吴裕雄--天生自然python编程:实例(2)
list1 = [10, 20, 4, 45, 99]
list1.sort() print("最小元素为:", *list1[:1])
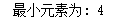
list1 = [10, 20, 1, 45, 99]
print("最小元素为:", min(list1))
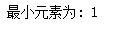
list1 = [10, 20, 4, 45, 99]
list1.sort()
print("最大元素为:", list1[-1])
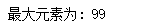
list1 = [10, 20, 1, 45, 99]
print("最大元素为:", max(list1))
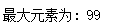
test_str = "Runoob" # 输出原始字符串
print ("原始字符串为 : " + test_str) # 移除第三个字符 n
new_str = "" for i in range(0, len(test_str)):
if i != 2:
new_str = new_str + test_str[i] print ("字符串移除后为 : " + new_str)

def check(string, sub_str):
if (string.find(sub_str) == -1):
print("不存在!")
else:
print("存在!") string = "www.runoob.com"
sub_str ="runoob"
check(string, sub_str)

str = "runoob"
print(len(str))

def findLen(str):
counter = 0
while str[counter:]:
counter += 1
return counter str = "runoob"
print(findLen(str))

import re def Find(string):
# findall() 查找匹配正则表达式的字符串
url = re.findall('https?://(?:[-\w.]|(?:%[\da-fA-F]{2}))+', string)
return url string = 'Runoob 的网页地址为:https://www.runoob.com,Google 的网页地址为:https://www.google.com'
print("Urls: ", Find(string))
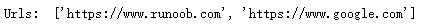
def exec_code():
LOC = """
def factorial(num):
fact=1
for i in range(1,num+1):
fact = fact*i
return fact
print(factorial(5))
"""
exec(LOC) exec_code()
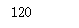
str='Runoob'
print(str[::-1])

str='Runoob'
print(''.join(reversed(str)))
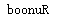
def rotate(input,d):
Lfirst = input[0 : d]
Lsecond = input[d :]
Rfirst = input[0 : len(input)-d]
Rsecond = input[len(input)-d : ]
print( "头部切片翻转 : ", (Lsecond + Lfirst) )
print( "尾部切片翻转 : ", (Rsecond + Rfirst) ) if __name__ == "__main__":
input = 'Runoob'
d=2 # 截取两个字符
rotate(input,d)

def dictionairy():
# 声明字典
key_value ={} # 初始化
key_value[2] = 56
key_value[1] = 2
key_value[5] = 12
key_value[4] = 24
key_value[6] = 18
key_value[3] = 323
print ("按键(key)排序:")
# sorted(key_value) 返回一个迭代器
# 字典按键排序
for i in sorted (key_value) :
print ((i, key_value[i]), end =" ") def main():
# 调用函数
dictionairy() # 主函数
if __name__=="__main__":
main()
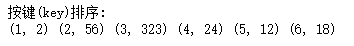
def dictionairy():
# 声明字典
key_value ={}
# 初始化
key_value[2] = 56
key_value[1] = 2
key_value[5] = 12
key_value[4] = 24
key_value[6] = 18
key_value[3] = 323
print ("按值(value)排序:")
print(sorted(key_value.items(), key = lambda kv:(kv[1], kv[0]))) def main():
dictionairy() if __name__=="__main__":
main()

lis = [{ "name" : "Taobao", "age" : 100},
{ "name" : "Runoob", "age" : 7 },
{ "name" : "Google", "age" : 100 },
{ "name" : "Wiki" , "age" : 200 }]
# 通过 age 升序排序
print ("列表通过 age 升序排序: ")
print (sorted(lis, key = lambda i: i['age']) )
print ("\r")
# 先按 age 排序,再按 name 排序
print ("列表通过 age 和 name 排序: ")
print (sorted(lis, key = lambda i: (i['age'], i['name'])) )
print ("\r")
# 按 age 降序排序
print ("列表通过 age 降序排序: ")
print (sorted(lis, key = lambda i: i['age'],reverse=True) )

