本地Pycharm将spark程序发送到远端spark集群进行处理
前言
最近在搞hadoop+spark+python,所以就搭建了一个本地的hadoop环境,基础环境搭建地址hadoop2.7.7 分布式集群安装与配置,spark集群安装并集成到hadoop集群,没有配置的朋友可以参考文章搞一搞.
本篇博客主要说明,如何通过pycharm将程序发送到远端spark集群上进行操作处理.
注意:本地环境与远端的集群必须可以互相通信(建议配置内网虚拟机,同一网段).不然的话本地程序在接收spark集群发来的数据会报连接超时.如果本地与远端不在同一网段,这篇博客可能无法给你解决问题,仅供参考
说明
本地环境:指本人开发环境,即pycharm运行的电脑
远端集群:指服务端spark集群
Python环境:本地与远端python相同 Python3.5.6(不知道版本不同是否会有问题)
配置流程
配置本地环境spark
将远端集群中master服务器上的spark打包,并复制到本地环境中
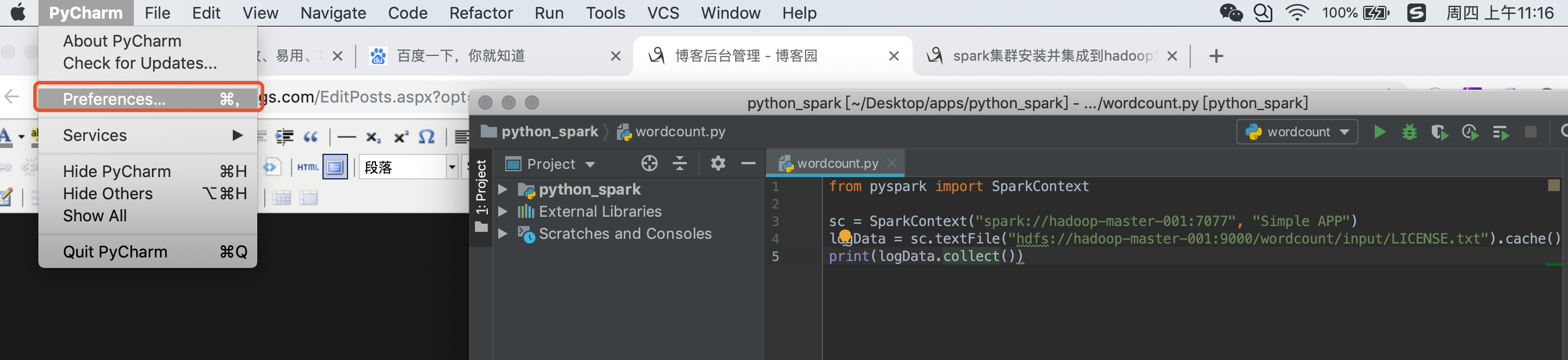
配置pycharm
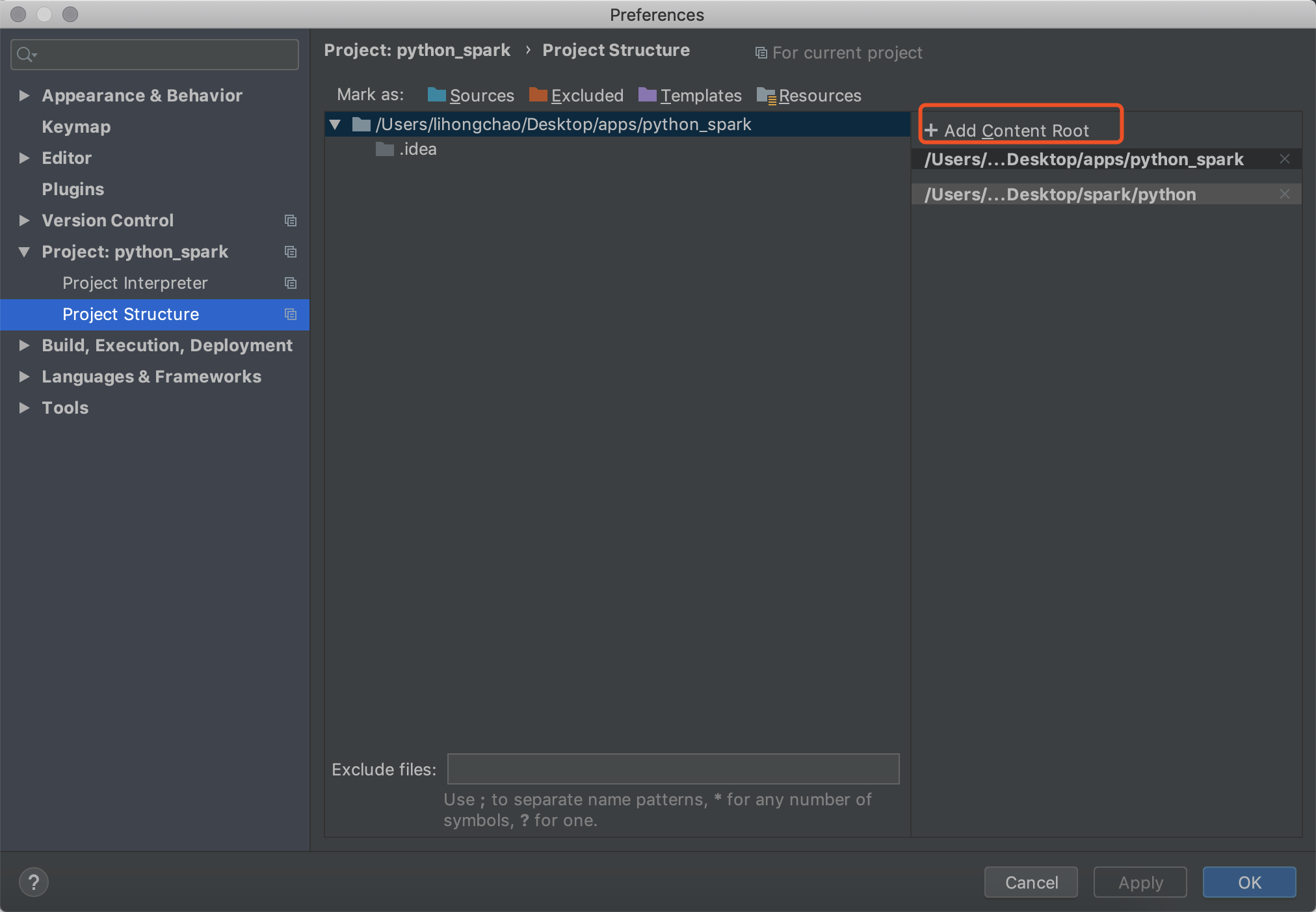
