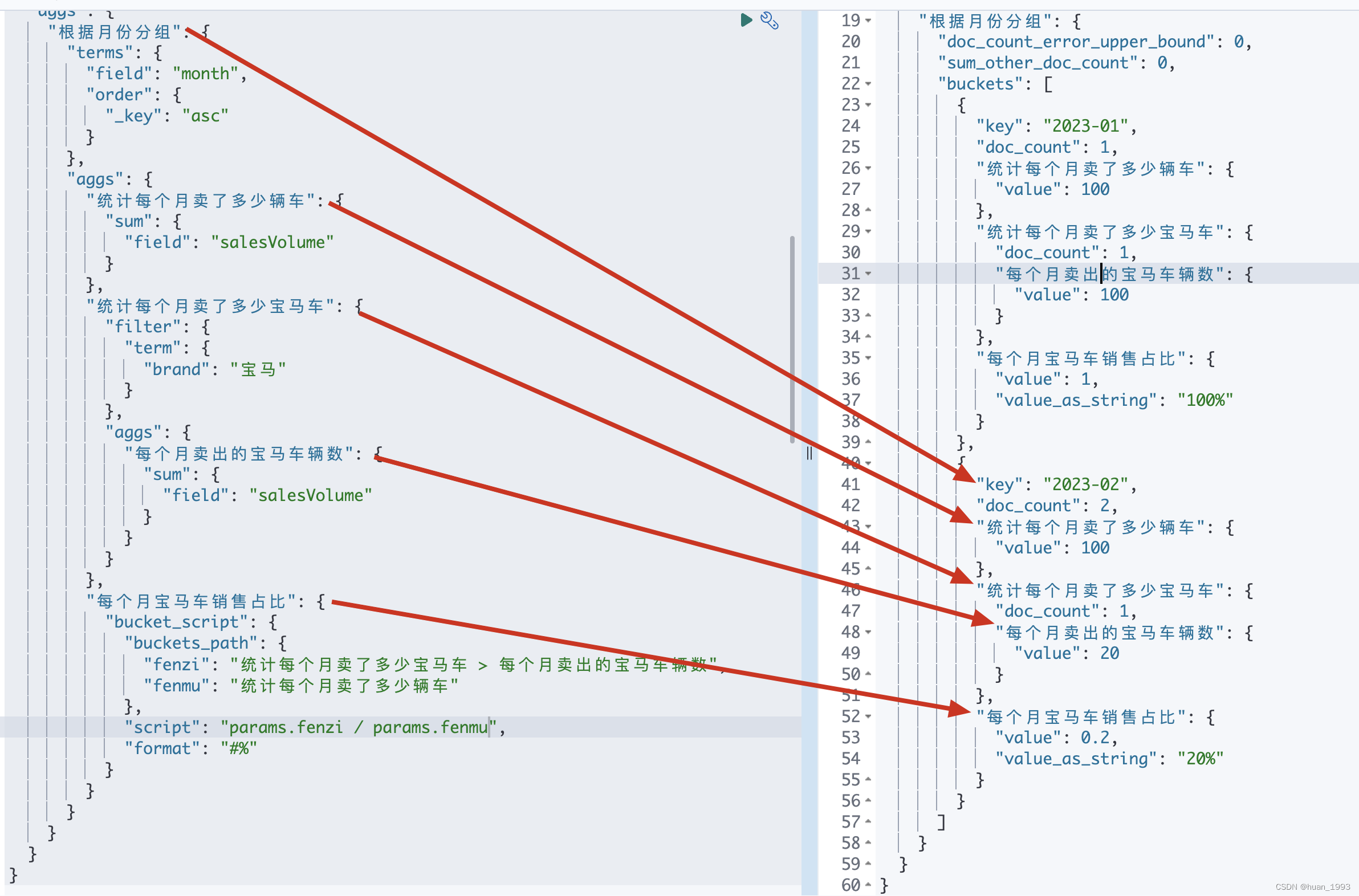
5.4 每个月宝马车销售占比
5.4.1 dsl
GET index_bucket_script/_search
{
"query": {
"match_all": {}
},
"size": 0,
"aggs": {
"根据月份分组": {
"terms": {
"field": "month",
"order": {
"_key": "asc"
}
},
"aggs": {
"统计每个月卖了多少辆车": {
"sum": {
"field": "salesVolume"
}
},
"统计每个月卖了多少宝马车": {
"filter": {
"term": {
"brand": "宝马"
}
},
"aggs": {
"每个月卖出的宝马车辆数": {
"sum": {
"field": "salesVolume"
}
}
}
},
"每个月宝马车销售占比": {
"bucket_script": {
"buckets_path": {
"fenzi": "统计每个月卖了多少宝马车 > 每个月卖出的宝马车辆数",
"fenmu": "统计每个月卖了多少辆车"
},
"script": "params.fenzi / params.fenmu * 100"
}
}
}
}
}
}
5.4.2 java
@Test
@DisplayName("统计宝马车每个月销售率")
public void test01() throws IOException {
SearchRequest request = SearchRequest.of(searchRequest ->
searchRequest.index(INDEX_PERSON)
.query(query -> query.matchAll(matchAll -> matchAll))
.size(0)
.aggregations("根据月份分组", monthAggr ->
monthAggr.terms(terms -> terms.field("month").order(
NamedValue.of("_key", SortOrder.Asc)
))
.aggregations("统计每个月卖了多少辆车", agg1 ->
agg1.sum(sum -> sum.field("salesVolume"))
)
.aggregations("统计每个月卖了多少宝马车", agg2 ->
agg2.filter(filter -> filter.term(term -> term.field("brand").value("宝马")))
.aggregations("每个月卖出的宝马车辆数", agg3 ->
agg3.sum(sum -> sum.field("salesVolume"))
)
)
.aggregations("每个月宝马车销售占比", rateAggr ->
rateAggr.bucketScript(bucketScript ->
bucketScript.bucketsPath(path ->
path.dict(
new HashMap<String, String>() {
{
