Python数据科学手册-Pandas:累计与分组
简单累计功能
Series sum() 返回一个 统计值
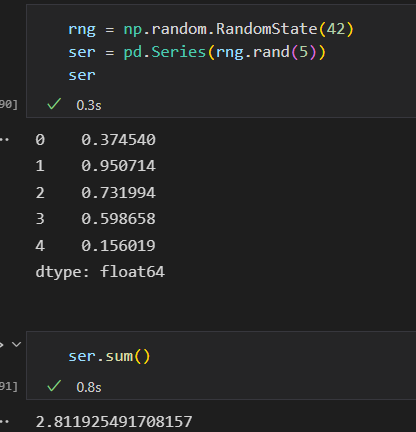
DataFrame sum。默认对每列进行统计
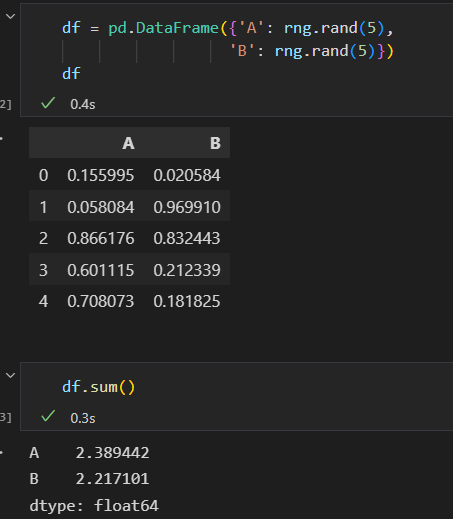
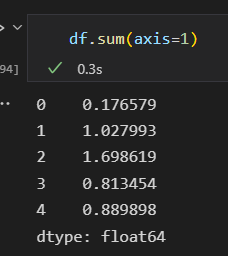
设置axis参数,对每一行 进行统计
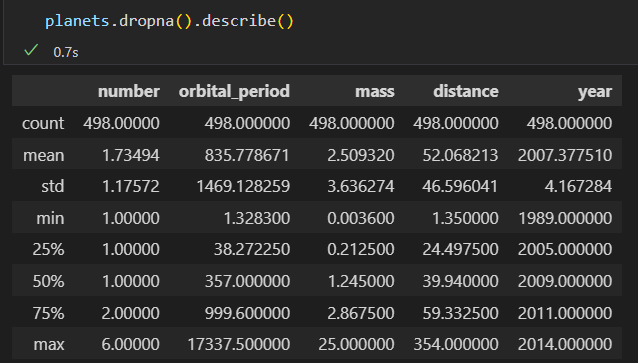
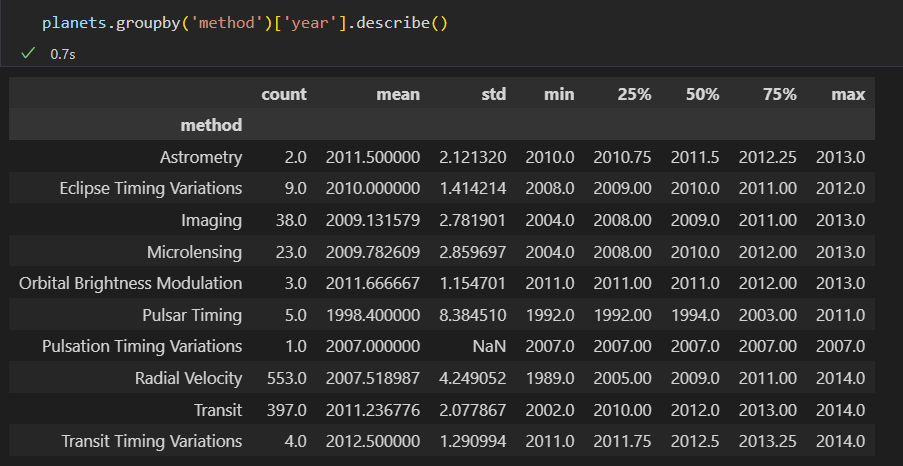
describe()可以计算每一列的若干常用统计值。
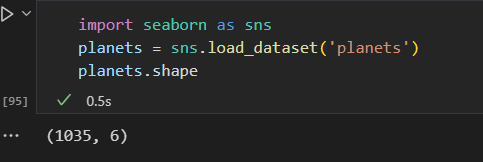
获取seaborn planets数据
github: https://github.com/mwaskom/seaborn-data.git
windows: 放在用户目录下(在线下载卡。超时。)
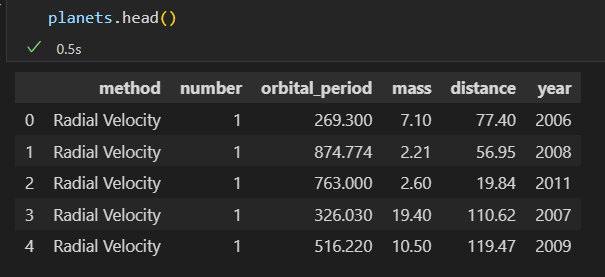
dropna()丢弃有缺失值的行。