添加新的路径
新的路径地址是你本地spark路径下的python文件夹
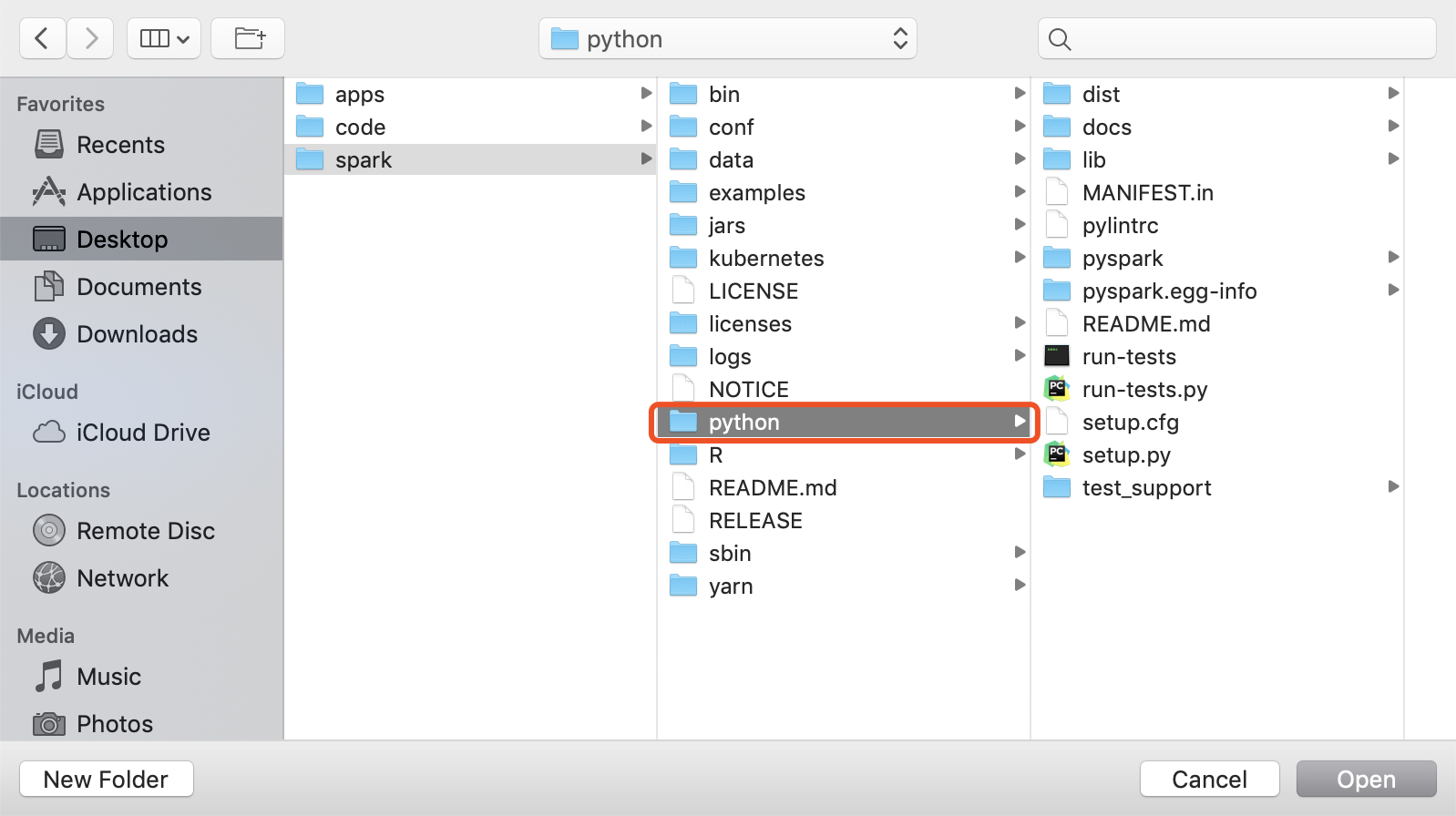
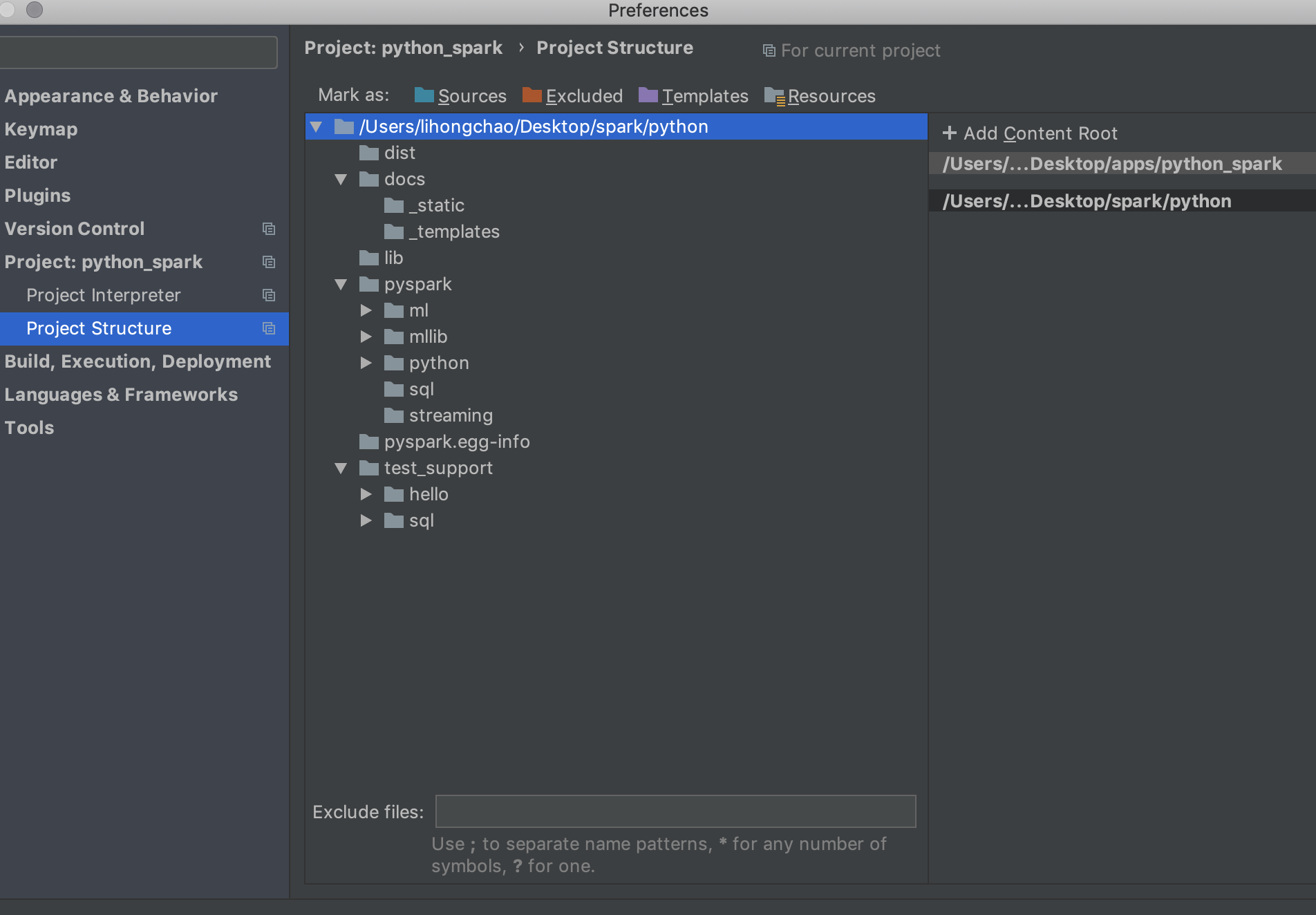
指定这个路径后,我们在编写程序的时候导入SparkContext才不会报错
