流量分析系统---kafka集群部署
1、集群部署的基本流程
Storm上游数据源之Kakfa
下载安装包、解压安装包、修改配置文件、分发安装包、启动集群
2、基础环境准备
安装前的准备工作(zk集群已经部署完毕)
关闭防火墙
chkconfig iptables off && setenforce 0
创建工作目录并赋权
mkdir -p /export/servers
chmod 755 -R /export
3、集群部署
3.1下载安装包
wget http://mirrors.hust.edu.cn/apache/kafka/0.8.2.2/kafka_2.11-0.8.2.2.tgz
3.2解压安装包
tar -zxvf /export/software/kafka_2.11-0.8.2.2.tgz -C /export/servers/
cd /export/servers/
ln -s kafka_2.11-0.8.2.2 kafka
3.3修改配置文件
cp /export/servers/kafka/config/server.properties
/export/servers/kafka/config/server.properties.bak
vi /export/servers/kafka/config/server.properties
输入以下内容:
(提前创建好mkdir -p /export/servers/logs/kafka)
#broker的全局唯一编号,不能重复
broker.id=1 #每台机器递增 #用来监听链接的端口,producer或consumer将在此端口建立连接
port=9092 #处理网络请求的线程数量
num.network.threads=3 #用来处理磁盘IO的线程数量
num.io.threads=8 #发送套接字的缓冲区大小
socket.send.buffer.bytes=102400 #接受套接字的缓冲区大小
socket.receive.buffer.bytes=102400 #请求套接字的缓冲区大小
socket.request.max.bytes=104857600 #kafka运行日志存放的路径,需要提前创建好
log.dirs=/export/servers/logs/kafka #topic在当前broker上的分片个数
num.partitions=2 #用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1 #segment文件保留的最长时间,超时将被删除
log.retention.hours=168 #滚动生成新的segment文件的最大时间
log.roll.hours=168 #日志文件中每个segment的大小,默认为1G
log.segment.bytes=1073741824 #周期性检查文件大小的时间
log.retention.check.interval.ms=300000 #日志清理是否打开
log.cleaner.enable=true #broker需要使用zookeeper保存meta数据
zookeeper.connect=192.168.32.201:2181,192.168.32.202:2181,192.168.32.203:2181 #zookeeper链接超时时间
zookeeper.connection.timeout.ms=6000 #partion buffer中,消息的条数达到阈值,将触发flush到磁盘
log.flush.interval.messages=10000 #消息buffer的时间,达到阈值,将触发flush到磁盘
log.flush.interval.ms=3000 #删除topic需要server.properties中设置delete.topic.enable=true否则只是标记删除
delete.topic.enable=true #此处的host.name为本机IP(重要),如果不改,则客户端会抛出:Producer connection to localhost:9092
host.name=kafka01
advertised.host.name=192.168.32.201 #每台机子都要做相应修改
3.4分发安装包
scp -r /export/servers/kafka_2.11-0.8.2.2 kafka02:/export/servers
然后分别在各机器上创建软连
cd /export/servers/
ln -s kafka_2.11-0.8.2.2 kafka
3.5依次修改配置文件
依次修改各服务器上配置文件的的broker.id,分别是1,2,3不得重复。
host.name 改成自己的
advertised.host.name 改成自己的
配置环境变量
export KAFKA_HOME=/export/servers/kafka
export PATH=$PATH:$KAFKA_HOME/bin
3.6刷新环境变量
source /etc/profile
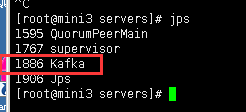
4、启动集群
启动集群各个节点启动zookeeper
各个节点启动集群
#启动
nohup kafka-server-start.sh /export/servers/kafka/config/server.properties &
#停止
kafka-server-stop.sh
流量分析系统---kafka集群部署的更多相关文章
- 流量分析系统--zookeeper集群部署
安装zookeeper mkdir apps tar -zxvf zookeeper-3.4.5.tar.gz -C apps [root@mini1 zookeeper-3.4.5]# rm -rf ...
