初识python 之 爬虫:爬取某网站的壁纸图片
用到的主要知识点:
requests.get 获取网页HTML
etree.HTML 使用lxml解析器解析网页
xpath 使用xpath获取网页标签信息、图片地址
request.urlretrieve 下载图片(注:该网站使用urlretrieve下载图片时,返回403错误。原因目前未知!)
改用 with as 下载图片:
with open('文件地址及名字', 'wb') as f:
f.write(res.content)
详细代码如下:
#!/user/bin env python
# author:Simple-Sir
# time:2019/7/17 10:14
# 爬取某网站的壁纸图片
import requests
from lxml import etree
from urllib import request
import urllib
import time # 伪装浏览器
headers ={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
}
# 获取壁纸首页网页信息并解析
def getUrlText(url):
respons = requests.get(url,headers=headers) # 获取网页信息
urlText = respons.text
html = etree.HTML(urlText) # 使用lxml解析网页
return html # 提取壁纸链接地址列表
def getWallUrl(url):
hrefUrl = getUrlText(url)
section = hrefUrl.xpath('//section[@class="thumb-listing-page"]')[0] # 获取section标签
hrefList = section.xpath('./ul//@href') # 获取首页图片对应链接地址
return hrefList # 获取当前时间
def getTime():
nowtime = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))
return nowtime # 解析壁纸下载地址
def downWall(url,page):
'''
:param url: 网页地址
:param page: 下载页数
:return: 下载结束提醒
'''
m = 0
page += 1
for i in range(1,page):
hrefList = getWallUrl(url+str(i))
n = 0
print('\033[36;1m*********** 开始下载第{}页壁纸 ************\033[0m'.format(i))
for href in hrefList:
n += 1
imgUrl = getUrlText(href) # 获取壁纸链接网页信息并解析
imgSrc = imgUrl.xpath('//img[@id="wallpaper"]/@src')[0]
# strUl = etree.tostring(imgSrc, encoding='utf-8').decode('utf-8') # 对获取到ul解码
# print(strUl)
imgType = imgSrc[-4:] # 壁纸格式
print('{}:\033[31;1m开始下载第{}页第{}张壁纸\033[0m'.format(getTime(),i,n))
# request.urlretrieve(imgSrc, './wall/' + str(n) + imgType) #403错误
res = requests.get(imgSrc)
with open('./wall/'+str(i)+'_'+str(n)+imgType, 'wb') as f:
f.write(res.content)
print('{}:\033[31;1m第{}页第{}张壁纸下载完成\033[0m'.format(getTime(),i,n))
m = m + n
return print('{}:\033[36;1m所有壁纸已下载完成,一共{}页{}张。\033[0m'.format(getTime(),i,m)) # url = 'https://wallhaven.cc/search?q=id%3A711&ref=fp&tdsourcetag=s_pcqq_aiomsg&page=' if __name__ == '__main__':
page =int(input('\033[36;1m请输入你想下载的页数:\033[0m'))
print('\033[36;1m程序执行中,请稍等。。。即将下载。\033[0m')
downWall('https://wall***&page=',page)
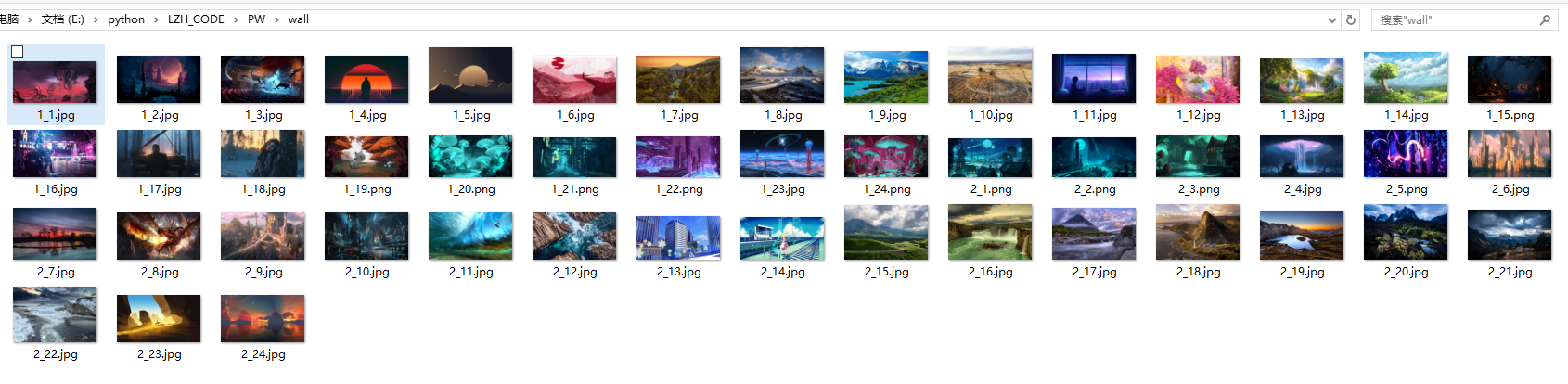
运行结果:


初识python 之 爬虫:爬取某网站的壁纸图片的更多相关文章
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
- 利用Python网络爬虫爬取学校官网十条标题
利用Python网络爬虫爬取学校官网十条标题 案例代码: # __author : "J" # date : 2018-03-06 # 导入需要用到的库文件 import urll ...
