Python+selenium爬取智联招聘的职位信息
整个爬虫是基于selenium和Python来运行的,运行需要的包
mysql,matplotlib,selenium
需要安装selenium火狐浏览器驱动,百度的搜寻。
整个爬虫是模块化组织的,不同功能的函数和类放在不同文件中,最后将需要配置的常量放在constant.py中
项目地址:github(点击直达)
整个爬虫的主线程是Main.py文件,在设置好constant.py后就可以直接运行Main.py
从主线分析
Main.py
# /bin/python
# author:leozhao
# author@email: dhzzy88@.com """
这是整个爬虫系统的主程序
"""
import numpy as np import dataFactory
import plotpy
import sqlDeal
import zhilian
from Constant import JOB_KEY #
# 启动爬虫程序
zhilian.spidefmain(JOB_KEY) """
爬取数据结束后对数据可视化处理
"""
# 从数据库读取爬取的数据
# 先得到的是元组name,salray,demand,welfare value = sqlDeal.sqlselect()
# 工资上限,下限,平均值
updata = np.array([], dtype=np.int)
downdata = np.array([], dtype=np.int)
average = np.array([], dtype=np.int)
for item in value:
salray = dataFactory.SarayToInt(item[])
salray.slove()
updata = np.append(updata, salray.up)
downdata = np.append(downdata, salray.down)
average = np.append(average, (salray.up + salray.down) / ) # 工资上下限
average.sort() # 匹配城市信息 暂时还未实现 # 统计信息
# 两种图形都加载出来 方便查看
plotpy.plotl(average)
plotpy.plots(average) print(average, average.sum())
print("平均工资:", average.sum() / len(average))
print("最高:", average.max())
print("最低", average.min())
print("职位数", len(average)) # 画图
基本是以爬虫整个执行流程来组织的
从功能文件中导入zhilian.py
# /bin/python
# author:leo
# author@email : dhzzy88@163.com
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait import sqlDeal
from Constant import PAGE_NUMBER def init(key="JAVA"):
# 智联招聘的主页搜索关键字,初始化到采集页面
url = "https://www.zhaopin.com/"
opt = webdriver.FirefoxOptions()
opt.set_headless() #设置无头浏览器模式
driver = webdriver.Firefox(options=opt)
driver.get(url)
driver.find_element_by_class_name("zp-search-input").send_keys(key)
# driver.find_element_by_class_name(".zp-search-btn zp-blue-button").click()
driver.find_element_by_class_name("zp-search-input").send_keys(Keys.ENTER)
import time
time.sleep(2)
all = driver.window_handles
driver.switch_to_window(all[1])
url = driver.current_url
return url class ZhiLian: def __init__(self, key='JAVA'):
# 默认key:JAVA
indexurl = init(key)
self.url = indexurl
self.opt = webdriver.FirefoxOptions()
self.opt.set_headless()
self.driver = webdriver.Firefox(options=self.opt)
self.driver.get(self.url) def job_info(self): # 提取工作信息 可以把详情页面加载出来
job_names = self.driver.find_elements_by_class_name("job_title")
job_sarays = self.driver.find_elements_by_class_name("job_saray")
job_demands = self.driver.find_elements_by_class_name("job_demand")
job_welfares = self.driver.find_elements_by_class_name("job_welfare")
for job_name, job_saray, job_demand, job_welfare in zip(job_names, job_sarays, job_demands, job_welfares):
sqlDeal.sqldeal(str(job_name.text), str(job_saray.text), str(job_demand.text), str(job_welfare.text)) # 等待页面加载