put("fenzi", "统计每个月卖了多少宝马车>每个月卖出的宝马车辆数");
put("fenmu", "统计每个月卖了多少辆车");
}
}
)
)
.script(script ->
script.inline(inline -> inline.source("params.fenzi/params.fenmu"))
)
.format("#%")
)
)
)
);
System.out.println("request: " + request);
SearchResponse<String> response = client.search(request, String.class);
System.out.println("response: " + response);
}
5.4.3 运行结果
5、完整代码
6、参考文档
1、https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-pipeline.html#buckets-path-syntax
2、https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-pipeline-bucket-script-aggregation.html
3、https://docs.oracle.com/en/java/javase/17/docs/api/java.base/java/text/DecimalFormat.html
elasticsearch中使用bucket script进行聚合的更多相关文章
- Elasticsearch 中映射参数doc_values 和 fielddata分析比较
doc_values 默认情况下,大部分字段是索引的,这样让这些字段可被搜索.倒排索引(inverted index)允许查询请求在词项列表中查找搜索项(search term),并立即获得包含该词项 ...
- Elasticsearch使用系列-基本查询和聚合查询+sql插件
Elasticsearch使用系列-ES简介和环境搭建 Elasticsearch使用系列-ES增删查改基本操作+ik分词 Elasticsearch使用系列-基本查询和聚合查询+sql插件 Elas ...
- ES 15 - Elasticsearch中的数据类型 (text、keyword、date、geo等)
目录 1 核心数据类型 1.1 字符串类型 - string(不再支持) 1.1.1 文本类型 - text 1.1.2 关键字类型 - keyword 1.2 数字类型 - 8种 1.3 日期类型 ...
- ElasticSearch中倒排索引和正向索引
ElasticSearch搜索使用的是倒排索引,但是排序.聚合等不适合倒排索引使用的是正向索引 倒排索引 倒排索引表以字或词为关键字进行索引,表中关键字所对应的记录项记录了出现这个字或词的所有文档,每 ...
- ElasticSearch中的sort排序和filedData作用
默认情况下,ElasticSearch 会根据算分进行排序: 可以使用 sort API 指定排序的规则: POST /kibana_sample_data_ecommerce/_search { & ...