Pandas累计方法
| Aggregation | Description |
|---|---|
| count() | Total number of items |
| first(), last() | First and last item |
| mean(), median() | Mean and median |
| min(), max() | Minimum and maximum |
| std(), var() | Standard deviation and variance |
| mad() | Mean absolute deviation |
| prod() | Product of all items |
| sum() | Sum of all items |
Groupy: 分割、应用和组合
split、 apply、combine
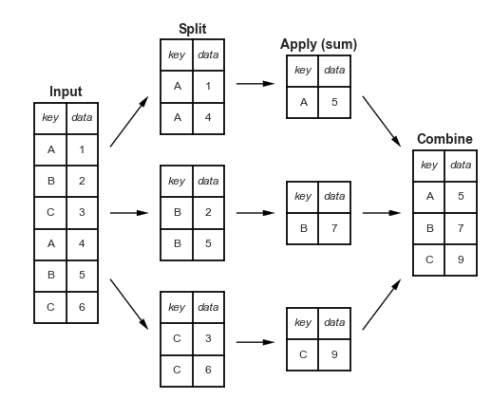
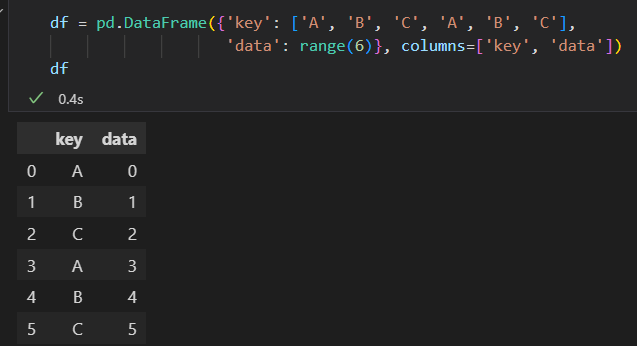
groupby()方法传递参数列名。返回值是个DataFrameGroupBy对象。