print("等待页面加载")
WebDriverWait(self.driver, 10, ).until(
EC.presence_of_element_located((By.CLASS_NAME, "job_title"))
) def page_next(self):
try:
self.driver.find_elements_by_class_name("btn btn-pager").click()
except:
return None
self.url = self.driver.current_url
return self.driver.current_url def spidefmain(key="JAVA"):
ZHi = ZhiLian(key)
ZHi.job_info()
# 设定一个爬取的页数
page_count = 0
while True:
ZHi.job_info()
ZHi.job_info()
page_count += 1
if page_count == PAGE_NUMBER:
break
# 采集结束后把对象清除
del ZHi if __name__ == '__main__':
spidefmain("python")
这是调用selenium模拟浏览器加载动态页面的程序,整个爬虫的核心都是围绕这个文件来进行的。
每爬取一页信息以后就把解析的数据存储到数据库里,数据库处理函数的定义放在另外一个文件里,这里只处理加载和提取信息的逻辑
将数据存入本机的mysql数据库
# /bin/python
# author:leozhao
# author@email :dhzzy88@163.com import mysql.connector from Constant import SELECT
from Constant import SQL_USER
from Constant import database
from Constant import password def sqldeal(job_name, job_salray, job_demand, job_welfare):
conn = mysql.connector.connect(user=SQL_USER, password=password, database=database, use_unicode=True)
cursor = conn.cursor()
infostring = "insert into zhilian value('%s','%s','%s','%s')" % (
job_name, job_salray, job_demand, job_welfare) + ";"
cursor.execute(infostring)
conn.commit()
conn.close() def sqlselect():
conn = mysql.connector.connect(user=SQL_USER, password=password, database=database, use_unicode=True)
print("连接数据库读取信息")
cursor = conn.cursor() cursor.execute(SELECT)
values = cursor.fetchall()
conn.commit()
conn.close()
return values
两个函数
第一个负责存入数据
第二个负责读取数据
读取数据以后在另外的类中处理得到的数据
例如10K-20K这样的信息,为可视化做准备
# /bin/python
# author:leozhao
# author@email : dhzzy88@163.com import matplotlib.pyplot as plt
import numpy as np from Constant import JOB_KEY # 线型图 def plotl(dta):
dta.sort()
print("dta", [dta])
num = len(dta)
x = np.linspace(0, num - 1, num)
print([int(da) for da in dta])
print(len(dta))
plt.figure()
line = plt.plot(x, [sum(dta) / num for i in range(num)], dta) # plt.xlim(0, 250)
plt.title(JOB_KEY + 'Job_Info')
plt.xlabel(JOB_KEY + 'Job_Salray')
plt.ylabel('JobNumbers')
plt.show() # 条形图 def plots(dta):
fig = plt.figure()
ax = fig.add_subplot(111)
ax.hist(dta, bins=15)
plt.title(JOB_KEY + 'Job_Info')
plt.xlabel(JOB_KEY + 'Job_Salray')
plt.ylabel('JobNumbers')
plt.show()
最后将得到的数据放入在画图程序中画图
最后计算相关数据
在爬取过程中及时将数据存入数据库,减少虚拟机内存的占比。
下面放上数据结果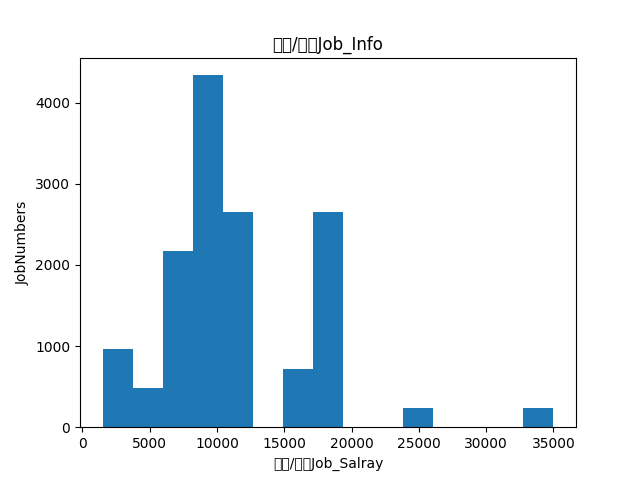
上面是金融的工作的薪酬调查
下面是材料科学的薪酬调查
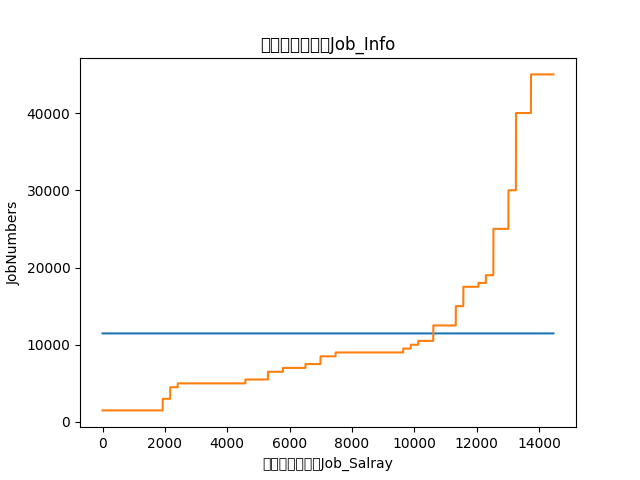
蓝色为平均工资。
注意在平均线以上的基本为博士和硕士的学历要求。
具体的数据处理没时间弄,有时间再做。
Python+selenium爬取智联招聘的职位信息的更多相关文章
- 用Python爬取智联招聘信息做职业规划
上学期在实验室发表时写了一个爬取智联招牌信息的爬虫. 操作流程大致分为:信息爬取——数据结构化——存入数据库——所需技能等分词统计——数据可视化 1.数据爬取 job = "通信工程师&qu ...