- Elasticsearch中最重要的文档CRUD要牢记
Elasticsearch文档CRUD要牢记 转载参考:https://juejin.im/post/5ddbf298e51d4523053c42e7 在Elasticsearch中,文档(docum ...
- Elasticsearch 中为什么选择倒排索引而不选择 B 树索引
目录 前言 为什么全文索引不使用 B+ 树进行存储 全文检索 正排索引 倒排索引 倒排索引如何存储数据 FOR 压缩 RBM 压缩 倒排索引如何存储 字典树(Tria Tree) FST FSM 构建 ...
- Elasticsearch中的一些重要概念:cluster, node, index, document, shards及replica
首先,我们来看下一下如下的这个图: Cluster Cluster也就是集群的意思.Elasticsearch集群由一个或多个节点组成,可通过其集群名称进行标识.通常这个Cluster 的名字是可以在 ...
- 如何在Elasticsearch中安装中文分词器(IK+pinyin)
如果直接使用Elasticsearch的朋友在处理中文内容的搜索时,肯定会遇到很尴尬的问题--中文词语被分成了一个一个的汉字,当用Kibana作图的时候,按照term来分组,结果一个汉字被分成了一组. ...
- elasticsearch中常用的API
elasticsearch中常用的API分类如下: 文档API: 提供对文档的增删改查操作 搜索API: 提供对文档进行某个字段的查询 索引API: 提供对索引进行操作,查看索引信息等 查看API: ...
随机推荐
- Aspose.Cell和NPOI生成Excel文件
1.使用Aspose.Cell生成Excel文件,Aspose.Cell是.NET组件控件,不依赖COM组件 1首先一点需要使用新建好的空Excel文件做模板,否则容易产生一个多出的警告Sheet 1 ...
- 重启redis
[root@lecode-dev-001 packages]# /usr/local/redis/bin/redis-cli -p 6379 127.0.0.1:6379> auth Redis ...
- mindxdl--common--type.go
// Copyright (c) 2021. Huawei Technologies Co., Ltd. All rights reserved.// Package common this file ...
- 安装kali linux(干货)
安装kali 一. 准备工具 1. VMware Workstation Pro https://www.vmware.com/cn/products/workstation-pro/workstat ...
- 华为云平台部署教程之CNA\VRM的安装
本教程仅含华为云平台搭建部署中CNA和VRM的安装,请按需求选择查看本文. 一.前期准备 1.硬件 服务器*4 交换机*3 网线 个人PC机 2.软件 PC机系统(win7/win10) KVM软件 ...
- c++题目:吃西瓜
吃西瓜 [问题描述] 老胡买了是长方体形的西瓜来犒劳大家.... 这块西瓜长m厘米,宽n厘米,高h厘米.他发现如果把这块西瓜平均地分成m*n*h块1立方厘米的小正方体,那么每一小块都会有一个营养值(可 ...
- 2 c++编程-核心
重新系统学习c++语言,并将学习过程中的知识在这里抄录.总结.沉淀.同时希望对刷到的朋友有所帮助,一起加油哦! 本章是继上篇 c++编程-基础 之后的 c++ 编程-核心. 生命就像一朵花,要拼尽 ...
- vscode+springboot+gradle
vscode+springboot+gradle 项目搭建 demo 目标:项目中抛弃所有xml格式文件 啰嗦: 一直在用maven作为项目的依赖包管理,最近看到基于Java17 的 Spring f ...
- angr_ctf——从0学习angr(三):Hook与路径爆炸
路径爆炸 之前说过,angr在处理分支时,采取统统收集的策略,因此每当遇见一个分支,angr的路径数量就会乘2,这是一种指数增长,也就是所说的路径爆炸. 以下是路径爆炸的一个例子: char buff ...
- 【敏捷研发系列】前端DevOps流水线实践
作者:胡骏 一.背景现状 软件开发从传统的瀑布流方式到敏捷开发,将软件交付过程中开发和测试形成快速的迭代交付,但在软件交付客户之前或者使用过程中,还包括集成.部署.运维等环节需要进一步优化交付效率.因 ...