spark streaming基本概念一
在学习spark streaming时,建议先学习和掌握RDD。spark streaming无非是针对流式数据处理这个场景,在RDD基础上做了一层封装,简化流式数据处理过程。
spark streaming 引入一些新的概念和方法,本文将介绍这方面的知识。主要包括以下几点:
- 初始化流上下文
- Discretized Streams离散数据流
- Input DStreams and Receivers
- Transformations on DStreams
- Output Operations on DStreams
- DataFrame and SQL Operations
Basic Concepts
Initializing StreamingContext
SparkConf conf = new SparkConf().setAppName(appName).setMaster(master);
JavaStreamingContext ssc = new JavaStreamingContext(conf, new Duration(1000));
./bin/spark-submit \
--class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... # other options
<application-jar> \
[application-arguments]
- Run on a Spark standalone cluster in client deploy mode
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://207.184.161.138:7077 \
--executor-memory 20G \
--total-executor-cores 100 \
/path/to/examples.jar \
1000
Only one StreamingContext can be active in a JVM at the same time.**==在虚拟机中一次只能运行一个StreamingContext.
stop() on StreamingContext also stops the SparkContext. To stop only the StreamingContext, set the optional parameter of stop() called stopSparkContext to false.
stop()默认停止StreamingContext时同时停止SparkContext。通过参数可设置只停止StreamingContext。
A SparkContext can be re-used to create multiple StreamingContexts, as long as the previous StreamingContext is stopped (without stopping the SparkContext) before the next StreamingContext is created.
SparkContext 可以创建多个StreamingContexts,只要前一个StreamingContext已停止。
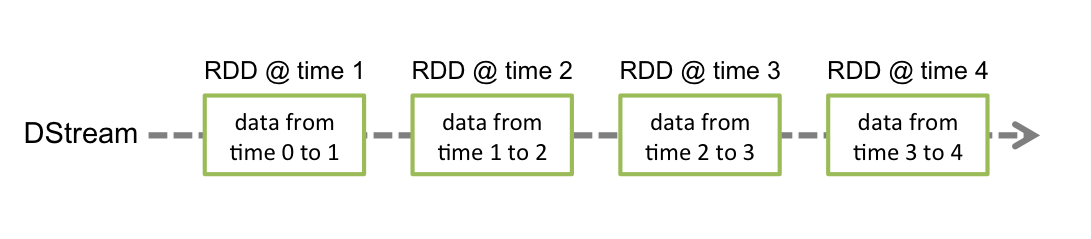
Discretized Streams (DStreams)
a DStream is represented by a continuous series of RDDs, which is Spark’s abstraction of an immutable, distributed dataset.
DStream离散数据流是不可变的、分布式数据集的抽象,它代表一系列连续的RDDs.
Input DStreams and Receivers
两种数据源
- 基本数据源:文件、socket
- 高级数据源: Kafka, Flume, Kinesis
But note that a Spark worker/executor is a long-running task, hence it occupies one of the cores allocated to the Spark Streaming application. Therefore, it is important to remember that a Spark Streaming application needs to be allocated enough cores (or threads, if running locally) to process the received data, as well as to run the receiver(s).
spark的worker是长期运行的任务,需要占据cpu的一个核。所以在集群上使用时,需要有足够的多cpu核,在本地运行时,需要足够多的线程。所以spark对CPU核数、内存有要求。
- 注意事项
- when running locally, always use “local[n]” as the master URL, where n > number of receivers to run (see Spark Properties for information on how to set the master). 运行本地模式时,n > 接收者数量。
- Extending the logic to running on a cluster, the number of cores allocated to the Spark Streaming application must be more than the number of receivers. Otherwise the system will receive data, but not be able to process it.在集群运行时,分配给spark的核数>接收者数量,否则系统只能接收数据,不能处理数据。
Receiver Reliability
两类接收者:
- 可靠接收者:数据源允许确认转换的数据。
- 不可靠接收者
Transformations on DStreams
A few of these transformations are worth discussing in more detail.
UpdateStateByKey Operation
在更新的时候可以保持任意的状态。
have to do two steps.
- Define the state - The state can be an arbitrary data type.
- Define the state update function - Specify with a function how to update the state using the previous state and the new values from an input stream.