- 分布式消息系统之Kafka集群部署
一.kafka简介 kafka是基于发布/订阅模式的一个分布式消息队列系统,用java语言研发,是ASF旗下的一个开源项目:类似的消息队列服务还有rabbitmq.activemq.zeromq:ka ...
- zookeeper集群+kafka集群 部署
zookeeper集群 +kafka 集群部署 1.Zookeeper 概述: Zookeeper 定义 zookeeper是一个开源的分布式的,为分布式框架提供协调服务的Apache项目 Zooke ...
- kafka 集群部署 多机多broker模式
kafka 集群部署 多机多broker模式 环境IP : 172.16.1.35 zookeeper kafka 172.16.1.36 zookeeper kafka 172.16 ...
- Zookeeper+Kafka集群部署(转)
Zookeeper+Kafka集群部署 主机规划: 10.200.3.85 Kafka+ZooKeeper 10.200.3.86 Kafka+ZooKeeper 10.200.3.87 Kaf ...
- 3、Kafka集群部署
Kafka集群部署 1)解压安装包 [ip101]$ tar -zxvf kafka_2.11-0.11.0.0.tgz -C /opt/app/ 2)修改解压后的文件名称 [ip101]$ mv k ...
- Zookeeper+Kafka集群部署
Zookeeper+Kafka集群部署 主机规划: 10.200.3.85 Kafka+ZooKeeper 10.200.3.86 Kafka+ZooKeeper 10.200.3.87 Kaf ...
- Kafka集群部署 (守护进程启动)
1.Kafka集群部署 1.1集群部署的基本流程 下载安装包.解压安装包.修改配置文件.分发安装包.启动集群 1.2集群部署的基础环境准备 安装前的准备工作(zk集群已经部署完毕) 关闭防火墙 c ...
- Kafka集群部署以及使用
Kafka集群部署 部署步骤 hadoop102 hadoop103 hadoop104 zk zk zk kafka kafka kafka http://kafka.apache.org/down ...
随机推荐
- jquery的val()
jQuery 属性操作 - val() 方法 jQuery 属性操作参考手册 实例 设置输入域的值: $("button").click(function(){ $(": ...
- Java时间类总结
java.util.Date 包含有年月日时分秒,精确到毫秒级别. 官方解释: // The class Date represents a specific instant in time, wit ...
- CS项目总结
最近做了近一年的CS项目终于接近完工了,有一种脱离苦海,跳出泥潭的感觉.虽然此项目做的很不理想,但它却给了我颇多感受,许多经验教训值得总结. 1.总的技术解决方案大方向上选择的不合适,导致后期对新的需 ...
- c++如何new构造函数是protected的对象
如果确实要new的话,可以继承这个类,然后new派生类,再转换为基类指针
- jxta 2.8x启动了
http://chaupal.github.io/ ———————————————————————————————————————————————————————————————————— 至少两个月 ...
- Spring4 MVC REST服务使用@RestController实例
在这篇文章中,我们将通过开发使用 Spring4 @RestController 注解来开发基于Spring MVC4的REST风格的JSON服务.我们将扩展这个例子通过简单的注释与JAXB标注域类支 ...
- python爬虫:正则表达式
符号: . : 匹配任意字符(类似占位符,多少个.就表示多少个字符),换行符除外(与re.S相反) *:匹配前面一个字符0次或无限次 ?:匹配前面一个字符0次或1次 组合: .* : 贪心算法 一次匹 ...
- Java语言如何进行异常处理,关键字:throws、throw、try、catch、finally分别如何使用?
先上代码再进行分析 public class Test { public static void main(String[] args) { try{ int i = 100 / 0; System. ...
- 【BZOJ3526】[Poi2014]Card 线段树
[BZOJ3526][Poi2014]Card Description 有n张卡片在桌上一字排开,每张卡片上有两个数,第i张卡片上,正面的数为a[i],反面的数为b[i].现在,有m个熊孩子来破坏你的 ...
- Salty Fish(区间和)
Problem 2253 Salty Fish Accept: 35 Submit: 121Time Limit: 1000 mSec Memory Limit : 32768 KB Pr ...