Optimization Algorithms
1. Stochastic Gradient Descent
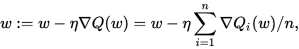
2. SGD With Momentum
Stochastic gradient descent with momentum remembers the update Δ w at each iteration, and determines the next update as a linear combination of the gradient and the previous update:
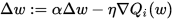
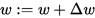

Unlike in classical stochastic gradient descent, it tends to keep traveling in the same direction, preventing oscillations.
3. RMSProp
RMSProp (for Root Mean Square Propagation) is also a method in which the learning rate is adapted for each of the parameters. The idea is to divide the learning rate for a weight by a running average of the magnitudes of recent gradients for that weight. So, first the running average is calculated in terms of means square,
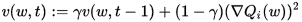
where, 
And the parameters are updated as,
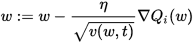
RMSProp has shown excellent adaptation of learning rate in different applications. RMSProp can be seen as a generalization of Rprop and is capable to work with mini-batches as well opposed to only full-batches.
4. The Adam Algorithm
Adam (short for Adaptive Moment Estimation) is an update to the RMSProp optimizer. In this optimization algorithm, running averages of both the gradients and the second moments of the gradients are used. Given parameters 




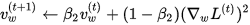
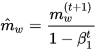
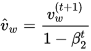

where 


参考链接:Wikipedia。
Optimization Algorithms的更多相关文章
- (转) An overview of gradient descent optimization algorithms
An overview of gradient descent optimization algorithms Table of contents: Gradient descent variants ...
- An overview of gradient descent optimization algorithms
原文地址:An overview of gradient descent optimization algorithms An overview of gradient descent optimiz ...
- 课程二(Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization),第二周(Optimization algorithms) —— 2.Programming assignments:Optimization
Optimization Welcome to the optimization's programming assignment of the hyper-parameters tuning spe ...
- 优化算法动画演示Alec Radford's animations for optimization algorithms
Alec Radford has created some great animations comparing optimization algorithms SGD, Momentum, NAG, ...
- [C2W2] Improving Deep Neural Networks : Optimization algorithms
第二周:优化算法(Optimization algorithms) Mini-batch 梯度下降(Mini-batch gradient descent) 本周将学习优化算法,这能让你的神经网络运行 ...
- 【论文翻译】An overiview of gradient descent optimization algorithms
这篇论文最早是一篇2016年1月16日发表在Sebastian Ruder的博客.本文主要工作是对这篇论文与李宏毅课程相关的核心部分进行翻译. 论文全文翻译: An overview of gradi ...
- Coursera Deep Learning 2 Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization - week2, Optimization algorithms
Gradient descent Batch Gradient Decent, Mini-batch gradient descent, Stochastic gradient descent 还有很 ...
- An overview of gradient descent optimization algorithms (更新到Adam)
Momentum:解快了收敛速度,同时也减弱了SGD的波动 NAG: 减速了Momentum更新参数太快 Adagrad: 出现频率较低参数采用较大的更新,对于出现频率较高的参数采用较小的,不共用一个 ...
- 最佳化常用测试函数 Optimization Test functions
http://www.sfu.ca/~ssurjano/optimization.html The functions listed below are some of the common func ...
随机推荐
- C#大文件流式压缩加解密
* * , CancellationToken token=default) { try { FileStream zipStream = new FileStream(writeFile, File ...
- 安装nova
在控制节点上执行 controllerHost='controller' controllerIP='172.31.240.49' MYSQL_PASSWD='m4r!adbOP' RABBIT_PA ...
- 可视化,matplotlib,seaborn,plotly,pyecharts等等
画频率直方图 import pandas as pd import matplotlib.pyplot as plt Series.value_counts().plot.bar() plt.show ...
- layui 第三方组件 eleTree 树组件 树形选择器
使用 JS位置 ,layui/lay/modules/eleTree.js:CSS位置 ,layui/css/modules/eleTree/eleTree.css: ## 下面应用即可页面css引用 ...
- 学习笔记:CentOS7学习之十三(1):硬盘介绍
1. SAS-SATA-SSD-SCSI-IDE硬盘讲解 1.1 常见硬盘类型: SAS硬盘:SAS(Serial Attached SCSI),串行连接SCSI接口,串行连接小型计算机系统接口.SA ...
- Django2.2 数据库的模块model学习笔记
一.前言 为什么选用Django2.2,因为从2019年下半年起Django2.2逐渐成为长期支持版本,官网也有数据,所以当然选用维护时间长的版本 二.models的建立 Django的models也 ...
- TestNG使用教程详解(接口测试用例编写与断言)
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/sinat_34766121/artic ...
- LeetCode面试常见100题( TOP 100 Liked Questions)
LeetCode面试常见100题( TOP 100 Liked Questions) 置顶 2018年07月16日 11:25:22 lanyu_01 阅读数 9704更多 分类专栏: 面试编程题真题 ...
- 动画方案 Lottie 学习(二)之实战
代码 $('.success-info-title').append('<p class="normal_finish" id="normal_finish_ani ...
- SSD训练网络参数计算
一个预测层的网络结构如下所示: 可以看到,是由三个分支组成的,分别是"PriorBox"层,以及conf.loc的预测层,其中,conf与loc的预测层的参数是由PriorBox的 ...