def returnSum(myDict):
sum = 0
for i in myDict:
sum = sum + myDict[i]
return sum dict = {'a': 100, 'b':200, 'c':300}
print("Sum :", returnSum(dict))
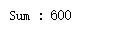
test_dict = {"Runoob" : 1, "Google" : 2, "Taobao" : 3, "Zhihu" : 4}
# 输出原始的字典
print ("字典移除前 : " + str(test_dict))
# 使用 del 移除 Zhihu
del test_dict['Zhihu']
# 输出移除后的字典
print ("字典移除后 : " + str(test_dict))
# 移除没有的 key 会报错
#del test_dict['Baidu']
test_dict = {"Runoob" : 1, "Google" : 2, "Taobao" : 3, "Zhihu" : 4}
# 输出原始的字典
print ("字典移除前 : ")
print(test_dict)
# 使用 del 移除 Zhihu
del test_dict['Zhihu']
# 移除没有的 key 会报错
#del test_dict['Baidu']
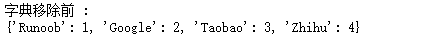
def Merge(dict1, dict2):
return(dict2.update(dict1)) # 两个字典
dict1 = {'a': 10, 'b': 8}
dict2 = {'d': 6, 'c': 4} # 返回 None
print(Merge(dict1, dict2)) # dict2 合并了 dict1
print(dict2)
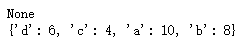
def Merge(dict1, dict2):
res = {**dict1, **dict2}
return res # 两个字典
dict1 = {'a': 10, 'b': 8}
dict2 = {'d': 6, 'c': 4}
dict3 = Merge(dict1, dict2)
print(dict3)
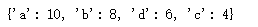
import time a1 = "2019-5-10 23:40:00"
# 先转换为时间数组
timeArray = time.strptime(a1, "%Y-%m-%d %H:%M:%S") # 转换为时间戳
timeStamp = int(time.mktime(timeArray))
print(timeStamp) # 格式转换 - 转为 /
a2 = "2019/5/10 23:40:00"
# 先转换为时间数组,然后转换为其他格式
timeArray = time.strptime(a2, "%Y/%m/%d %H:%M:%S")
otherStyleTime = time.strftime("%Y/%m/%d %H:%M:%S", timeArray)
print(otherStyleTime)

import time
import datetime # 先获得时间数组格式的日期
threeDayAgo = (datetime.datetime.now() - datetime.timedelta(days = 3))
# 转换为时间戳
timeStamp = int(time.mktime(threeDayAgo.timetuple()))
# 转换为其他字符串格式
otherStyleTime = threeDayAgo.strftime("%Y-%m-%d %H:%M:%S")
print(otherStyleTime)

import time
import datetime #给定时间戳
timeStamp = 1557502800
dateArray = datetime.datetime.utcfromtimestamp(timeStamp)
threeDayAgo = dateArray - datetime.timedelta(days = 3)
print(threeDayAgo)
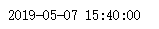
import time # 获得当前时间时间戳
now = int(time.time())
#转换为其他日期格式,如:"%Y-%m-%d %H:%M:%S"
timeArray = time.localtime(now)
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
print(otherStyleTime)

import datetime # 获得当前时间
now = datetime.datetime.now()
# 转换为指定的格式
otherStyleTime = now.strftime("%Y-%m-%d %H:%M:%S")
print(otherStyleTime)
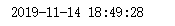
import time timeStamp = 1557502800
timeArray = time.localtime(timeStamp)
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
print(otherStyleTime)