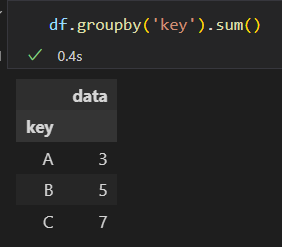
GroupBy对象。
可以看成是DataFrame的集合。
常用的操作:aggregate(累计)、filter(过滤)、transform(转换)、apply(应用)
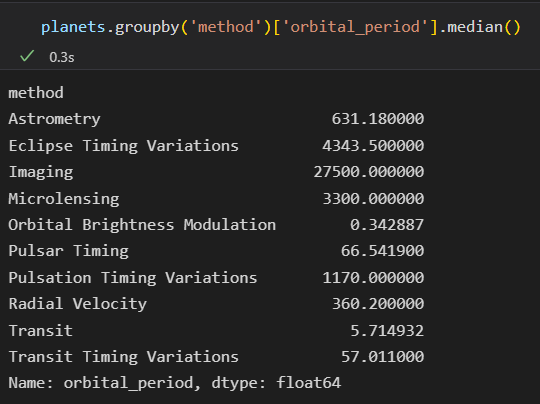
1)按列取值
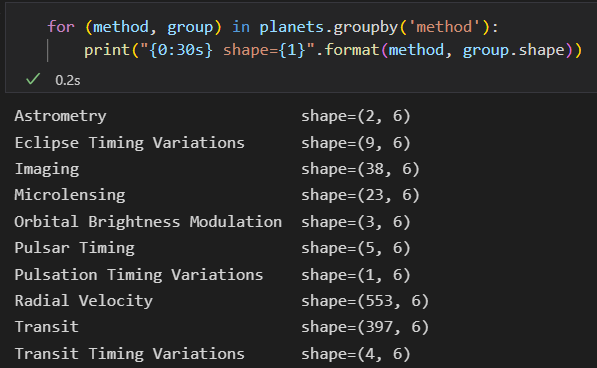
2)按组迭代,返回的每一组都是Series 或 DataFrame
3) 调用方法
累计 过滤 转换 应用
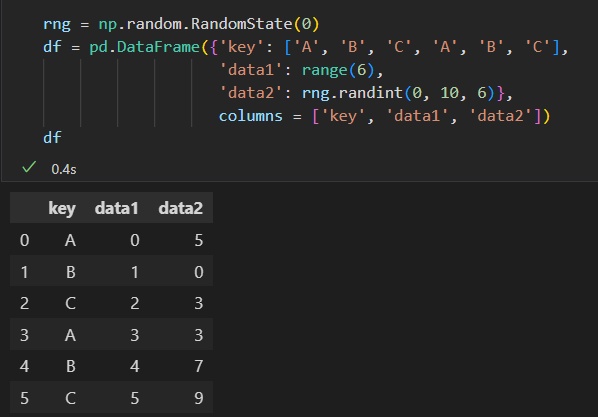
1)累计 aggregate
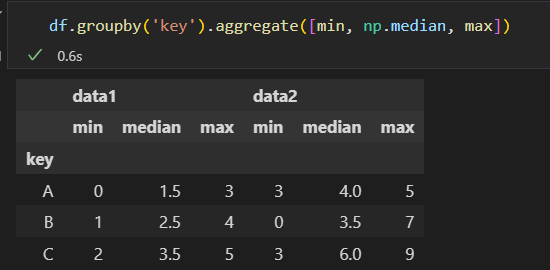
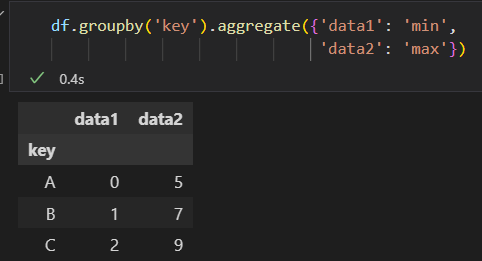
2) 过滤 filter
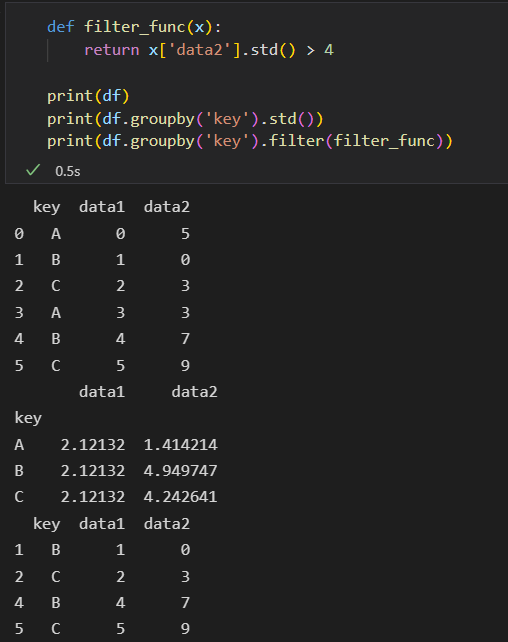
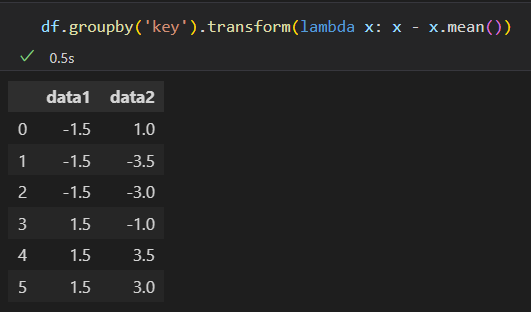
- 转换 transform
