入门大数据---SparkSQL联结操作
一、 数据准备
本文主要介绍 Spark SQL 的多表连接,需要预先准备测试数据。分别创建员工和部门的 Datafame,并注册为临时视图,代码如下:
val spark = SparkSession.builder().appName("aggregations").master("local[2]").getOrCreate()
val empDF = spark.read.json("/usr/file/json/emp.json")
empDF.createOrReplaceTempView("emp")
val deptDF = spark.read.json("/usr/file/json/dept.json")
deptDF.createOrReplaceTempView("dept")
两表的主要字段如下:
emp 员工表
|-- ENAME: 员工姓名
|-- DEPTNO: 部门编号
|-- EMPNO: 员工编号
|-- HIREDATE: 入职时间
|-- JOB: 职务
|-- MGR: 上级编号
|-- SAL: 薪资
|-- COMM: 奖金
dept 部门表
|-- DEPTNO: 部门编号
|-- DNAME: 部门名称
|-- LOC: 部门所在城市
注:emp.json,dept.json 可以在本仓库的resources 目录进行下载。
二、连接类型
Spark 中支持多种连接类型:
- Inner Join : 内连接;
- Full Outer Join : 全外连接;
- Left Outer Join : 左外连接;
- Right Outer Join : 右外连接;
- Left Semi Join : 左半连接;
- Left Anti Join : 左反连接;
- Natural Join : 自然连接;
- Cross (or Cartesian) Join : 交叉 (或笛卡尔) 连接。
其中内,外连接,笛卡尔积均与普通关系型数据库中的相同,如下图所示:
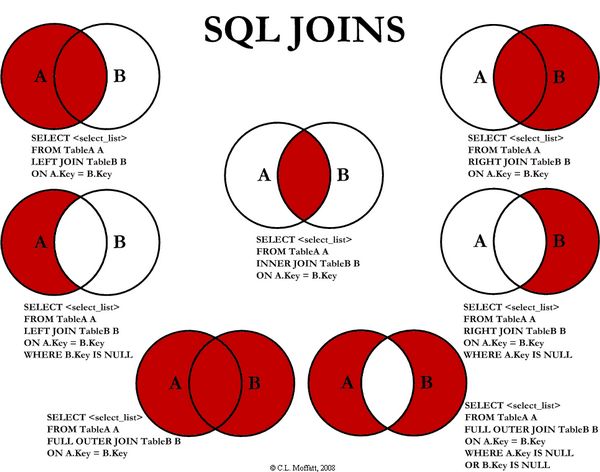
这里解释一下左半连接和左反连接,这两个连接等价于关系型数据库中的 IN 和 NOT IN 字句:
-- LEFT SEMI JOIN
SELECT * FROM emp LEFT SEMI JOIN dept ON emp.deptno = dept.deptno
-- 等价于如下的 IN 语句
SELECT * FROM emp WHERE deptno IN (SELECT deptno FROM dept)
-- LEFT ANTI JOIN
SELECT * FROM emp LEFT ANTI JOIN dept ON emp.deptno = dept.deptno
-- 等价于如下的 IN 语句
SELECT * FROM emp WHERE deptno NOT IN (SELECT deptno FROM dept)
所有连接类型的示例代码如下:
2.1 INNER JOIN
// 1.定义连接表达式
val joinExpression = empDF.col("deptno") === deptDF.col("deptno")
// 2.连接查询
empDF.join(deptDF,joinExpression).select("ename","dname").show()
// 等价 SQL 如下:
spark.sql("SELECT ename,dname FROM emp JOIN dept ON emp.deptno = dept.deptno").show()
2.2 FULL OUTER JOIN
empDF.join(deptDF, joinExpression, "outer").show()
spark.sql("SELECT * FROM emp FULL OUTER JOIN dept ON emp.deptno = dept.deptno").show()
2.3 LEFT OUTER JOIN
