DEEP LEARNING WITH PYTORCH: A 60 MINUTE BLITZ | NEURAL NETWORKS
神经网络可以使用 torch.nn包构建。
现在你已经对autograd有所了解,nn依赖 autograd 定义模型并对其求微分。nn.Module 包括层,和一个返回 output 的方法 - forward(input)。
例如,看看这个对数字图片进行分类的网络:
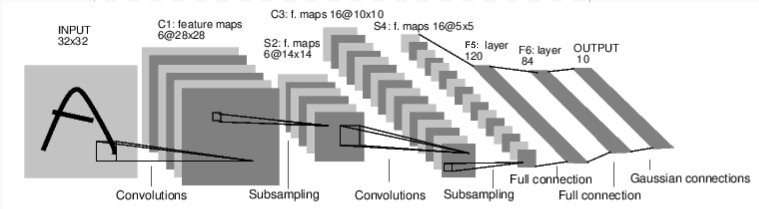
convnet
这是一个简单的前馈网络。它接受输入,通过一层接一层,最后输出。
一个典型的神经网络训练过程如下:
- 定义神经网络,并包括一些可学习的参数(或权重)
- 通过输入数据集迭代
- 通过网络处理输入
- 计算损失(输出和真值的差距)
- 将梯度反向传播至神经网络的参数
- 更新神经网络权重,通常使用简单的更新规则:
weight = weight - learning_rate * gradient。
定义网络
让我们定义这个网络:
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 1个输入图片通道,6个输出通道,5x5平方卷积核
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# 一个仿射变换操作:y = Wx + b
self.fc1 = nn.Linear(16 * 5 * 5, 120) # 5*5是特征图维度
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# 最大池化:(2,2)窗口
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# 如果窗口大小是正方形,可以使用单个数字
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = torch.flatten(x, 1) # 将除了batch维度的所有维度展平
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
print(net)
输出:
Net(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=400, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=10, bias=True)
)
你仅仅需要定义 forward 函数,backward 函数(梯度计算)会自动使用 autograd 定义。你可以在 forward 函数上使用任何Tensor操作。
net.parameters() 返回模型的可学习参数
params = list(net.parameters())
print(len(params))
print(param[0].size()) # conv1的权重参数
输出:
10
torch.size([6, 1, 5, 5])
让我们试试一个随机的32x32的输入。注意:该网络(LeNet)的输入大小是32x32。为在MNIST上使用该网络,请将图片缩放至32x32
input = torch.randn(1, 1, 32, 32)
out = net(input)
print(out)
输出:
tensor([[-0.1380, -0.0528, 0.0736, 0.1018, 0.0066, -0.1454, 0.0366, -0.0692,
0.0182, 0.0003]], grad_fn=<AddmmBackward0>)
使所有参数的梯度缓存归零,并反向传播 一个随机梯度:
net.zero_grad()
out.backward(torch.randn(1, 10))
注意:torch.nn仅支持mini-batches。整个 torch.nn包仅支持样本的mini-batch输入,而不是单个sample。例如,nn.Conv2d将接受一个4DTensor:nSamples x nChannels x Height x width。如果是单个样本,利用 input.unsqueeze(0) 添加一个假的batch维度即可。
在继续之前,让我们回顾一下所有你迄今为止看到的所有类。
Recap:
torch.Tensor- 一个multi-dimensional array,支持autograd操作,如backward()。还持有关于tensor的梯度。nn.Module- 神经网络模型。封装参数的一个便捷的途径,并且可将它们移动到GPU,输出、加载等。nn.Parameter- 当tensor作为属性赋给Module时,自动注册为参数。autograd.Function- autograd的前向和后向定义的具体实现。每一个Tensor操作创建最少一个Function节点,并连接到创建Tensor和对其历史进行编码的函数。
以上,我们介绍了:
- Defining a neural network
- Processing inputs and calling backward
还剩:
- 计算损失
- 更新网络权重
损失函数
损失函数接受input的(output,target)对,计算评估output距离target的值。
在nn包中有多种不同的loss function,一个简单的损失函数是:nn.MSELoss,它计算input和target的均方误差。