Transform Operation
arbitrary RDD-to-RDD functions to be applied on a DStream.在DStream中可以使用任意的RDD-to-RDD函数。因为DStream本身是对RDD的封装,所以RDD的转换,DStream都支持。
This allows you to do time-varying RDD operations, that is, RDD operations, number of partitions, broadcast variables, etc. can be changed between batches. 允许执行基于时间变化的RDD操作,比如在批处理中 操作RDD,分组的数量、广播变量等。
Window Operations
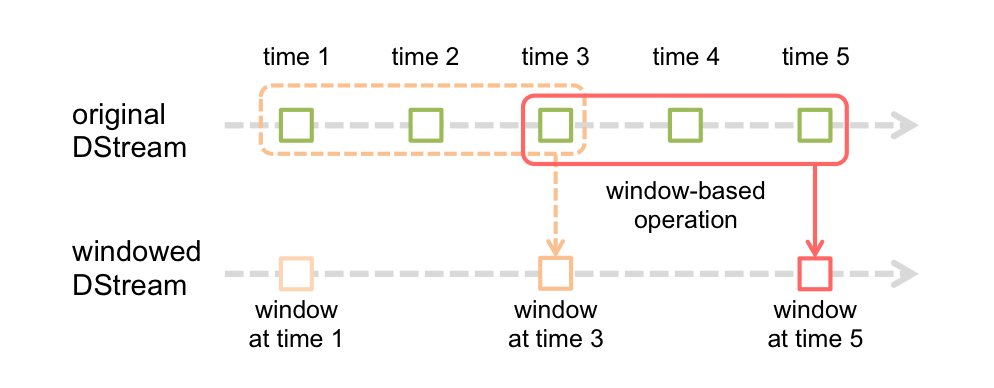
window operation needs to specify two parameters.
- window length - The duration of the window (3 in the figure).
- sliding interval - The interval at which the window operation is performed (2 in the figure).
Join Operations
- Stream-stream joins
- Stream-dataset joins
Output Operations on DStreams
Output operations allow DStream’s data to be pushed out to external systems like a database or a file systems.输出操作运行数据流推送到外部系统,比如数据库或者文件。
Design Patterns for using foreachRDD
dstream.foreachRDD(rdd -> {
rdd.foreachPartition(partitionOfRecords -> {
// ConnectionPool is a static, lazily initialized pool of connections
Connection connection = ConnectionPool.getConnection();
while (partitionOfRecords.hasNext()) {
connection.send(partitionOfRecords.next());
}
ConnectionPool.returnConnection(connection); // return to the pool for future reuse
});
});
Other points to remember:
DStreams are executed lazily by the output operations, just like RDDs are lazily executed by RDD actions. Specifically, RDD actions inside the DStream output operations force the processing of the received data. Hence, if your application does not have any output operation, or has output operations like dstream.foreachRDD() without any RDD action inside them, then nothing will get executed. The system will simply receive the data and discard it.数据流根据输出操作进行延迟处理。所以必须要有输出操作或者 在forechRDD()中有RDD的动作。
By default, output operations are executed one-at-a-time. And they are executed in the order they are defined in the application.输出操作一次一个。
DataFrame and SQL Operations
- Dataset is a new interface added in Spark 1.6 that provides the benefits of RDDs (strong typing, ability to use powerful lambda functions) with the benefits of Spark SQL’s optimized execution engine. A Dataset can be constructed from JVM objects and then manipulated using functional transformations (map, flatMap, filter, etc.).
DateSet吸收了RDD的优点,和sparksql优化执行引擎的好处。通过JVM Objects构造Dataset。
SparkSession
SparkSession spark = SparkSession
.builder()
.appName("Java Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate();
- DataFrame: Untyped Dataset Operations (aka DataFrame Operations)
无类型的Dataset
Dataset<Row> sqlDF = spark.sql("SELECT * FROM people");
Each RDD is converted to a DataFrame, registered as a temporary table and then queried using SQL.将RDD转换成DataFrame,注册一个临时表,然后使用sql查询。
参考文献
spark streaming基本概念一的更多相关文章
- Spark Streaming核心概念与编程
Spark Streaming核心概念与编程 1. 核心概念 StreamingContext Create StreamingContext import org.apache.spark._ im ...