empDF.join(deptDF, joinExpression, "left_outer").show()
spark.sql("SELECT * FROM emp LEFT OUTER JOIN dept ON emp.deptno = dept.deptno").show()
2.4 RIGHT OUTER JOIN
empDF.join(deptDF, joinExpression, "right_outer").show()
spark.sql("SELECT * FROM emp RIGHT OUTER JOIN dept ON emp.deptno = dept.deptno").show()
2.5 LEFT SEMI JOIN
empDF.join(deptDF, joinExpression, "left_semi").show()
spark.sql("SELECT * FROM emp LEFT SEMI JOIN dept ON emp.deptno = dept.deptno").show()
2.6 LEFT ANTI JOIN
empDF.join(deptDF, joinExpression, "left_anti").show()
spark.sql("SELECT * FROM emp LEFT ANTI JOIN dept ON emp.deptno = dept.deptno").show()
2.7 CROSS JOIN
empDF.join(deptDF, joinExpression, "cross").show()
spark.sql("SELECT * FROM emp CROSS JOIN dept ON emp.deptno = dept.deptno").show()
2.8 NATURAL JOIN
自然连接是在两张表中寻找那些数据类型和列名都相同的字段,然后自动地将他们连接起来,并返回所有符合条件的结果。
spark.sql("SELECT * FROM emp NATURAL JOIN dept").show()
以下是一个自然连接的查询结果,程序自动推断出使用两张表都存在的 dept 列进行连接,其实际等价于:
spark.sql("SELECT * FROM emp JOIN dept ON emp.deptno = dept.deptno").show()
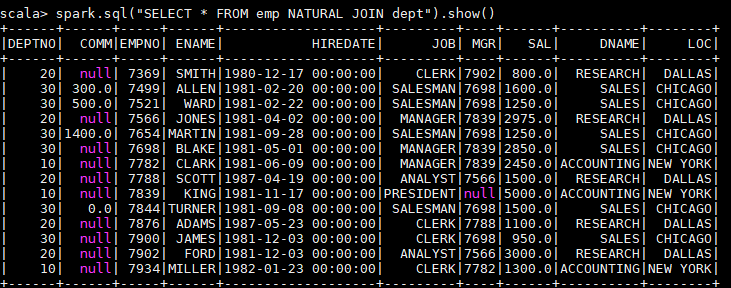
由于自然连接常常会产生不可预期的结果,所以并不推荐使用。
三、连接的执行
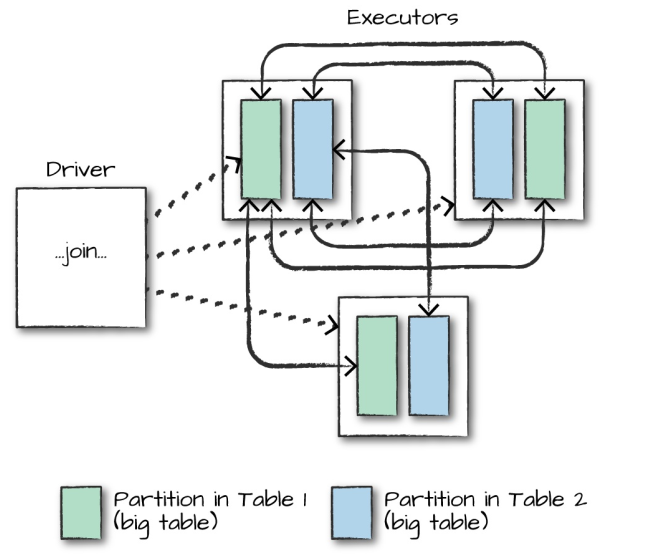
在对大表与大表之间进行连接操作时,通常都会触发 Shuffle Join,两表的所有分区节点会进行 All-to-All 的通讯,这种查询通常比较昂贵,会对网络 IO 会造成比较大的负担。
而对于大表和小表的连接操作,Spark 会在一定程度上进行优化,如果小表的数据量小于 Worker Node 的内存空间,Spark 会考虑将小表的数据广播到每一个 Worker Node,在每个工作节点内部执行连接计算,这可以降低网络的 IO,但会加大每个 Worker Node 的 CPU 负担。
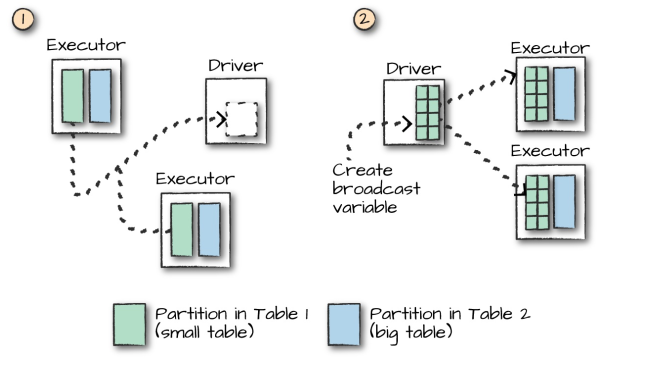
是否采用广播方式进行 Join 取决于程序内部对小表的判断,如果想明确使用广播方式进行 Join,则可以在 DataFrame API 中使用 broadcast 方法指定需要广播的小表:
empDF.join(broadcast(deptDF), joinExpression).show()
参考资料
- Matei Zaharia, Bill Chambers . Spark: The Definitive Guide[M] . 2018-02
入门大数据---SparkSQL联结操作的更多相关文章
- 入门大数据---SparkSQL外部数据源
一.简介 1.1 多数据源支持 Spark 支持以下六个核心数据源,同时 Spark 社区还提供了多达上百种数据源的读取方式,能够满足绝大部分使用场景. CSV JSON Parquet ORC JD ...