例如:
output = net(input)
target = torch.randn(10) # 一个假的target
target = target.view(1, -1) # 使其与output保持形状一致
criterion = nn.MSELoss()
loss = criterion(output, target)
print(loss)
输出:
tensor(1.3339, grad_fn=<MseLossBackward0>)
现在,如果你在后向传播中跟踪 loss,使用它的 .grad_fn 属性,你将会看到类似下面的计算图:
input -> conv2d -> relu -> maxpool2d -> conv2d -> relu -> maxpool2d
-> flatten -> linear -> relu -> linear - relu -> linear
-> MSELoss
-> loss
因此,当我们调用 loss.backward(),整个图将被求有关神经网络参数的导数,并且图中所有 requires_grad=True的Tensors将持有梯度Tensor - .grad。
为了说明,让我们查看几步backward:
print(loss.grad_fn) # MSELoss
print(loss.grad_fn.next_functions[0][0]) # Linear
print(loss.grad_fn.next_functions[0][0].next_functions[0][0]) # Relu
输出:
<MseLossBackward0 object at 0x7efad9c382b0>
<AddmmBackward0 object at 0x7efad9c386d8>
<AccumulateGrad object at 0x7efad9c386d8>
Backprop
为了使误差反向传播,我们需要做的仅仅是 loss.backward()。但是你需要清楚现有的梯度,否则梯度将会累积到已有的梯度之中。
现在调用 loss.backward(),并查看conv1的偏置在反向传播前后的梯度。
net.zero_grad() # 将所有参数的梯度缓存设置为0
print('conv1.bias.grad before backward')
print(net.conv1.bias.grad)
loss.backward()
print('conv1.bias.grad after backward')
print(net.conv1.bias.grad)
输出:
conv1.bias.grad before backward
tensor([0., 0., 0., 0., 0., 0.])
conv1.bias.grad after backward
tensor([ 0.0061, -0.0024, -0.0051, -0.0073, 0.0014, 0.0074])
现在,我们已经知道了如何使用损失函数。
Read Later:
神经网络包中包含多种模型和损失函数,用以组成深度神经网络的构建块,完整的文档列表在这。
还剩最后一部分:
- 更新网络的权重
更新权重
在实践中最简单的更新方法是随机梯度下降(SGD)
weight = weight - learning * gradient
我们可以使用简单的Python代码实现SGD:
learning_rate = 0.1
for f in net.parameters():
f.data.sub_(f.grad.data * learning_rate)
但是,当你使用神经网络时,你想使用多种不同的更新规则,如SGD、Nesterov-SGD、Adam、RMSProp,etc。为了实现这个,我们构建了一个小型的包:torch.optim,可以实现以上所有方法。使用起来也非常简单。
import torch.optim as optim
# create your optimizer
optimizer = optim.SGD(net.parameters(), lr=0.01)
# 在训练循环中:
optimizer.zero_grad() # zero the gradient buffers
output = net(input)
loss = criterion(output, target)
loss.backward()
optimizer.step() # Does the update
DEEP LEARNING WITH PYTORCH: A 60 MINUTE BLITZ | NEURAL NETWORKS的更多相关文章
- DEEP LEARNING WITH PYTORCH: A 60 MINUTE BLITZ | TENSORS
Tensor是一种特殊的数据结构,非常类似于数组和矩阵.在PyTorch中,我们使用tensor编码模型的输入和输出,以及模型的参数. Tensor类似于Numpy的数组,除了tensor可以在GPU ...
- DEEP LEARNING WITH PYTORCH: A 60 MINUTE BLITZ | TORCH.AUTOGRAD
torch.autograd 是PyTorch的自动微分引擎,用以推动神经网络训练.在本节,你将会对autograd如何帮助神经网络训练的概念有所理解. 背景 神经网络(NNs)是在输入数据上执行的嵌 ...
