大数据学习(03)——HDFS的高可用
高可用架构图
先上一张搜索来的图。
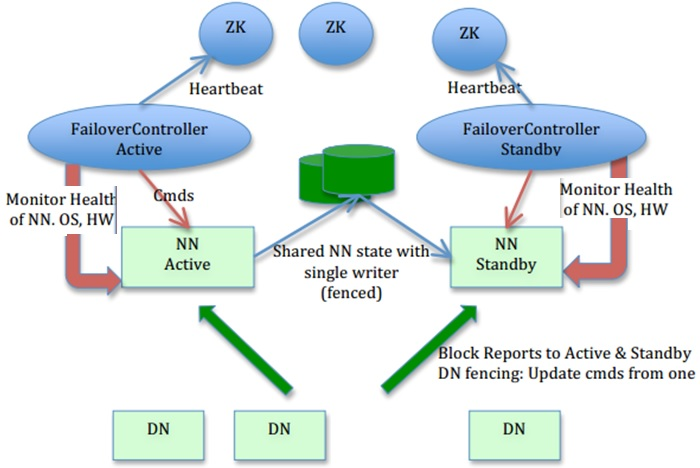
如上图,HDFS的高可用其实就是NameNode的高可用。
上一篇里,SecondaryNameNode是NameNode单节点部署才会有的角色,它只帮助NameNode完成日志合并的工作,在NameNode出现问题时不能顶上去。
在高可用里,不再有SecondaryNameNode这个角色,Hadoop2.x版本支持NameNode的一主一备,3.x版本支持一主多备,由备机完成日志合并任务。某个时点只有主NameNode对外提供服务。
总结一下,在一个高可用的HDFS集群里,至少需要这么几个角色:
- DataNode,存数据的节点,没它就不能叫文件系统了
- NameNode,有两个或多个,主节点状态是Active,备节点状态是Standby,备节点来同步、合并、推送主节点的FsImage
- 共享存储,存放的是主节点的实时日志,备节点从共享存储里异步同步日志,官方有QJM和NFS两种实现
为了实现NameNode的自动切换,还需要这两个角色:
- Zookeeper,分布式协调器,NameNode选主用的
- ZKFS,Zookeeper客户端,监控NameNode状态,并与Zookeeper保持长连接,与NameNode在一台机器上部署
高可用原理
它的高可用步骤如下:
- 在配置文件中配置多个NameNode属于同一个cluster,启动hdfs后,NameNode通过zookeeper选主
- 客户端通过dfs.client.failover.proxy.provider.[clusterID]配置的策略去访问NameNode,通常是向所有的NameNode发送请求来判断哪个是主节点
- 客户端对主NameNode发起的操作会同步写入共享存储,这里不直接写入其他NameNode是为了避免由于NameNode故障引起响应超时
- DataNode把文件的Block信息发送给所有的NameNode
- 备NameNode按照时间间隔或者日志文件大小来合并主NameNode的FsImage
- 如果主节点的NameNode或者ZKFS挂了
- 如果主NameNode挂了,本机的ZKFS会将ZK集群的锁释放,并回调其他ZKFS的方法,通知它们来拿锁。拿到锁的ZKFS连接一下原来的主NameNode,发现确实挂了,再把本机的NameNode状态由Standby修改为Active。
- 如果ZKFS挂了,ZKFS与ZK的TCP连接会断掉。ZK集群将删除该ZKFS持有的锁,并回调其他ZKFS的方法,通知它们来拿锁。拿到锁的ZKFS连接一下原来的主NameNode,发现它还活着,ZKFS先把原来的主NameNode降级为Standby,再把本机的NameNode升为Active。
高可用环境搭建
Hadoop的官方文档讲的很详细,参考 《用QJM实现HDFS的高可用》
HDFS联邦
一个主NameNode里存放的元数据毕竟容量有限,在数据量大的时候,很可能无法满足需要。
HDFS联邦机制类似于HDFS的分片存储,把所有元数据分散在多个NameNode里,互相没有交集。
那么客户端怎么知道要访问的数据该连接哪一个NameNode呢?这涉及到在多个NameNode之上增加一个抽象层的问题,由抽象层来确定到底该访问哪一个NameNode。
大数据学习(03)——HDFS的高可用的更多相关文章
- 大数据学习笔记——HDFS理论知识之编辑日志与镜像文件
HDFS文件系统——编辑日志和镜像文件详细介绍 我们知道,启动Hadoop之后,在主节点下会产生Namenode,即名称节点进程,该节点的目录下会保存一份元数据,用来记录文件的索引,而在从节点上即Da ...
- 入门大数据---基于Zookeeper搭建Kafka高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper 集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本 Zooke ...