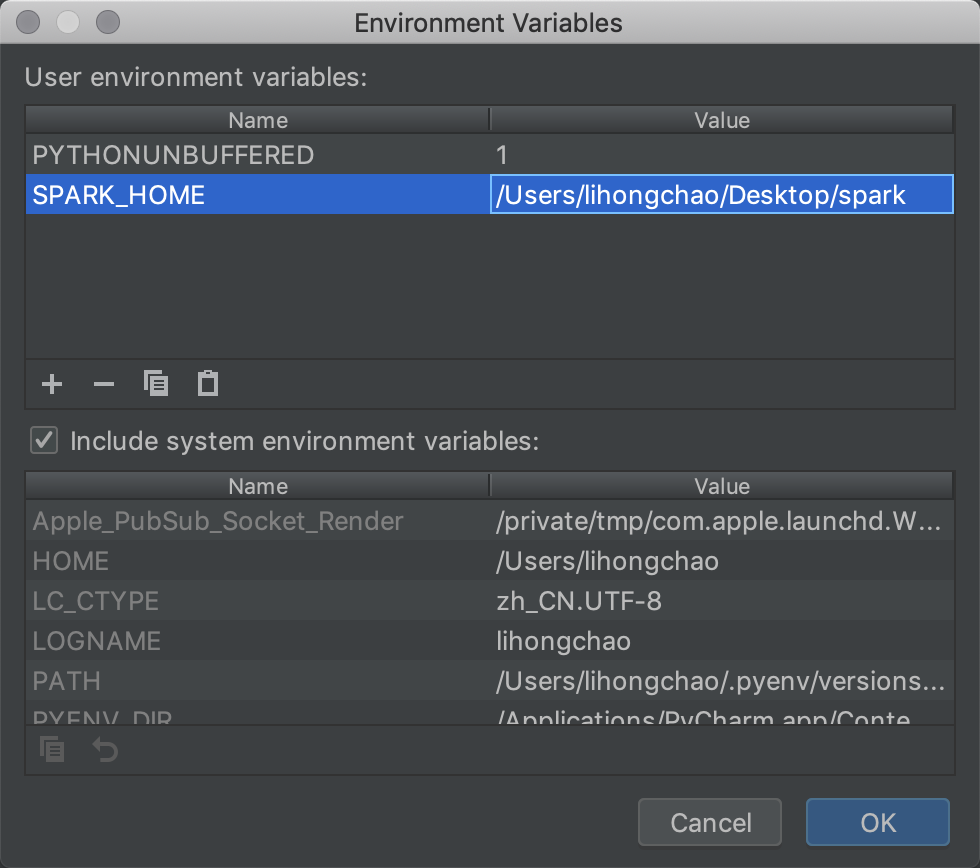
配置环境变量
新建一个文件,配置Edit Configurations
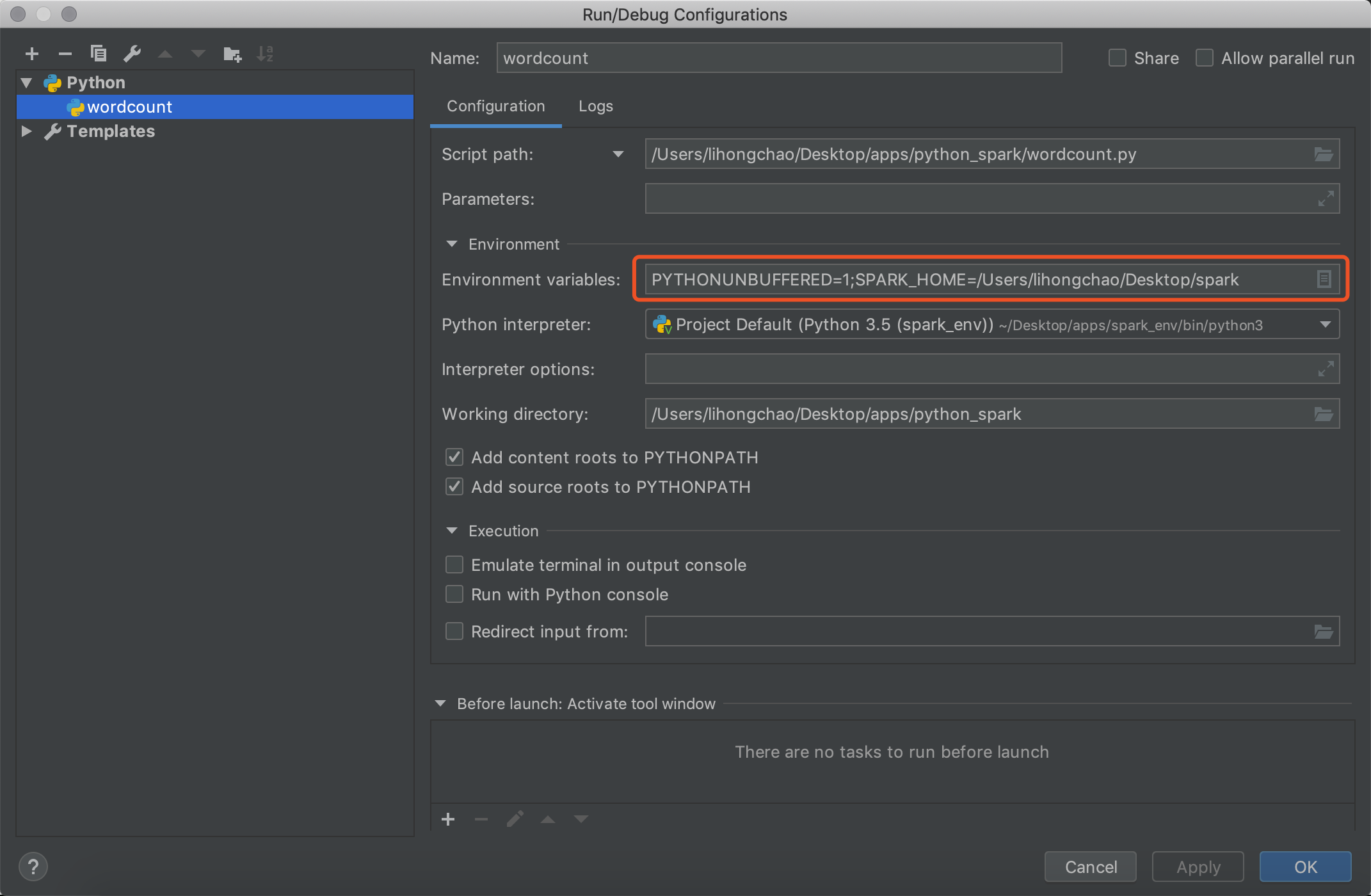
上图红框中是我已经配置好的,添加SPARK_HOME变量
Value表示你本地spark的绝对路径
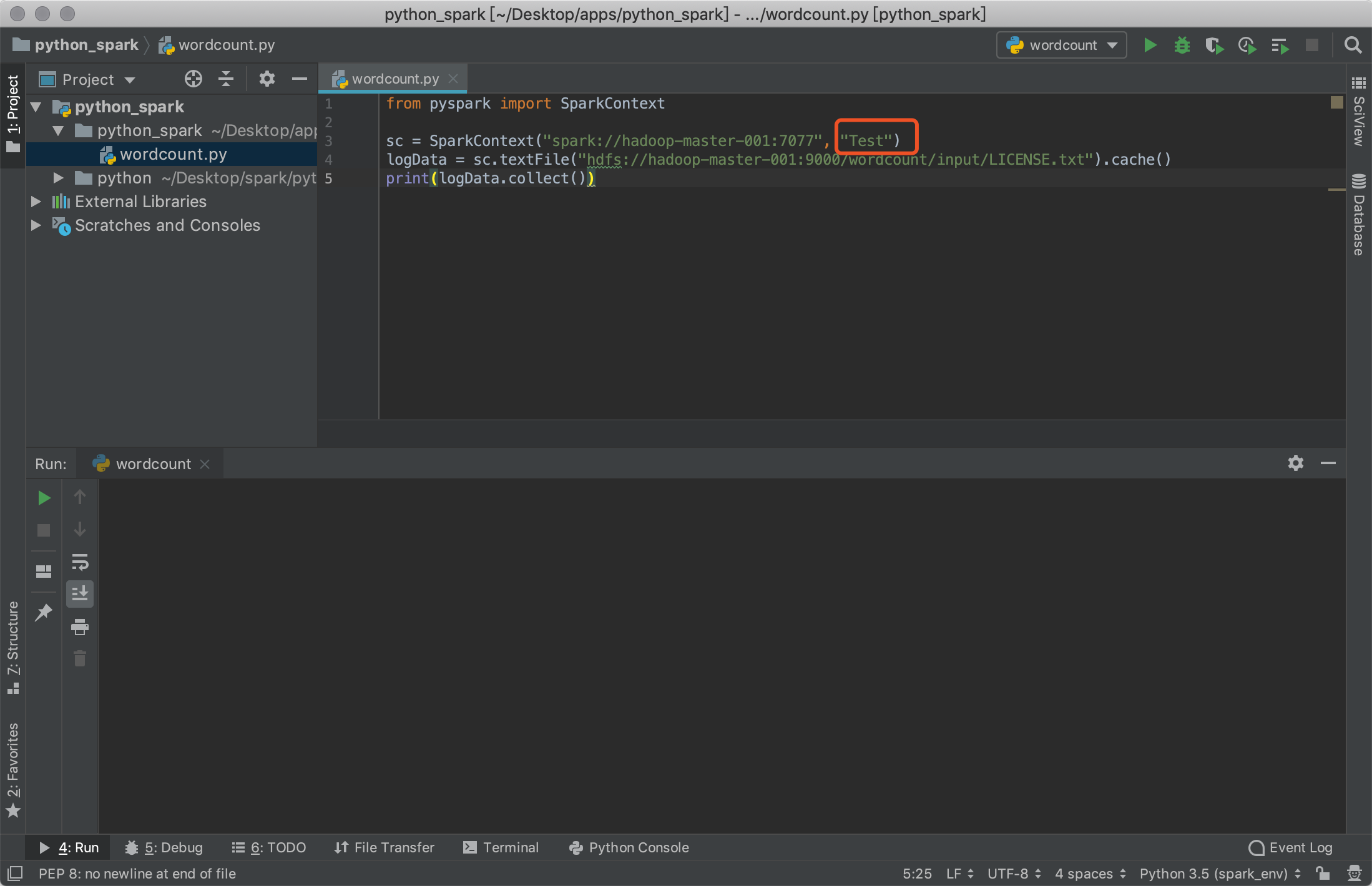