- DEEP LEARNING WITH PYTORCH: A 60 MINUTE BLITZ | TRAINING A CLASSIFIER
你已经知道怎样定义神经网络,计算损失和更新网络权重.现在你可能会想, 那么,数据呢? 通常,当你需要解决有关图像.文本或音频数据的问题,你可以使用python标准库加载数据并转换为numpy arra ...
- Deep learning with PyTorch: A 60 minute blitz _note(1) Tensors
Tensors 1. construst matrix 2. addition 3. slice from __future__ import print_function import torch ...
- Deep Learning 论文解读——Session-based Recommendations with Recurrent Neural Networks
博客地址:http://www.cnblogs.com/daniel-D/p/5602254.html 新浪微博:http://weibo.com/u/2786597434 欢迎多多交流~ Main ...
- 课程一(Neural Networks and Deep Learning),第三周(Shallow neural networks)—— 3.Programming Assignment : Planar data classification with a hidden layer
Planar data classification with a hidden layer Welcome to the second programming exercise of the dee ...
- 课程一(Neural Networks and Deep Learning),第三周(Shallow neural networks)—— 0、学习目标
Learn to build a neural network with one hidden layer, using forward propagation and backpropagation ...
- 课程一(Neural Networks and Deep Learning),第三周(Shallow neural networks)—— 2、Practice Questions
1.以下哪一项是正确的?(检查所有适用的) (A,D,F,G) A. a[2] 表示第二层的激活函数值向量. B. X 是一个矩阵, 其中每一行都是一个训练示例. C. a[2] (12) 表示第二 ...
- 课程一(Neural Networks and Deep Learning),第三周(Shallow neural networks)—— 1、两层神经网络的单样本向量化表示与多样本向量化表示
如上图所示的两层神经网络, 单样本向量化: ...
随机推荐
- JS代码日期格式化
function dateConvert(format,value) { var date = new Date(value); var o = { "M+" : date.get ...
- c++之折半查找(二分查找)递归与非递归的实现
递归实现 template<typename T> int binary_search2(const T arr[], const int left, const int right, c ...
- 【LeetCode】953. Verifying an Alien Dictionary 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 日期 题目地址:https://leetcode.c ...
- 【LeetCode】73. Set Matrix Zeroes 解题报告(Python & C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 原地操作 新建数组 队列 日期 题目地址:https ...
- 本原串(hdu 2197)
本原串 题目链接 思路: 反向想将总的个数减去不符合要求的个数.我们枚举n的约数,然后把n平均分,就可以构成不符合要求的串,\(g[i]\)表示循环节长为i约数的个数\(2^i\),我们要求循环节为\ ...
- .Net Core&Agile Config配置中心
当服务逐渐的增多,对各服务的配置管理愈加重要,轻量级的配置中心,入手或是搭建都简单许多,基于.net core开发的轻量级配置中心AgileConfig,功能强大,上手简单. https://gith ...
- Java基础(八)——IO流1_字节流、字符流
一.概述 1.介绍 I/O是 Input/Output 的缩写,IO流用来处理设备之间的数据传输,如读/写文件,网络通讯等.Java对数据的操作是通过流的方式进行.java.io 包下提供了各种&qu ...
- C++异常处理(try catch throw)完全攻略
程序运行时常会碰到一些异常情况,例如: 做除法的时候除数为 0: 用户输入年龄时输入了一个负数: 用 new 运算符动态分配空间时,空间不够导致无法分配: 访问数组元素时,下标越界:打开文件读取时,文 ...
- Zabbix 代码执行漏洞复现 /zabbix-cve_2017_2824
环境: 利用docker将vulfocus环境pull到本地搭建 漏洞描述: Zabbix 是由Alexei Vladishev 开发的一种网络监视.管理系统,基于 Server-Client 架构. ...
- .NET 微服务——CI/CD(2):自动打包镜像
准备工作 一.开启docker的tcp 我的服务器是linux,以端口2376为例,找到docker.service,在ExecStart下新增这段代码即可: -H tcp://0.0.0.0:237 ...