[PROC FREQ] 单组率置信区间的计算
本文链接:https://www.cnblogs.com/snoopy1866/p/15674999.html
利用PROC FREQ过程中的binomial语句可以很方便地计算单组率置信区间,SAS提供了9种(不包括校正法)计算单组率置信区间的方法,现列举如下:
首先准备示例数据:
data test;
input out $ weight;
cards;
阳性 95
阴性 5
;
run;
1. Wald 法
基于Wald法构建的单组率的置信区间应用非常广泛,且Wald在结构上有着以点估计为中心对称分布的天然优势,基于Wald法构建的单样本率置信区间可表示为:
\]
优点:以点估计为中心,对称分布
缺点:(1)Overshoot: 置信区间可能超过[0,1]范围(2)Degeneracy: 区间宽度可能为0(p=0或1时)(3)覆盖率差
代码:
proc freq data = test;
tables out /nopercent nocol norow nocum binomial(level = "阳性" cl = wald);
weight weight;
run;

2. Wald 法(连续性校正)
\]
优点:(1)可避免区间宽度可能为0的情况(2)覆盖率较Wald法有所改善
缺点:(1)结果偏保守(2)更容易发生置信区间超过[0,1]范围的情况
代码:
proc freq data = test;
tables out /nopercent nocol norow nocum binomial(level = "阳性" cl = wald(correct));
weight weight;
run;

3. Agresti-Coull
Agresti-Coull法的主要思路是选择一个大于0的常数作为pseudo-frequency,在计算样本量的时候对点估计进行校正,目的是使点估计尽量向中央(0.5)靠拢,这个大于零0的常数被称为估计因子\(\phi\)。
Agresti和Coull提出了\(\phi\)的两种形式,\(\phi =\frac{1}{2}z_{\alpha/2}^2\)和\(\phi = 2\),前者称为ADDZ2校正法,后者称为ADD4校正法,SAS中仅提供ADDZ2校正法,当\(\alpha = 0.05\)时,\(z_{\alpha/2}\)接近2,此时ADDZ2校正法与ADD4校正法近似。
当\(\phi = 2\)时(ADD4校正法),其实际含义是样本成功率和失败例数分别加2,即总样本量加4。
\]
其中\(\tilde{p} = \frac{n_1 + \frac{1}{2}z_{\alpha/2}^2}{n + z_{\alpha/2}^2}\)
优点:(1)downward spikes现象略有改善(downward spikes:当率在极端情况下,置信区间覆盖率急剧下滑)
缺点:(1)牺牲了置信区间宽度
代码:
proc freq data = test;
tables out /nopercent nocol norow nocum binomial(level = "阳性" cl = agresticoull);
weight weight;
run;

4. Wilson Score法
Wilson Score法作为Wald法的替代,应用十分广泛,是目前学界公认的在非极端率情况下的最佳置信区间构建方法。
基于Wilson Score法构建的置信区间可表示为:
\]
\(p\)可表示为:
\left( \hat{p} + \frac{z_{\alpha/2}^2}{2n} \pm z_{\alpha/2} \sqrt{\frac{\hat{p}(1-\hat{p}) + \frac{1}{4n}z_{\alpha/2}^2}{n}} \right)
\]
优点:(1)被认为是moderate proportion(率不接近0或1)的最佳方法
缺点:(1)存在downward spikes现象
代码:
proc freq data = test;
tables out /nopercent nocol norow nocum binomial(level = "阳性" cl = wilson);
weight weight;
run;
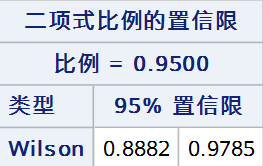
5. Wilson Score法(连续性校正)
基于Wilson Score法连续性校正构建的置信区间可表示为:
\]
代码:
proc freq data = test;
tables out /nopercent nocol norow nocum binomial(level = "阳性" cl = wilson(correct));
weight weight;
run;
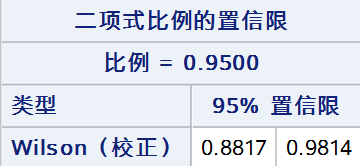
6. Jeffreys法
Jeffreys法构建的置信区间表示如下:
\]
\]
代码:
proc freq data = test;
tables out /nopercent nocol norow nocum binomial(level = "阳性" cl = jeffreys);
weight weight;
run;
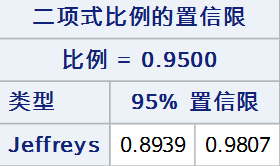
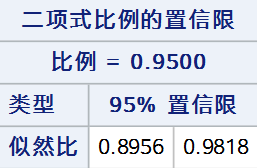
7. 似然比法
似然比法通过逆推似然比检验构造置信区间,零假设下似然比检验统计量可表示为:
\]
使检验统计量\(L(p_0)\)落在接受域内的所有\(p_0\)组成的区间即为似然比法的置信区间:\(\{p_0: L(p_0) < \chi_{1,\alpha}^2\}\),PROC FREQ通过迭代计算寻找置信限。
代码:
proc freq data = test;
tables out /nopercent nocol norow nocum binomial(level = "阳性" cl = likelihoodratio);
weight weight;
run;
8. Logit法
基于Logit变换 \(Y = \ln(\frac{\hat{p}}{1 - \hat{p}})\),\(Y\) 的近似置信区间用以下公式计算:
\]
\]
\(p\) 的置信区间可表示为:
\]
\]
代码:
proc freq data = test;
tables out /nopercent nocol norow nocum binomial(level = "阳性" cl = likelihoodratio);
weight weight;
run;
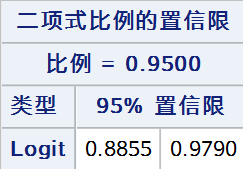
9. Clopper-Pearson法
基于二项分布构建的置信区间方法,使得精确置信限满足以下方程:
\]
\]
PROC FREQ 使用 \(F\) 分布计算Clopper-Pearson置信限,公式如下:
\]
\]
代码:
proc freq data = test;
tables out /nopercent nocol norow nocum binomial(level = "阳性" cl = likelihoodratio);
weight weight;
run;