测试
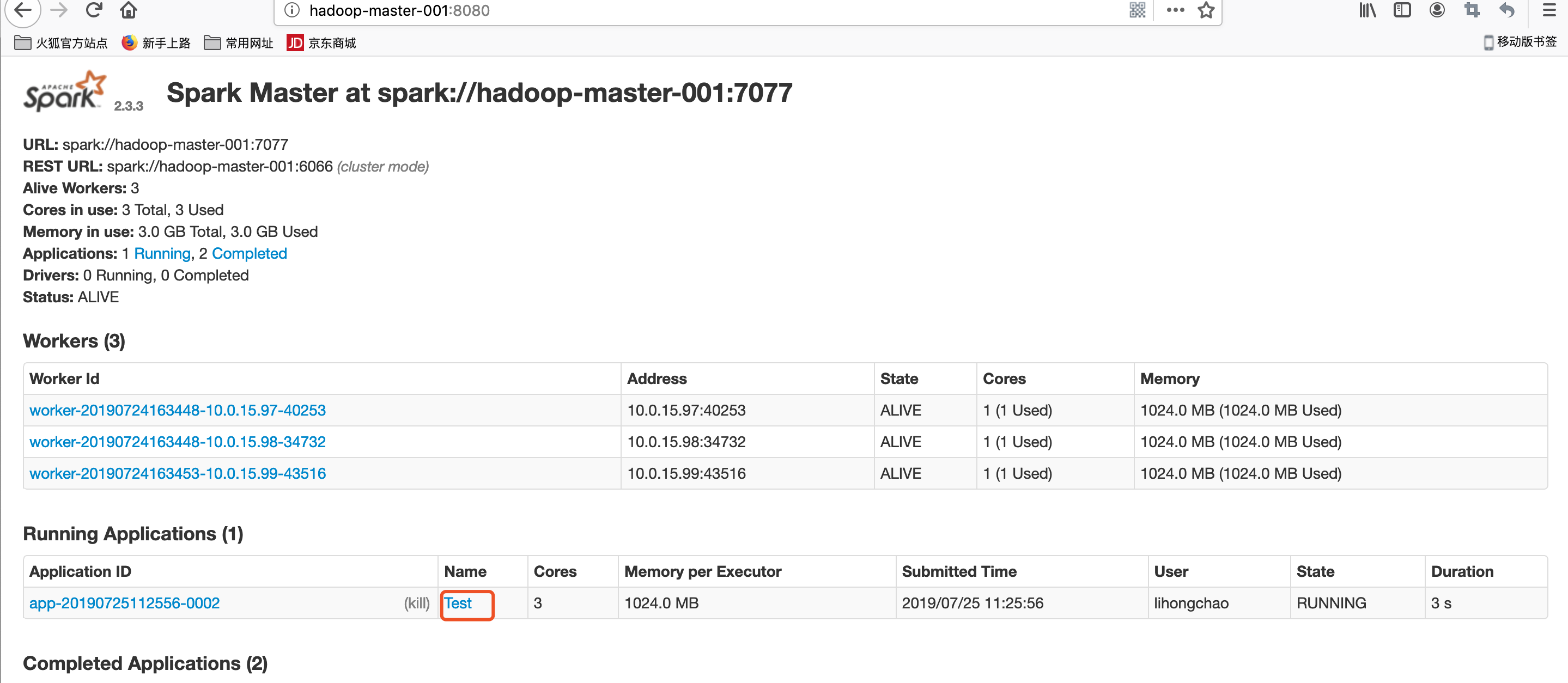
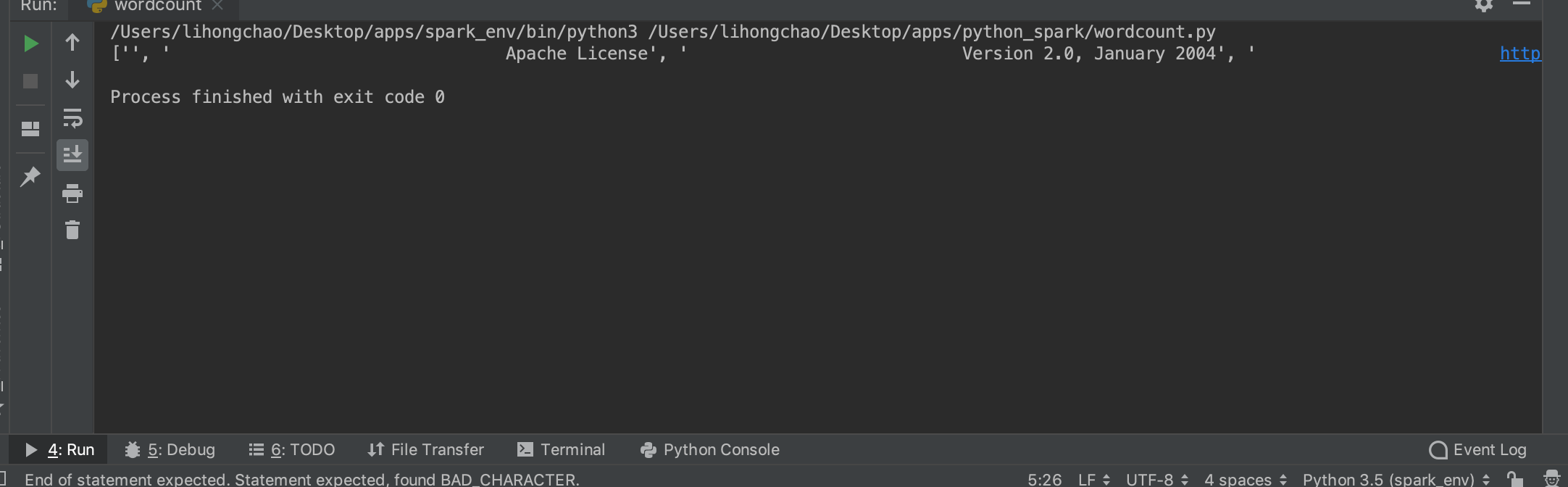
参考地址
https://blog.csdn.net/mycafe_/article/details/79430320#commentsedit
本地Pycharm将spark程序发送到远端spark集群进行处理的更多相关文章
- 本地idea开发mapreduce程序提交到远程hadoop集群执行
https://www.codetd.com/article/664330 https://blog.csdn.net/dream_an/article/details/84342770 通过idea ...