累计操作 对组内全量数据缩减的结果。 而 转换 操作 会返回一个新的全量数据
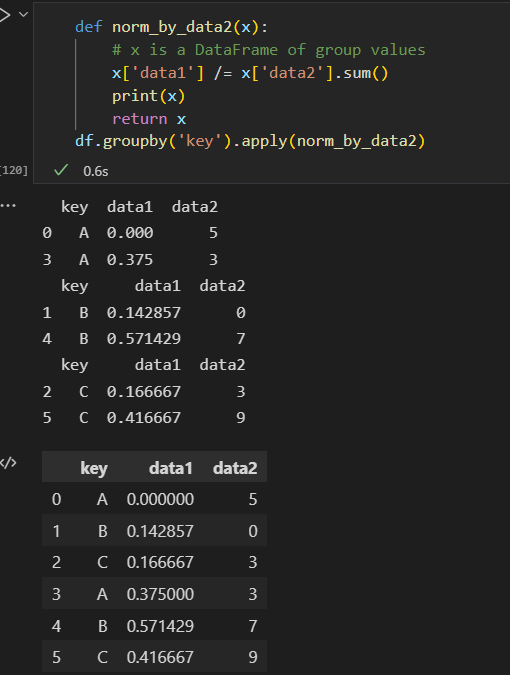
4)apply()
输入一个DataFrame 对象,f返回一个Pandas对象 或 单个数值。 组合操作会 适应返回结果类型。
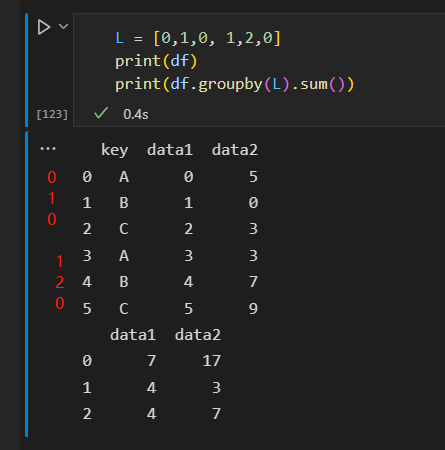
设置分割的键
1)将列表、数组、Series或 索引作为分组键
2)用字典或 Series将索引 映射到 分组名称
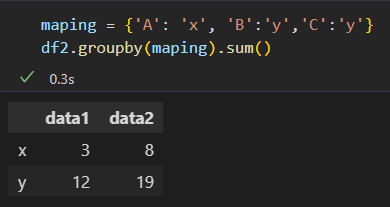
3)任意python函数,函数映射到索引
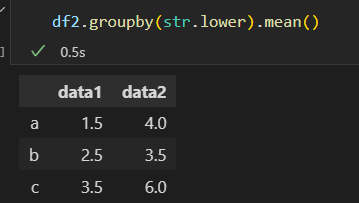
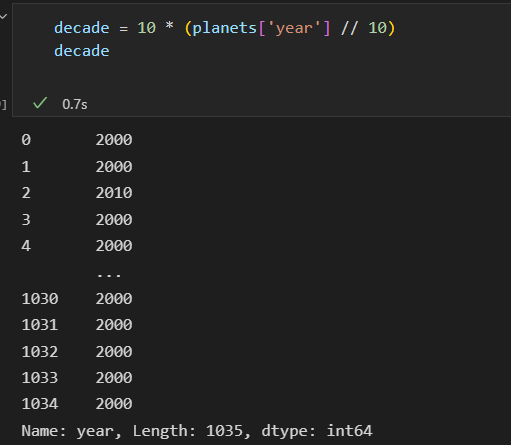
分组案例
以十年为一个时间段。
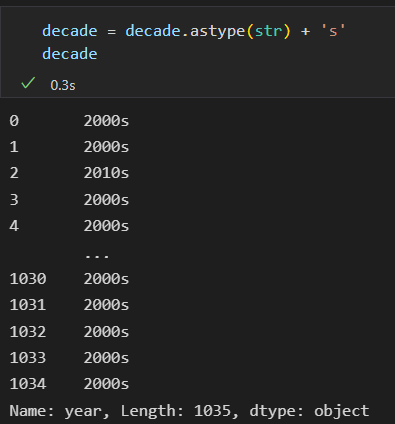
加上s
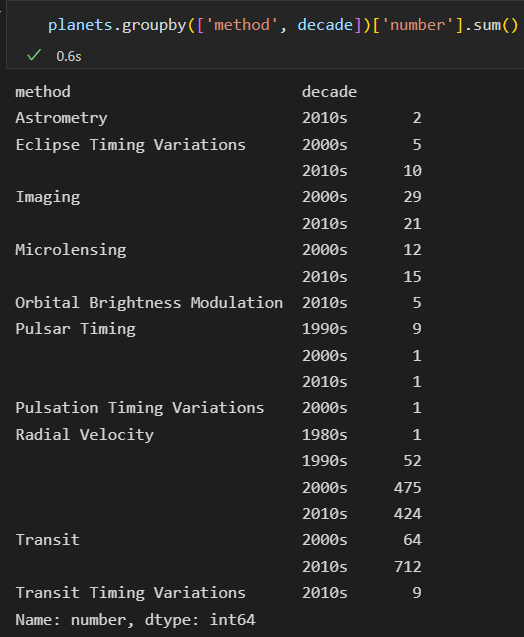
这里 groupby 俩个值。懵逼了。