10. Mid-P法
Mid-P 精确置信限满足以下方程:
\]
\]
代码:
proc freq data = test;
tables out /nopercent nocol norow nocum binomial(level = "阳性" cl = midp);
weight weight;
run;

11. Blaker法
通过对双侧 Blaker 精确检验逆推来构建置信区间,使检验统计量\(B(p_0, n_1)\)落在接受域内的所有\(p_0\)组成的区间称为Blaker置信区间:\(\{ p_0: B(p_0, n_1) > \alpha \}\)
其中:
\]
\]
代码:
proc freq data = test;
tables out /nopercent nocol norow nocum binomial(level = "阳性" cl = blaker);
weight weight;
run;
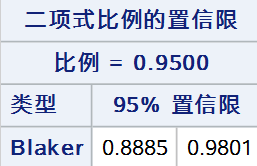
最后,将以上9种方法同时展示(wald 和 wilson 仅展示校正法):
proc freq data = test;
tables out /nopercent nocol norow
nocum binomial(level = "阳性"
cl = (wald(correct) agresticoull wilson(correct)
jeffreys likelihoodratio logit
clopperpearson midp blaker));
weight weight;
run;
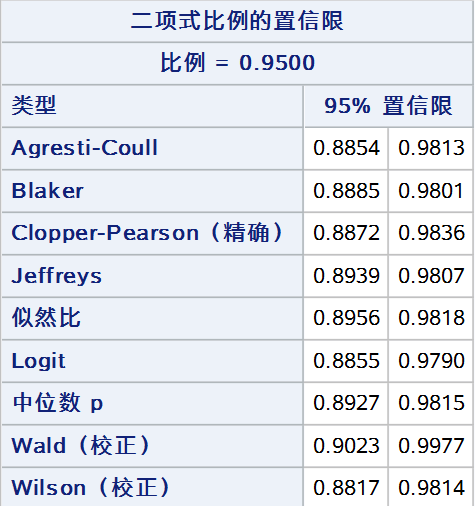
参考文献:徐莹. 一种新的单样本率的置信区间估计方法[D].南方医科大学,2019.
[PROC FREQ] 单组率置信区间的计算的更多相关文章
- SAS笔记(6) PROC MEANS和PROC FREQ
PROC MEANS和PRC FREQ在做描述性分析的时候很常用,用法也比较简单,不过这两个过程步的某些选项容易忘记,本文就梳理一下. 在进入正文前,我们先创建所需的数据集TEST_SCORES: D ...
- SAP MRP的计算步骤
SAP MRP的计算步骤,物料需求计划(简称为MRP)与主生产计划一样属于ERP计划管理体系,它主要解决企业生产中的物料需求与供给之间的关系,即无论是对独立需求的物料,还是相关需求的物料, ...
- 正确率、召回率和 F 值
原文:http://peghoty.blog.163.com/blog/static/49346409201302595935709/ 正确率.召回率和 F 值是在鱼龙混杂的环境中,选出目标的重要评价 ...
- 【转】构建高性能WEB站点之 吞吐率、吞吐量、TPS、性能测试
内容参考:构建高性能WEB站点.pdf 一.吞吐率 我们一般使用单位时间内服务器处理的请求数来描述其并发处理能力.称之为吞吐率(Throughput),单位是"req/s".吞吐率 ...
- 构建高性能WEB站点之 吞吐率、吞吐量、TPS、性能测试
内容参考: 构建高性能WEB站点.pdf 一.吞吐率 我们一般使用单位时间内服务器处理的请求数来描述其并发处理能力.称之为吞吐率(Throughput),单位是 “req/s”.吞吐率特指Web服务器 ...
- uber司机 如何提高评分、接单率、成单率?
接单率/成单率的解释 接单率计算方法为:成功接单的订单数 除以 系统派单的订单数. 成单率计算方法为:成功完成的订单数 除以 系统派单的订单数. 滴滴快车单单2.5倍,注册地址:http://www. ...
- 决策树C4.5算法——计算步骤示例