import datetime timeStamp = 1557502800
dateArray = datetime.datetime.utcfromtimestamp(timeStamp)
otherStyleTime = dateArray.strftime("%Y-%m-%d %H:%M:%S")
print(otherStyleTime)
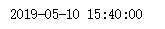
name = "RUNOOB" # 接收用户输入
# name = input("输入你的名字: \n\n") lngth = len(name)
l = "" for x in range(0, lngth):
c = name[x]
c = c.upper() if (c == "A"):
print("..######..\n..#....#..\n..######..", end = " ")
print("\n..#....#..\n..#....#..\n\n") elif (c == "B"):
print("..######..\n..#....#..\n..#####...", end = " ")
print("\n..#....#..\n..######..\n\n") elif (c == "C"):
print("..######..\n..#.......\n..#.......", end = " ")
print("\n..#.......\n..######..\n\n") elif (c == "D"):
print("..#####...\n..#....#..\n..#....#..", end = " ")
print("\n..#....#..\n..#####...\n\n") elif (c == "E"):
print("..######..\n..#.......\n..#####...", end = " ")
print("\n..#.......\n..######..\n\n") elif (c == "F"):
print("..######..\n..#.......\n..#####...", end = " ")
print("\n..#.......\n..#.......\n\n") elif (c == "G"):
print("..######..\n..#.......\n..#.####..", end = " ")
print("\n..#....#..\n..#####...\n\n") elif (c == "H"):
print("..#....#..\n..#....#..\n..######..", end = " ")
print("\n..#....#..\n..#....#..\n\n") elif (c == "I"):
print("..######..\n....##....\n....##....", end = " ")
print("\n....##....\n..######..\n\n") elif (c == "J"):
print("..######..\n....##....\n....##....", end = " ")
print("\n..#.##....\n..####....\n\n") elif (c == "K"):
print("..#...#...\n..#..#....\n..##......", end = " ")
print("\n..#..#....\n..#...#...\n\n") elif (c == "L"):
print("..#.......\n..#.......\n..#.......", end = " ")
print("\n..#.......\n..######..\n\n") elif (c == "M"):
print("..#....#..\n..##..##..\n..#.##.#..", end = " ")
print("\n..#....#..\n..#....#..\n\n") elif (c == "N"):
print("..#....#..\n..##...#..\n..#.#..#..", end = " ")
print("\n..#..#.#..\n..#...##..\n\n") elif (c == "O"):
print("..######..\n..#....#..\n..#....#..", end = " ")
print("\n..#....#..\n..######..\n\n") elif (c == "P"):
print("..######..\n..#....#..\n..######..", end = " ")
print("\n..#.......\n..#.......\n\n") elif (c == "Q"):
print("..######..\n..#....#..\n..#.#..#..", end = " ")
print("\n..#..#.#..\n..######..\n\n") elif (c == "R"):
print("..######..\n..#....#..\n..#.##...", end = " ")
print("\n..#...#...\n..#....#..\n\n") elif (c == "S"):
print("..######..\n..#.......\n..######..", end = " ")
print("\n.......#..\n..######..\n\n") elif (c == "T"):
print("..######..\n....##....\n....##....", end = " ")
print("\n....##....\n....##....\n\n") elif (c == "U"):
print("..#....#..\n..#....#..\n..#....#..", end = " ")
print("\n..#....#..\n..######..\n\n") elif (c == "V"):
print("..#....#..\n..#....#..\n..#....#..", end = " ")
print("\n...#..#...\n....##....\n\n") elif (c == "W"):
print("..#....#..\n..#....#..\n..#.##.#..", end = " ")
print("\n..##..##..\n..#....#..\n\n") elif (c == "X"):
print("..#....#..\n...#..#...\n....##....", end = " ")
print("\n...#..#...\n..#....#..\n\n") elif (c == "Y"):
print("..#....#..\n...#..#...\n....##....", end = " ")
print("\n....##....\n....##....\n\n") elif (c == "Z"):
print("..######..\n......#...\n.....#....", end = " ")
print("\n....#.....\n..######..\n\n") elif (c == " "):
print("..........\n..........\n..........", end = " ")
print("\n..........\n\n") elif (c == "."):
print("----..----\n\n")