- 入门大数据---SparkSQL常用聚合函数
一.简单聚合 1.1 数据准备 // 需要导入 spark sql 内置的函数包 import org.apache.spark.sql.functions._ val spark = SparkSe ...
- 入门大数据---MapReduce-API操作
一.环境 Hadoop部署环境: Centos3.10.0-327.el7.x86_64 Hadoop2.6.5 Java1.8.0_221 代码运行环境: Windows 10 Hadoop 2.6 ...
- 入门大数据---Spark整体复习
一. Spark简介 1.1 前言 Apache Spark是一个基于内存的计算框架,它是Scala语言开发的,而且提供了一站式解决方案,提供了包括内存计算(Spark Core),流式计算(Spar ...
- 入门大数据---Spark_RDD
一.RDD简介 RDD 全称为 Resilient Distributed Datasets,是 Spark 最基本的数据抽象,它是只读的.分区记录的集合,支持并行操作,可以由外部数据集或其他 RDD ...
- 入门大数据---Flink学习总括
第一节 初识 Flink 在数据激增的时代,催生出了一批计算框架.最早期比较流行的有MapReduce,然后有Spark,直到现在越来越多的公司采用Flink处理.Flink相对前两个框架真正做到了高 ...
- Dapper学习(四)之Dapper Plus的大数据量的操作
这篇文章主要讲 Dapper Plus,它使用用来操作大数量的一些操作的.比如插入1000条,或者10000条的数据时,再使用Dapper的Execute方法,就会比较慢了.这时候,可以使用Dappe ...
- 入门大数据---Spark_Streaming整合Flume
一.简介 Apache Flume 是一个分布式,高可用的数据收集系统,可以从不同的数据源收集数据,经过聚合后发送到分布式计算框架或者存储系统中.Spark Straming 提供了以下两种方式用于 ...
- 入门大数据---安装ClouderaManager,CDH和Impala,Hue,oozie等服务
1.要求和支持的版本 (PS:我使用的环境,都用加粗标识了.) 1.1 支持的操作系统版本 操作系统 版本 RHEL/CentOS/OL with RHCK kernel 7.6, 7.5, 7.4, ...
随机推荐
- 通过jquery实现tab切换
//css代码 *{ margin: 0; padding: 0; } #box{ margin: 0 auto; width: 800px; border: 5px solid #000000; o ...
- jchdl - RTL Data Types
https://mp.weixin.qq.com/s/hWYW1Bn---WhpwVu2e98qA 一. Bit 类结构如下: 主要属性: value: bit的值,只支持0,1, ...
- Java实现蓝桥杯墓地雕塑
墓地雕塑 问题描述 在一个周长为10000的圆上等距分布着n个雕塑.现在又有m个新雕塑加入(位置可以随意放), 希望所有n+m个雕塑在圆周上均匀分布.这就需要移动其中一些原有的雕塑.要求n个雕塑移动的 ...
- CSDN账号被冻结了怎么办
CSDN可能因为你的博客里有一些网站链接给你判断为恶意推广广告,冻结, 或者和我一样,在评论区刷屏被冻结, 联系客服即可,向客服提供你的绑定邮箱或绑定手机号,或博客id,客服会给你解冻 PS: 找不到 ...
- java实现最大连续和问题
/* 10 5 -3 12 -31 15 22 -7 6 -8 -9 10 .... 暴力:O(n^3) 分治:[ mid ) 三种情况求最大 基线法: O(n) 2个数组: 从左到本位:出现的最大累 ...
- java实现第六届蓝桥杯表格计算
表格计算 某次无聊中, atm 发现了一个很老的程序.这个程序的功能类似于 Excel ,它对一个表格进行操作. 不妨设表格有 n 行,每行有 m 个格子. 每个格子的内容可以是一个正整数,也可以是一 ...
- Linux ACL权限查看与设定
getfacl 文件名,可以查看文件的acl权限 setfacl [选项] 文件名,可以设定文件的acl权限,例如:setfacl -m u:boduo:rx /project/ 这时候,创建了bod ...
- 欧几里得算法求最大公约数-《Algorithms Fourth Edition》第1章
最大公约数(Greatest Common Divisor, GCD),是指2个或N个整数共有约数中最大的一个.a,b的最大公约数记为(a, b).相对应的是最小公倍数,记为[a, b]. 在求最大公 ...
- hibernate 用注解方式生成uuid方法
//配置uuid,本来jpa是不支持uuid的,但借用hibernate的方法可以实现. @GeneratedValue(generator = "uuid") @Generate ...
- Android下的缓存策略
Android下的缓存策略 内存缓存 常用的内存缓存是软引用和弱引用,大部分的使用方式是Android提供的LRUCache缓存策略,本质是个LinkedHashMap(会根据使用次数进行排序) 磁盘 ...