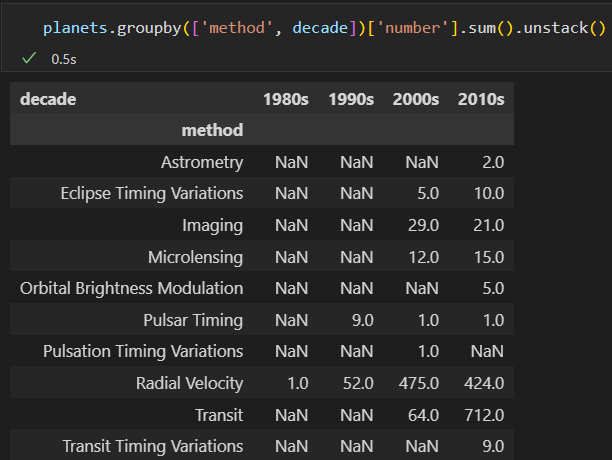
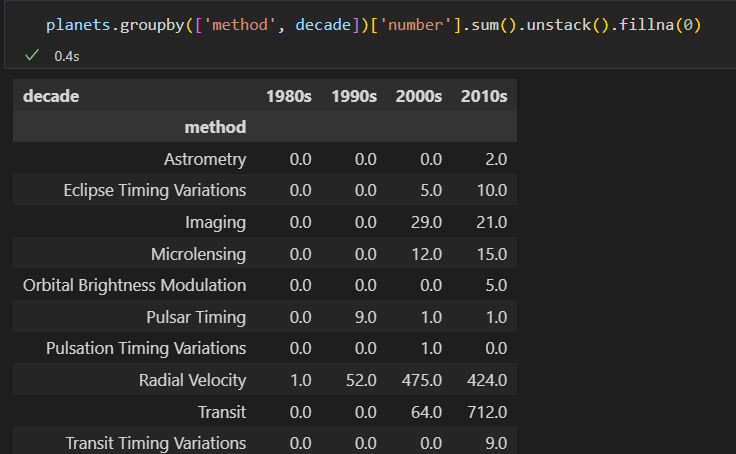
数据透视表
groupby 是探索数据内部的关联性 。
数据透视表: pivottable 是一种类似的操作方法。常见与Excel与类似的表格 应用中。
数据透视表 将每一列 数据作为输入, 输出将数据不断细分 成多个维度累计信息的 二维数据表。
是多维的GroupBy累计操作。
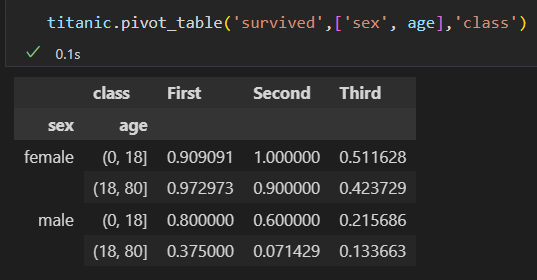
泰坦尼克号 乘客 数据
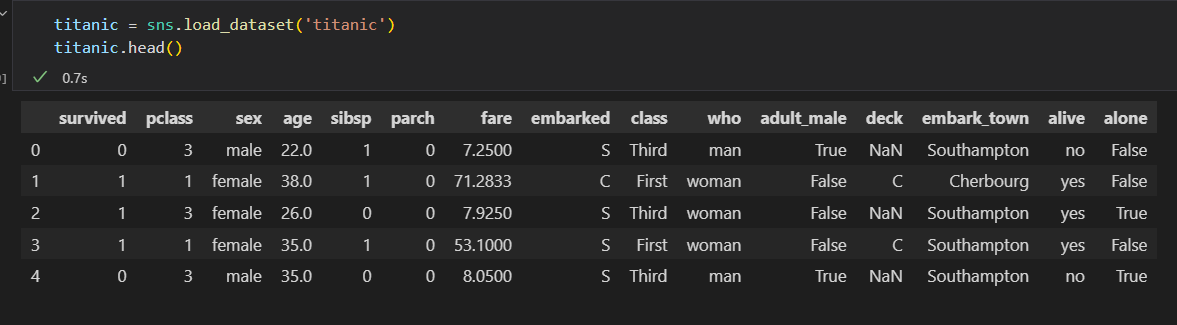
1)按照性别 、最终生还状态 进行分组
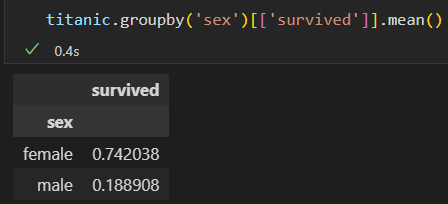
2)进一步 探索,不同性别与船舱 等级的生还情况。
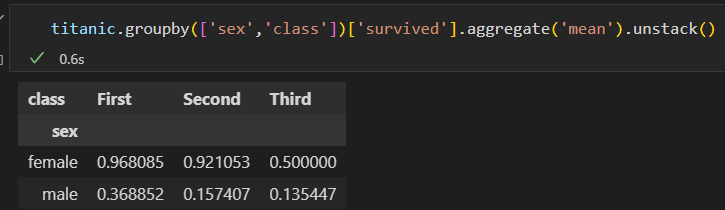
3)上面这个是不是感觉很复杂。使用pivot_table 就会简单
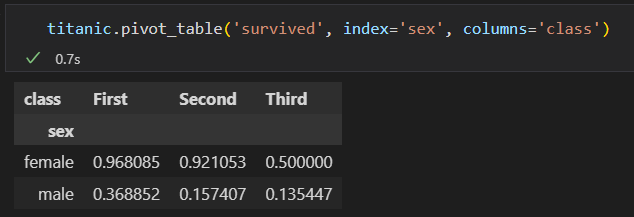
一等舱的女性 生还率最高。 三等舱的生还率 最低