- Spark Streaming基础概念
为了更好地理解Spark Streaming 子框架的处理机制,必须得要自己弄清楚这些最基本概念. 1.离散流(Discretized Stream,DStream):这是Spark Streamin ...
- 通过案例对 spark streaming 透彻理解三板斧之二:spark streaming运行机制
本期内容: 1. Spark Streaming架构 2. Spark Streaming运行机制 Spark大数据分析框架的核心部件: spark Core.spark Streaming流计算. ...
- Spark Streaming笔记
Spark Streaming学习笔记 liunx系统的习惯创建hadoop用户在hadoop根目录(/home/hadoop)上创建如下目录app 存放所有软件的安装目录 app/tmp 存放临时文 ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十之铭文升级版
铭文一级: 第八章:Spark Streaming进阶与案例实战 updateStateByKey算子需求:统计到目前为止累积出现的单词的个数(需要保持住以前的状态) java.lang.Illega ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记九之铭文升级版
铭文一级: 核心概念:StreamingContext def this(sparkContext: SparkContext, batchDuration: Duration) = { this(s ...
- 大数据开发实战:Spark Streaming流计算开发
1.背景介绍 Storm以及离线数据平台的MapReduce和Hive构成了Hadoop生态对实时和离线数据处理的一套完整处理解决方案.除了此套解决方案之外,还有一种非常流行的而且完整的离线和 实时数 ...
- Spark Streaming和Kafka集成深入浅出
写在前面 本文主要介绍Spark Streaming基本概念.kafka集成.Offset管理 本文主要介绍Spark Streaming基本概念.kafka集成.Offset管理 一.概述 Spar ...
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
随机推荐
- 第10课.c++的新成员
1.动态内存分配 a.c++中通过new关键字进行动态内存申请 b.c++中的动态内存申请是基于类型进行的 c.delete关键字用于内存释放 2.new关键字与malloc函数的区别 a.new关键 ...
- 看kubelet的日志 + Kubeadm安装Kubernetes环境
1.通过journalctl看日志 journalctl -xeu kubelet > a参考:https://www.cnblogs.com/ericnie/p/7749588.html
- 2019牛客暑期多校训练营(第六场)-D Move
题目链接:https://ac.nowcoder.com/acm/contest/886/D 题意:给n个物品,每个物品有一个体积值,K个箱子,问箱子的最小体积为多少可将物品全部装下. 思路:比赛时一 ...
- MySQL优化心得
一打开科技类论坛,最常看到的文章主题就是MySQL性能优化了,为什么要优化呢? 因为: 数据库出现瓶颈,系统的吞吐量出现访问速度慢 随着应用程序的运行,数据库的中的数据会越来越多,处理时间变长 数据读 ...
- JS中的迭代
for each...in 使用一个变量迭代一个对象的所有属性值.对于每一个属性值,有一个指定的语句块被执行. 作为ECMA-357(E4X)标准的一部分,for each...in语句已被废弃,E4 ...
- Go语言Mac、Linux、Windows 下交叉编译
在很多时候,由于开发的方便,会有这样的场景出现,使用Mac开发或使用Windows开发,需要编译成Linux系统的执行文件,那么如何做到?Go语言提供了非常方便的命令行操作,即可实现. 1.Mac下编 ...
- python商城项目总结
项目概括 本项目用于针对Django框架的练习,主要分为前端和后端两部分.前端负责用户注册.登录.商品展示以及添加购物车和显示订单列表的功能:后端负责会员信息.商品类别.商品信息的增删改查以及订单状态 ...
- Tensorflow加载预训练模型和保存模型
转载自:https://blog.csdn.net/huachao1001/article/details/78501928 使用tensorflow过程中,训练结束后我们需要用到模型文件.有时候,我 ...
- kubernetes dashboard访问用户添加权限控制
前面我们在kubernetes dashboard 升级之路一文中成功的将Dashboard升级到最新版本了,增加了身份认证功能,之前为了方便增加了一个admin用户,然后授予了cluster-adm ...
- AI面试必备/深度学习100问1-50题答案解析
AI面试必备/深度学习100问1-50题答案解析 2018年09月04日 15:42:07 刀客123 阅读数 2020更多 分类专栏: 机器学习 转载:https://blog.csdn.net ...