吴裕雄--天生自然python编程:实例(2)的更多相关文章
- 吴裕雄--天生自然python编程:实例
# 该实例输出 Hello World! print('Hello World!') # 用户输入数字 num1 = input('输入第一个数字:') num2 = input('输入第二个数字:' ...
- 吴裕雄--天生自然python编程:实例(1)
str = "www.runoob.com" print(str.upper()) # 把所有字符中的小写字母转换成大写字母 print(str.lower()) # 把所有字符中 ...
- 吴裕雄--天生自然python编程:实例(3)
# 返回 x 在 arr 中的索引,如果不存在返回 -1 def binarySearch (arr, l, r, x): # 基本判断 if r >= l: mid = int(l + (r ...
- 吴裕雄--天生自然python编程:正则表达式
re.match函数 re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none. 函数语法: re.match(pattern, string, ...
- 吴裕雄--天生自然python编程:turtle模块绘图(3)
turtle(海龟)是Python重要的标准库之一,它能够进行基本的图形绘制.turtle图形绘制的概念诞生于1969年,成功应用于LOGO编程语言. turtle库绘制图形有一个基本框架:一个小海龟 ...
- 吴裕雄--天生自然python编程:turtle模块绘图(1)
Turtle库是Python语言中一个很流行的绘制图像的函数库,想象一个小乌龟,在一个横轴为x.纵轴为y的坐标系原点,(0,0)位置开始,它根据一组函数指令的控制,在这个平面坐标系中移动,从而在它爬行 ...
- 吴裕雄--天生自然python编程:pycharm常用快捷键问题
最近在使用pycharm的时候发现不能正常使用ctrl+c/v进行复制粘贴,也无法使用tab键对大段代码进行整体缩进.后来发现是因为安装了vim插件的问题,在setting里找到vim插件,取消勾选即 ...
- 吴裕雄--天生自然python编程:turtle模块绘图(4)
import turtle bob = turtle.Turtle() for i in range(1,5): bob.fd(100) bob.lt(90) turtle.mainloop() im ...
- 吴裕雄--天生自然python编程:turtle模块绘图(2)
#彩色螺旋线 import turtle import time turtle.pensize(2) turtle.bgcolor("black") colors = [" ...
随机推荐
- Dynamics CRM - 通过 C# Plugin 来 abandon Business Process Flow
需求说明: 当一个 Entity 存在 Business Process Process 时,有时我们需要改变其状态,在之前写的博客有讲了可以通过 JavaScript 来实现,本篇就来讲一下如何通过 ...
- \_\_module\_\_和\_\_class\_\_
目录 __module__和__class__ 一.__module__ 二.通过字符导入模块 三.__class__ __module__和__class__ # lib/aa.py class C ...
- Django_HTML
一.web开发之HTML 1.1 HTML相关基础 快速生成html的模版方法: 在visual code的新建html文件中输入:!然后tab回车就会出现HTML的模版 双标签: <p> ...
- MCMC学习
看了这个文档 结合随机矩阵的知识, 更清楚了一点. https://www.cnblogs.com/xbinworld/p/4266146.html
- Tomcat远程debug配置
当我们需要定位生产环境问题,而日志又不清晰的情况下,我们可以借助Tomcat提供的远程调试,设置如下: // Linxu系统: apach/bin/startup.sh开始处中增加如下内容: decl ...
- Codeforces 1292A/1293C - NEKO's Maze Game
题目大意: 有一个2*n的图 NEKO#ΦωΦ要带领mimi们从(1,1)的点走到(2,n)的点 每次会操作一个点,从可以通过到不可以通过,不可以通过到可以通过 每操作一次要回答一次NEKO#ΦωΦ能 ...
- ZJNU 1153 - 找单词——中级
状态转移b[i]记录价值为i的单词种类数d[j+k*i]+=b[j] , k<=a[i]&&j+k*i<=50表示价值为j+k*i的单词可以由价值为j的单词加上k个i字母转 ...
- 【shell基础】
Ctrl+R 搜索之前的命令 Ctrl+D 退出 Ctrl+A 移动到行首 Ctrl+E 移动到行尾 Ctrl+U 删除光标前的内容 Ctrl+K 删除光标后的内容 Ctrl+S 锁频 Ctrl+Q ...
- [LC] 1048. Longest String Chain
Given a list of words, each word consists of English lowercase letters. Let's say word1 is a predece ...
- tap点击一次,内部程序执行两次,多次
调试过程发现,使用 $(document).on('tap', '.children2', function () { //内部程序 }) 点击children2的时候,程序在里面执行了两次.百度得到 ...