使用pandas中的raad_html函数爬取TOP500超级计算机表格数据并保存到csv文件和mysql数据库中
参考链接:https://www.makcyun.top/web_scraping_withpython2.html
#!/usr/bin/env python
# -*- coding: utf-8 -*- from multiprocessing.pool import Pool import pandas as pd
import requests
from sqlalchemy import create_engine # 数据库相关信息
HOSTNAME = '127.0.0.1'
PORT = ''
DATABASE = 'top500'
USERNAME = 'root'
PASSWORD = 'root' SQLALCHEMY_DATABASE_URI = "mysql+mysqlconnector://{username}:{password}@{host}:{port}/{db}?charset=utf8mb4".format(
username=USERNAME,
password=PASSWORD,
host=HOSTNAME,
port=PORT,
db=DATABASE) SQLALCHEMY_TRACK_MODIFICATIONS = False
SQLALCHEMT_ENCODING = 'utf8mb4' engine = create_engine(SQLALCHEMY_DATABASE_URI, echo=True) # 获取网页收据
def get_one_page(url):
response = requests.get(url)
if response.status_code == 200:
return response.text
else:
return None # 保存到csv文件
def save_csv(html):
dataframe = pd.read_html(html)
tb = dataframe[0].drop([0]) # 获取网页数据中的第一个表格数据,然后再去掉第一个表格数据中的的第一行(去掉的话csv文件中没有列名,不去掉的话多次写入列名)
# tb.columns = ['rank', 'site', 'system', 'cores', 'rmax', 'rpeak', 'power'] # 重命名列名
tb.to_csv(r'top500.csv', mode='a', encoding='utf_8_sig', index=True, header=False) # def save_mysql(html):
dataframe = pd.read_html(html)
tb = dataframe[0].drop([0])
tb.columns = ['rank', 'site', 'system', 'cores', 'rmax', 'rpeak', 'power']
try:
tb.to_sql('top500', con=engine, if_exists='append', index=False) # 需要事先建好top500数据表,并注意字段名称跟数据列名一一对应,字段值的长度要足够
print('success')
except:
print('fail') def main(offset):
url = 'https://www.top500.org/list/2018/11/?page=' + str(offset)
html = get_one_page(url)
# save_csv(html)
save_mysql(html) if __name__ == '__main__':
pool = Pool()
pool.map(main, [i for i in range(1, 6)])
csv文件效果:

csv文件待优化的地方:加上列名
mysql效果:
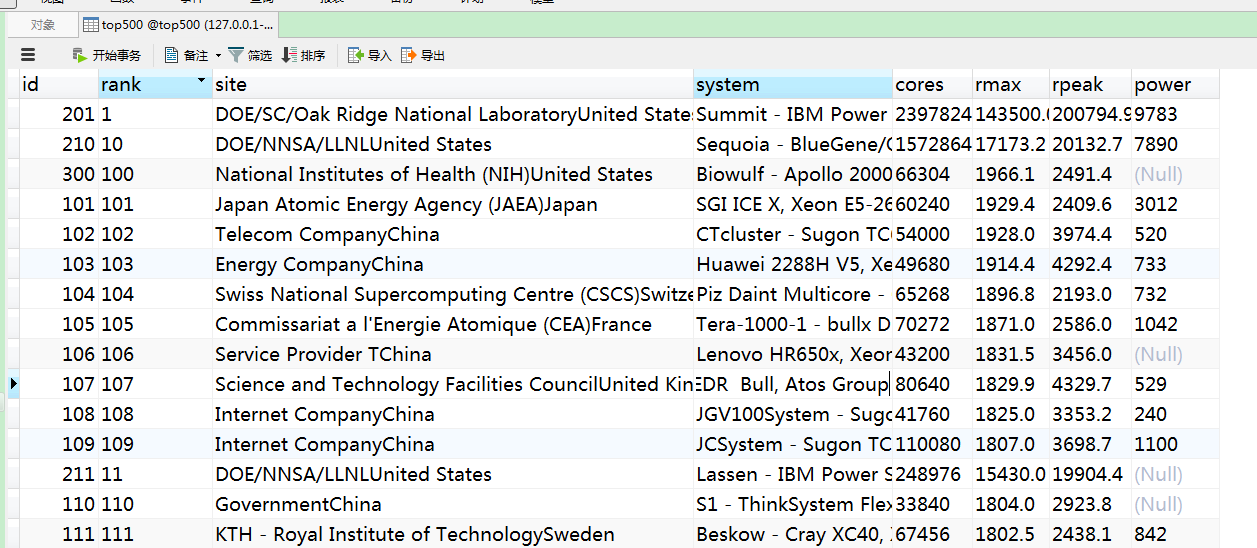
问题:
1.不论是csv文件还是mysql表格数据,根据rank字段进行排序,竟然排序的不怎么准确
2.site字段的最后部分数据是国家,这个需要想办法给剥离出来,再弄一列数据展示
使用pandas中的raad_html函数爬取TOP500超级计算机表格数据并保存到csv文件和mysql数据库中的更多相关文章
- JAVA读取CSV文件到MySQL数据库中
maven项目pom配置: <dependency> <groupId>net.sourceforge.javacsv</groupId> <artifact ...