好好努力
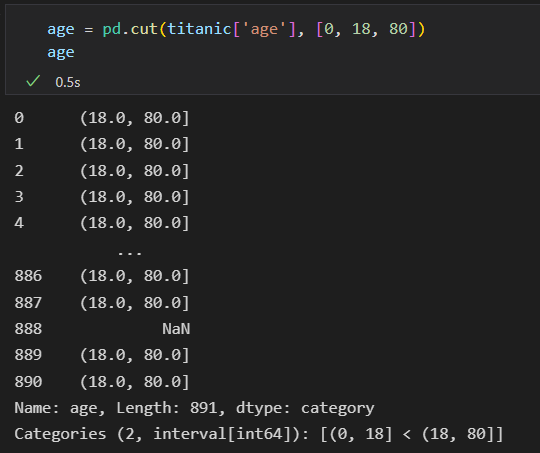
4)再把年龄也加进去。 多级数据透视表
5)其他选项
Python数据科学手册-Pandas:累计与分组的更多相关文章
- Python数据科学手册-Pandas:向量化字符串操作、时间序列
向量化字符串操作 Series 和 Index对象 的str属性. 可以正确的处理缺失值 方法列表 正则表达式. Method Description match() Call re.match() ...
- Python数据科学手册-Pandas:数值运算方法
Numpy 的基本能力之一是快速对每个元素进行运算 Pandas 继承了Numpy的功能,也实现了一些高效技巧. 对于1元运算,(函数,三角函数)保留索引和列标签 对于2元运算,(加法,乘法),Pan ...
- Python数据科学手册-Pandas:层级索引
一维数据 和 二维数据 分别使用Series 和 DataFrame 对象存储. 多维数据:数据索引 超过一俩个 键. Pandas提供了Panel 和 Panel4D对象 解决三维数据和四维数据. ...