- python爬虫--爬取某网站电影下载地址
前言:因为自己还是python世界的一名小学生,还有很多路要走,所以本文以目的为向导,达到目的即可,对于那些我自己都没弄懂的原理,不做去做过多解释,以免误人子弟,大家可以网上搜索. 友情提示:本代码用 ...
- python爬虫--爬取某网站电影信息并写入mysql数据库
书接上文,前文最后提到将爬取的电影信息写入数据库,以方便查看,今天就具体实现. 首先还是上代码: # -*- coding:utf-8 -*- import requests import re im ...
- python之简单爬取一个网站信息
requests库是一个简介且简单的处理HTTP请求的第三方库 get()是获取网页最常用的方式,其基本使用方式如下 使用requests库获取HTML页面并将其转换成字符串后,需要进一步解析HTML ...
- python爬虫---爬取王者荣耀全部皮肤图片
代码: import requests json_headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win ...
- 利用python实现爬虫爬取某招聘网站,北京地区岗位名称包含某关键字的所有岗位平均月薪
#通过输入的关键字,爬取北京地区某岗位的平均月薪 # -*- coding: utf-8 -*- import re import requests import time import lxml.h ...
- Python多线程爬虫爬取电影天堂资源
最近花些时间学习了一下Python,并写了一个多线程的爬虫程序来获取电影天堂上资源的迅雷下载地址,代码已经上传到GitHub上了,需要的同学可以自行下载.刚开始学习python希望可以获得宝贵的意见. ...
- 如何用Python网络爬虫爬取网易云音乐歌曲
今天小编带大家一起来利用Python爬取网易云音乐,分分钟将网站上的音乐down到本地. 跟着小编运行过代码的筒子们将网易云歌词抓取下来已经不再话下了,在抓取歌词的时候在函数中传入了歌手ID和歌曲名两 ...
随机推荐
- MySQL-核心技术
1.基本查询语句 1.1使用select 语句查询一个数据表 select * from user; 1.2 查询表中的一列或多列 select id,ixdh from user; 1.3从一个表或 ...
- C/C++ Qt 数据库SqlRelationalTable关联表
在上一篇博文中详细介绍了SqlTableModle组件是如何使用的,本篇博文将介绍SqlRelationalTable关联表组件,该组件其实是SqlTableModle组件的扩展类,SqlRelati ...
- 【简】题解 AWSL090429 【原子】
预处理出每个原子最近的不能合并的位置 枚举当前位置和前面断开的位置合并 发现还是不能过 考虑用选段树优化 但是因为每次转移的最优点是在前面可以合并的范围内 dp值加上当前的到该点的最大值 因为每个位置 ...
- shell脚本 检查mysql节点数据一致性
一.简介 源码地址 日期:2018/4/12 介绍:参考pt checksum思想改写,可以定制化的检查随意两个mysql节点的数据一致性. 功能: 检查随意两个几点的数据一致性 支持并发检查,基于库 ...
- Jenkins多分支构建
目录 一.创建多分支pipeline 二.根据分支部署 gitlab触发与多分支 Generic Webhook多分支 一.创建多分支pipeline 在实际中,需要多分支同时进行开发.如果每个分支都 ...
- 两大js移动端调试神器 / 调试工具分享 !
分享大家一个CDN网站:https://www.bootcdn.cn/ eruda 移动端网页调试工具的使用: <script src="https://cdn.bootcdn.net ...
- 2021 中国.NET开发者峰会 今日开幕
01 大会介绍 .NET Conf China 2021 是面向开发人员的社区峰会,基于 .NET Conf 2021的活动,庆祝 .NET 6 的发布和回顾过去一年来 .NET 在中国的发展成果展示 ...
- CF363A Soroban 题解
Content 给出一个数 \(n\),请你用算盘来表示 \(n\). 这里的算盘和普通的算盘一样,只不过竖着摆放罢了.左边只有一个珠子,每个珠子表示 \(5\):右边有四个珠子,每个珠子表示 \(1 ...
- LuoguP7852 「EZEC-9」Yet Another Easy Problem 题解
Content 给定 \(n,m\),你需要输出一个长度为 \(n\) 的排列,满足该排列进行不超过 \(m\) 次交换操作可以得到的最小的字典序最大. 数据范围:\(T\) 组数据,\(1\leqs ...
- WebSocket协议理解-数据包格式解析
WebSocket 的诞生 做客户端开发时,接触最多的应用层网络协议,就是 HTTP 协议,而今天介绍的 WebSocket,下层和 HTTP 一样也是基于 TCP 协议,这是一种轻量级网络通信协议, ...