- 记录python爬取猫眼票房排行榜(带stonefont字体网页),保存到text文件,csv文件和MongoDB数据库中
猫眼票房排行榜页面显示如下: 注意右边的票房数据显示,爬下来的数据是这样显示的: 网页源代码中是这样显示的: 这是因为网页中使用了某种字体的缘故,分析源代码可知: 亲测可行: 代码中获取的是国内票房榜 ...
- 使用scrapy爬取的数据保存到CSV文件中,不使用命令
pipelines.py文件中 import codecs import csv # 保存到CSV文件中 class CsvPipeline(object): def __init__(self): ...
- python爬取当当网的书籍信息并保存到csv文件
python爬取当当网的书籍信息并保存到csv文件 依赖的库: requests #用来获取页面内容 BeautifulSoup #opython3不能安装BeautifulSoup,但可以安装Bea ...
- 爬取某网站景区列表并保存为csv文件
网址:http://www.halehuo.com/jingqu.html 经过查看可以发现,该景区页面没有分页,不停的往下拉,页面会进行刷新显示后面的景区信息 通过使用浏览器调试器,发现该网站使用的 ...
- 爬取拉勾网python工程师的岗位信息并生成csv文件
转载自:https://www.cnblogs.com/sui776265233/p/11146969.html 代码写得很好,但是目前只看得懂前一部分 一.爬取和分析相关依赖包 Python版本: ...
- 简单又强大的pandas爬虫 利用pandas库的read_html()方法爬取网页表格型数据
文章目录 一.简介 二.原理 三.爬取实战 实例1 实例2 一.简介 一般的爬虫套路无非是发送请求.获取响应.解析网页.提取数据.保存数据等步骤.构造请求主要用到requests库,定位提取数据用的比 ...
- 使用requests、BeautifulSoup、线程池爬取艺龙酒店信息并保存到Excel中
import requests import time, random, csv from fake_useragent import UserAgent from bs4 import Beauti ...
- 使用requests、re、BeautifulSoup、线程池爬取携程酒店信息并保存到Excel中
import requests import json import re import csv import threadpool import time, random from bs4 impo ...
随机推荐
- Win8.1更新之后没法启动,怎样修复?
1.问题 今天开笔记本的时候,发现电脑没法启动.屏幕显示"Recovery Your PC needs to be repaired...". 详细内容见下图: 2.解决的方法 2 ...
- 使用resultMap实现ibatis复合数据结构查询(1.多重属性查询;2.属性中含有列表查询)
以订单为例(订单详情包括了订单的基本信息,配送物流信息,商品信息),直接上代码: 1.多重属性查询 java实体 public class OrderDetail { @XmlElement(requ ...
- 技术总结--android篇(四)--工具类总结
StringUtil(视个人须要进行加入) public class StringUtil { public static boolean isMail(String string) { if (nu ...
- HDU 3572 Task Schedule(ISAP模板&&最大流问题)
题目链接:http://acm.hdu.edu.cn/showproblem.php? pid=3572 题意:m台机器.须要做n个任务. 第i个任务.你须要使用机器Pi天,且这个任务要在[Si , ...
- luogu1514 引水入城
题目大意 在一个遥远的国度,一侧是风景秀美的湖泊,另一侧则是漫无边际的沙漠.该国的行政区划十分特殊,刚好构成一个NN 行\times M×M 列的矩形,如上图所示,其中每个格子都代表一座城市,每座城市 ...
- 83.个人信息维护页面 Extjs 页面
1 <%@ page language="java" import="java.util.*" pageEncoding="UTF-8" ...
- leetcode数学相关
目录 166分数到小数 169/229求众数 238除自身以外数组的乘积 69Sqrt(x) 求平方根 231Power of Two 166分数到小数 给定两个整数,分别表示分数的分子 numera ...
- PCB 全景图技术实现
为了对3D模型理解更透,这里采用threejs(WebGL第三方库)实现,刚开始学习入门,为了能看明白基本上每行代码都注释. 如果仅仅是为了实现全景图,可以用photo-sphere-viewer.j ...
- php 过滤敏感关键词
php 过滤敏感关键词 function badwords($content){ $keywords=M("config")->where("name='badwo ...
- pdf 转成 一张图片
1.maven依赖 <dependency> <groupId>org.apache.pdfbox</groupId> <artifactId>pdfb ...