- Python数据科学手册-Pandas:数据取值与选择
Numpy数组取值 切片[:,1:5], 掩码操作arr[arr>0], 花哨的索引 arr[0, [1,5]],Pandas的操作类似 Series数据选择方法 Series对象与一维Nump ...
- Python数据科学手册-Pandas数据处理之简介
Pandas是在Numpy基础上建立的新程序库,提供了一种高效的DataFrame数据结构 本质是带行标签 和 列标签.支持相同类型数据和缺失值的 多维数组 增强版的Numpy结构化数组 行和列不在只 ...
- Python数据科学手册-Pandas:合并数据集
将不同的数据源进行合并 , 类似数据库 join merge . 工具函数 concat / append pd.concat() 简易合并 合并高维数据 默认按行合并. axis=0 ,试试 axi ...
- 100天搞定机器学习|day45-53 推荐一本豆瓣评分9.3的书:《Python数据科学手册》
<Python数据科学手册>共五章,每章介绍一到两个Python数据科学中的重点工具包.首先从IPython和Jupyter开始,它们提供了数据科学家需要的计算环境:第2章讲解能提供nda ...
- Python数据科学手册
Python数据科学手册(高清版)PDF 百度网盘 链接:https://pan.baidu.com/s/1KurSdjNWiwMac3o3iLrzBg 提取码:qogy 复制这段内容后打开百度网盘手 ...
- Matplotlib 使用 - 《Python 数据科学手册》学习笔记
一.引入 import matplotlib as mpl import matplotlib.pyplot as plt 二.配置 1.画图接口 Matplotlib 有两种画图接口: (1)一个是 ...
随机推荐
- 反向传播神经网络(BP)
实验部分: ①输入.输出矢量及问题的阐述 由题意输入变量取值范围为e={-2,-1,0,1,2}和ec={-2,-1,0,1,2},则输入矢量有25种情况,分别如下所示: 则由T=int((e+ec) ...
- 使用xpath查找元素的子元素,找不到
List<WebElement> allUserList = driver.findElements(By.xpath("xxx")); for (WebElement ...
- -bash: nignx: 未找到命令
nignx -t 如果报错: 因为没有配置环境变量吧,把nginx路径 配置到环境变量里面就可以. 按照配置: 1:进入 vim /etc/profile 文件 在配置文件的最后面添加PATH(PAT ...
- 06 MySQL_数据冗余
数据冗余--拆分表 如果表设计不合理,可能会出现大量的重复数据,这种现象被称为数据冗余,通过拆分表的形式可以解决此问题 保存集团总部下财务部里面的财务A部的张三工资8000 年龄18 保存集团总部下研 ...
- led跑马灯多种方法(移位法,位拼接法,调用模块法,位移及位拼接语法,testbench的理解,源文件的存储路径,计数器的个数,调用模块的方式)
跟着教程写了几种方法,才发现自己写的虽然能实现,但比较繁琐.教程有三种方法: 1.移位法,每次左移一位,相比我自己写的,优点是不用把每一种情况都写出来.但是需要考虑左移到最后一位时需要自己再写个赋值语 ...
- Techempower web框架性能测试第21轮结果发布--asp.net core继续前进
废话不说,直接上结果: Round 21 results - TechEmpower Framework Benchmarks Techempower benchmark是包含范围最广泛的web框架性 ...
- windows版本rabbitmq安装及日志level设置
1.DirectX Repair 安装缺失的C++组件,不安装缺失的组件会造成第二部安装erl文件夹缺少bin文件夹2.安装otp_win64_23.1 1.配置 ERLANG_HOME:地址为Erl ...
- odoo14 入门解刨关联字段
Odoo中关联字段是用来绑定表与表之间主从关系的. 主从关系指: 首先必须要明白id的存在的意义,它具备"唯一"的属性,也就是表中所有记录中该字段的值不会重复. 假设表A存储是身份 ...
- C# 虚方法、抽象方法
一.虚方法(virtual) 作用:当有一个定义在类中的函数需要在继承类中实现时,可以使用虚方法. 示例: class Person { public virtual void XXX() { Con ...
- 趣味问题《寻人启事》的Python程序解决
偷懒了很久,今天我终于又来更新博客了~ 最近,我看到了一个趣味问题,或者说是数学游戏:<寻人启事>. 在表述这个问题前,我们需要了解一下"冰雹猜想": 对于任意一个正整 ...