- Scala进阶之路-Spark独立模式(Standalone)集群部署
Scala进阶之路-Spark独立模式(Standalone)集群部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我们知道Hadoop解决了大数据的存储和计算,存储使用HDFS ...
- spark学习之路1--用IDEA编写第一个基于java的程序打包,放standalone集群,client和cluster模式上运行
1,首先确保hadoop和spark已经运行.(如果是基于yarn,hdfs的需要启动hadoop,否则hadoop不需要启动). 2.打开idea,创建maven工程.编辑pom.xml文件.增加d ...
- Spark on Yarn——spark1.5.1集群配置
写在前面: spark只是一种计算框架,如果要搭建集群要依托与一定的组织模式. 目前来说,Spark集群的组织形式有三种: 1. Standalone:使用akka作为网络IO组件,mast ...
- 用python + hadoop streaming 编写分布式程序(二) -- 在集群上运行与监控
写在前面 相关随笔: Hadoop-1.0.4集群搭建笔记 用python + hadoop streaming 编写分布式程序(一) -- 原理介绍,样例程序与本地调试 用python + hado ...
- Spark standalone安装(最小化集群部署)
Spark standalone安装-最小化集群部署(Spark官方建议使用Standalone模式) 集群规划: 主机 IP ...
- 【原创】大叔经验分享(14)spark on yarn提交任务到集群后spark-submit进程一直等待
spark on yarn通过--deploy-mode cluster提交任务之后,应用已经在yarn上执行了,但是spark-submit提交进程还在,直到应用执行结束,提交进程才会退出,有时这会 ...
- Spark wordcount开发并提交到集群运行
使用的ide是eclipse package com.luogankun.spark.base import org.apache.spark.SparkConf import org.apache. ...
- spark学习7(spark2.0集群搭建)
第一步:安装spark 将官网下载好的spark-2.0.0-bin-hadoop2.6.tgz上传到/usr/spark目录下.这里需注意的是spark和hadoop有对应版本关系 [root@sp ...
随机推荐
- 文件CRC和MD5校验
文件CRC和MD5校验 CRC和MD5用于文件和数据的传输校验,以确认是否接收成功. unit CRCMD5; interface { 获取文件CRC校验码 } function GetFileCRC ...
- Vue——路由:登录状态的判断
在搭建的系统中,最基本的登录都是必须的,结合Vue的路由,涉及最多的就是登录状态的判断.也就是说,如果一个组件要校验登录状态,则在用户初始进入时,就要去判断用户是否登录,这里的校验登录状态就是本篇的重 ...
- patch工具的使用
1. 最简用法 patch -p1 < jello.patch
- PorterDuffXfermode之Mode.SRC_IN
package com.loaderman.customviewdemo.view; import android.content.Context; import android.graphics.B ...
- osg 线程模型
void ViewerBase::frame(double simulationTime) { if (_done) return; // OSG_NOTICE<<std::endl< ...
- sed替换 - 含斜杠(\)和Shell变量
gen_image.bat中的内容如下: FOTARomPacker.exe -i .\_ini\FOTARomPacker.ini -o .\_Output\a.bin @IF %ERRORLE ...
- CentOS7下搭建Ansible自动化运维工具,集中管理服务器
(1).Ansible具有如下特点: 部署简单,只需在主控端部署Ansible环境,被控端无需做任何操作: 默认使用SSH协议对设备进行管理: 主从集中化管理: 配置简单.功能强大.扩展性强: 支持A ...
- Day4作业:蛋疼CRM系统
先上流程图,还得27寸4K显示器,画图各种爽: ReadMe: 运行程序前的提示: 1.抱歉,你得装prettytable模块...... 2.还得抱歉,如果shell中运行,最好把字体调得小点,表格 ...
- 定时杀死warn进程
6 6 * * * /root/wz/mysqlRestart.sh #MySQL restart7 6 * * * /bin/sh /home/warn/kill_.sh8 6 * * * / ...
- Oracle ORA-00984: column not allowed here
ORA-00984错误: 列在此处不允许当数据以char的形式存在时,应加单引号,则插入数据库就不会出现类似错误.