- 入门大数据---基于Zookeeper搭建Spark高可用集群
一.集群规划 这里搭建一个 3 节点的 Spark 集群,其中三台主机上均部署 Worker 服务.同时为了保证高可用,除了在 hadoop001 上部署主 Master 服务外,还在 hadoop0 ...
- 大数据学习之HDFS基本API操作(下)06
hdfs文件流操作方法一: package it.dawn.HDFSPra; import java.io.BufferedReader; import java.io.FileInputStream ...
- 大数据学习之HDFS基本API操作(上)06
package it.dawn.HDFSPra; import java.io.FileNotFoundException; import java.io.IOException; import ja ...
- 大数据学习之hdfs集群安装部署04
1-> 集群的准备工作 1)关闭防火墙(进行远程连接) systemctl stop firewalld systemctl -disable firewalld 2)永久修改设置主机名 vi ...
- 大数据学习笔记——HDFS写入过程源码分析(2)
HDFS写入过程注释解读 & 源码分析 此篇博客承接上一篇未讲完的内容,将会着重分析一下在Namenode获取到元数据后,具体是如何向datanode节点写入真实的数据的 1. 框架图展示 在 ...
- 大数据学习笔记——HDFS写入过程源码分析(1)
HDFS写入过程方法调用逻辑 & 源码注释解读 前一篇介绍HDFS模块的博客中,我们重点从实践角度介绍了各种API如何使用以及IDEA的基本安装和配置步骤,而从这一篇开始,将会正式整理HDFS ...
- 大数据学习之HDFS基本命令操作05
1)hdfs的客户端 1.网页形式->测试用 http://192.168.40.11:50070/dfshealth.html#tab-overview 2.命令行形式->测试用 3.企 ...
- 大数据学习之HDFS的工作机制07
1:namenode+secondaryNameNode工作机制 2:datanode工作机制 3:HDFS中的通信(代理对象RPC) 下面用代码来实现基本的原理 1:服务端代码 package it ...
随机推荐
- Python UI自动化
Python3--Uiautomator2--Pytest--Alure使用 官方源码GitHub地址:https://github.com/openatx/uiautomator2 介绍 uiaut ...
- 由ASP.NET Core WebApi添加Swagger报错引发的探究
缘起 在使用ASP.NET Core进行WebApi项目开发的时候,相信很多人都会使用Swagger作为接口文档呈现工具.相信大家也用过或者了解过Swagger,这里咱们就不过多的介绍了.本篇文章记录 ...
- POJ 2002 二分 计算几何
根据正方形对角的两顶点求另外两个顶点公式: x2 = (x1+x3-y3+y1)/2; y2 = (x3-x1+y1+y3)/2; x4= (x1+x3+y3-y1)/2; y4 = (-x3+x1+ ...
- 对象池技术和通用实现GenericObjectPool
对象池技术其实蛮常见的,比如线程池.数据库连接池 他们的特点是:对象创建代价较高.比较消耗资源.比较耗时: 比如 mysql数据库连接建立就要先建立 tcp三次握手.发送用户名/密码.进行身份校验.权 ...
- CentOS-Docker搭建Kafka(单点,含:zookeeper、kafka-manager)
Docker搭建Kafka(单点,含:zookeeper.kafka-manager) 下载相关容器 $ docker pull wurstmeister/zookeeper $ docker pul ...
- jar打包
1.jar文件? 学过java的同学应该都听过吧!所以第一站是:打包发布 2.如何把 java 程序编译成 .exe 文件? 通常回答只有两种: 1)一种是制作一个可执行的 JAR 文件包,然后就可以 ...
- spring boot j集成seagger 加入拦截器后 swagger 不能访问
一开始我是这样排除拦截的,但是发现没用 后来我发现swagger的真实访问路径是这样的 转自: https://blog.csdn.net/ab1991823/article/details/7906 ...
- LVGL|lvgl中文手册(lvgl中文文档教程)
lvgl官方的教程是英文的,这个是我在做项目时根据lvgl官方文档做出来的lvgl中文文档(持续更新维护),不仅仅只是生硬照搬lvgl官方文档的翻译,同时总结了我们在实际开发中遇到的各种细节,让这个文 ...
- 前端-Vue基础2
1.过滤器 前台通过后台传值,要对后台传过来的变量进行特殊处理,比如根据id转成中文等: 1.1 局部过滤器 局部过滤器只针对一个Vue实例 默认将|左侧count传递给右侧方法 {{count|fi ...
- C语言变量类型
#include <stdio.h> // C 语言中,任何数据类型都不可以直接存储一个字符串.那么字符串如何存储? //在 C 语言中,字符串有两种存储方式,一种是通过字符数组存储,另一 ...