使用决策树算法手动计算GOLF数据集 步骤: 1.通过信息增益率筛选分支. (1)共有4个自变量,分别计算每一个自变量的信息增益率. 首先计算outlook的信息增益.outlook的信息增益Gain ...
- R-3 t分布--t置信区间--t检验
本节内容: 1:t分布存在的意义是什么 2:t分布的置信区间 3:t分布检验 一.t分布存在的意义是什么 数据分析中有一块很大的版图是属于均值对比的,应用广泛. 例如:对比试验前后病人的症状,证明某种 ...
- 用R语言求置信区间
用R语言求置信区间 用R语言求置信区间是很方便的,而且很灵活,至少我觉得比spss好多了. 如果你要求的只是95%的置信度的话,那么用一个很简单的命令就可以实现了 首先,输入da=c(你的数据,用英文 ...
随机推荐
- Java 8 新特性 用 Collectors 对 List 去重
场景:有一个实体的List集合,需要根据实体中的某个字段对List去重 Collectors.collectingAndThen方法:将流中的数据通过Collector计算,计算的结果再通过Funct ...
- Python使用cx_Oracle模块操作Oracle数据库--通过sql语句和存储操作
https://www.jb51.net/article/125160.htm?utm_medium=referral Python使用cx_Oracle调用Oracle存储过程的方法示例 http ...
- 面试官:咱们来聊一聊mysql主从延迟
背景 前段时间遇到一个线上问题,后来排查好久发现是因为主从同步延迟导致的,所以今天写一篇文章总结一下这个问题希望对你有用.如果觉得还不错,记得加个关注点个赞哦 思维导图 思维导图 常见的主从架构 随着 ...
- [noi109]排队
题目要求其实相当于要让大于和小于m的数的个数都不超过n/2,因此当要对一个数处理时,要么把它改成m,要么不作修改,根据这个贪心就可以完成了. 1 #include<bits/stdc++.h&g ...
- [noi38]游戏
用线段数维护一段区间内的两个信息:1.需要多少经验就可以让有一个人升级,2.等级和.单点修改直接暴力做就可以,区间修改考虑如果这个区间不会产生升级就不递归下去而是打上懒标记. 考虑这个算法的时间复杂度 ...
- [bzoj1052]覆盖问题
先二分答案,容易发现一定有一个正方形覆盖在角上(即有两条边在最X的地方),否则4个最X的点一定无法覆盖,然后暴力确定即可 1 #include<bits/stdc++.h> 2 using ...
- 『学了就忘』Linux用户管理 — 51、用户管理相关命令
目录 1.添加用户(useradd命令) 2.设定密码(passwd命令) 3.用户信息修改(usermod命令) 4.删除用户(userdel命令) 5.切换用户身份(su命令) 1.添加用户(us ...
- 【Matrix-tree Theorem学习笔记】
定义度数矩阵\(D(G)\): 定义邻接矩阵\(C(G)\): 定义\(Laplace\)矩阵\(A\) \( A(G) = D(G) - C(G) \) 记图\(G\)的所有生成树权值和为\(t(G ...
- 洛谷 P6031 - CF1278F Cards 加强版(推式子+递推)
洛谷题面传送门 u1s1 这个推式子其实挺套路的吧,可惜有一步没推出来看了题解 \[\begin{aligned} res&=\sum\limits_{i=0}^ni^k\dbinom{n}{ ...
- [linux] mv: cannot move $ to $: Directory not empty
最近测试某流程时,跑的过程报错了,于是检查脚本修改后重新测试.脚本是改过来了,但在shell中运行某步时碰到了如题报错! $ mv MP_genus_network_files/ tax_networ ...