- python爬取智联招聘职位信息(多进程)
测试了下,采用单进程爬取5000条数据大概需要22分钟,速度太慢了点.我们把脚本改进下,采用多进程. 首先获取所有要爬取的URL,在这里不建议使用集合,字典或列表的数据类型来保存这些URL,因为数据量 ...
- 用生产者消费模型爬取智联招聘python岗位信息
爬取python岗位智联招聘 这里爬取北京地区岗位招聘python岗位,并存入EXECEL文件内,代码如下: import json import xlwt import requests from ...
- python爬取智联招聘职位信息(单进程)
我们先通过百度搜索智联招聘,进入智联招聘官网,一看,傻眼了,需要登录才能查看招聘信息 没办法,用账号登录进去,登录后的网页如下: 输入职位名称点击搜索,显示如下网页: 把这个URL:https://s ...
- scrapy框架爬取智联招聘网站上深圳地区python岗位信息。
爬取字段,公司名称,职位名称,公司详情的链接,薪资待遇,要求的工作经验年限 1,items中定义爬取字段 import scrapy class ZhilianzhaopinItem(scrapy.I ...
- node.js 89行爬虫爬取智联招聘信息
写在前面的话, .......写个P,直接上效果图.附上源码地址 github/lonhon ok,正文开始,先列出用到的和require的东西: node.js,这个是必须的 request,然发 ...
- scrapy项目2:爬取智联招聘的金融类高端岗位(spider类)
---恢复内容开始--- 今天我们来爬取一下智联招聘上金融行业薪酬在50-100万的职位. 第一步:解析解析网页 当我们依次点击下边的索引页面是,发现url的规律如下: 第1页:http://www. ...
- scrapy 爬取智联招聘
准备工作 1. scrapy startproject Jobs 2. cd Jobs 3. scrapy genspider ZhaopinSpider www.zhaopin.com 4. scr ...
- python3 requests_html 爬取智联招聘数据(简易版)
PS重点:我回来了-----我回来了-----我回来了 1. 基础需要: python3 基础 html5 CS3 基础 2.库的选择: 原始库 urllib2 (这个库早些年的用过,后来淡忘了) ...
随机推荐
- Android:通过滤镜实现点击图片变暗效果
实现点击图片(ImageView)变暗效果,有一个较简单的方法,就是讲目标图片设置为背景图片(setBackground),再创建一个selector.xml文件,里面放置一张普通状态时的透明图片,一 ...
- IT_Qestion
1. Javascript 回调 Promise 2. Angularjs $parent 3. CSS margin padding border 4. Angularjs $filter 5. D ...
- windows Server 2008各版本有何区别?
windows Server 2008有几个版本,先一一列出来把: Windows Server 2008 Standard Edition (标准版) Windows Server 2008 ...
- delphi OleVariant转换RecordSet
delphi OleVariant转换RecordSet uses Data.Win.ADODB; function varToRecordSet( parms : OleVariant ) : Da ...
- 201671010140. 2016-2017-2 《Java程序设计》java学习第二周
学习第二周(Java基本程序设计结构) 这一周,着重学习了Java的简单程序设计实现及运行,通过自己操作,发现Java的程序语法大面 ...
- Variable hoisting Function hoisting
Variable hoisting Another unusual thing about variables in JavaScript is that you can refer to a var ...
- CodeForces - 721E
题目大意 现有一个长为 L的数轴,你要从0走到 L 给出n个互不相交的可行域. 你要选择长度为p的段,要求每一个段都要在可行域内. 选完一段之后下一段要么和其相接,要么和其间距至少为t,求问最多能选择 ...
- CURL以 POST 请求链接的方式 初始化一个cURL会话来获取一个网页
/** *POST URL */ function posturl($URL,$data) { $ch = curl_init(); // 创建一个新cURL资源 curl_setopt($ch,CU ...
- SQL SERVER 2008权限配置
我要的结果是这样:只能有查询表的权限,而且还要有运行SQL Server Profiler的权限.这样才能跟踪发现问题,当然解决问题是另外一回事,即不能有修改和更新存储过程的权限. 我在分配角色成员时 ...
- sql去除重复记录 且保留id最小的 没用
第一步:查询重复记录 SELECT * FROM TableName WHERE RepeatFiled IN ( SELECT RepeatFiled FROM TableName ...