模拟退火算法c++
转载. 为方便理解, 在原博客的基础上加部分注释, 原博客地址:http://www.cnblogs.com/CsOH/p/6049117.html
今天终于用模拟退火过了一道题:CodeVS: P1344。
有 N ( <=20 ) 台 PC 放在机房内,现在要求由你选定一台 PC,用共 N-1 条网线从这台机器开始一台接一台地依次连接他们,最后接到哪个以及连接的顺序也是由你选定的,为了节省材料,网线都拉直。求最少需要一次性购买多长的网线。(说白了,就是找出 N 的一个排列 P1 P2 P3 ..PN 然后 P1 -> P2 -> P3 -> ... -> PN 找出 |P1P2|+|P2P3|+...+|PN-1PN| 长度的最小值)
这种问题被称为最优组合问题。传统的动态规划算法O(n22n)在n = 20的情况下空间、时间、精度都不能满足了。这时应该使用比较另类的算法。随机化算法在n比较小的最优化问题表现较好,我们尝试使用随机化算法。
#include<cstdio>
#include<cstdlib>
#include<ctime>
#include<cmath>
#include<algorithm> const int maxn = ;
double x[maxn], y[maxn];
double dist[maxn][maxn];
int path[maxn];
int n;
double path_dist(){
double ans = ;
for(int i = ; i < n; i++) {
ans += dist[path[i - ]][path[i]];
}
return ans;
}
int main(){
srand(19260817U); // 使用确定的种子初始化随机函数是不错的选择
scanf("%d", &n);
for(int i = ; i < n; i++) scanf("%lf%lf", x + i, y + i);
for(int i = ; i < n; i++) for(int j = i + ; j < n; j++) dist[i][j] = dist[j][i] = hypot(x[i] - x[j], y[i] - y[j]); for(int i = ; i < n; i++) path[i] = i; // 获取初始排列
double ans = path_dist(); // 初始答案
int T = / n; // 单次计算的复杂度是O(n),这里的30000000是试出来的
while(T--){
std::random_shuffle(path, path + n); // 随机打乱排列
ans = std::min(ans, path_dist()); // 更新最小值
}
printf("%.2lf", ans);
}
可惜的是,这个算法只能拿50分。使用O(n!)枚举排列和使用上述算法没有太大的不同。从解的角度分析,假如某一次计算尝试出了一个比较好的路径,那么最优的路径很可能可以在原基础上作一两次改动就可以得到,这时候完全打乱整个序列不是一个很好的选择。
另一个方法:根据原序列生成一个新的序列,然后交换新序列的任意两个数。假如说新生成的序列更优,则使用新序列继续计算,否则序列不变。
这个算法就是局部搜索法(爬山法)。可惜,这个算法不正确。这个算法只顾眼前,忽略了大局,只要更优便走,这样可能会造成“盯着眼前的小山包,忽略远处的最高峰”,找到的值往往只是“局部最优值”。当然——这个方法也并不是完全不正确。我们可以多次计算使用上述方法计算,取最值。这里不再赘述。
下面介绍退火算法(SA,Simulated Annealing)。
首先拿爬山做例子:我们要找到山脉的最高峰,但是我(计算机)只能看到我的脚下哪边是上升的,哪边是下降的,看不到远处是否上升。每次移动,我们随机选择一个方向。如果这个方向是上升的的(更优),那么就决定往那个方向走;如果这个方向是下降的(更差),那么“随机地接受”这个方向,接受就走,不接受就再随机一次——这个随机是关键,要考虑很多因素。比如,一个陡的下坡的接受率要比一个缓的下坡要小(因为陡的下坡后是答案的概率小);同样的下降坡度,接受的概率随时间降低(逐渐降低才能趋向稳定)。
为什么要接受一个更差的解呢?如下图所示:
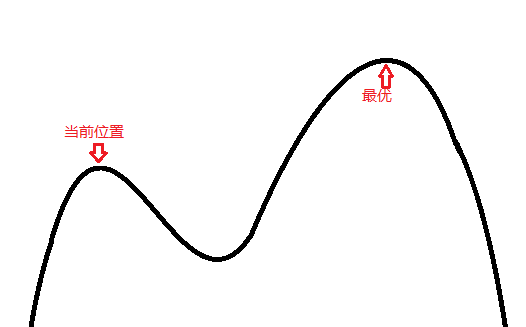
如果坚决不接受一个更差的解,那么就会卡在上面的“当前位置”上了。倘若接受多几次更差的解,让他移动到山谷那里,则可以突破局部最优解,得到全局最优解。
既然这个随机这么重要,那么我们就将它写为一个函数:
bool accept(double delta, double temper){
if(delta <= 0) return true;
return rand() <= exp((-delta) / temper) * RAND_MAX;
}
其中delta是新答案的变化量,temper是当前的“温度”。温度是模拟退火算法的一个重要概念,它随时间的推移缓慢减小。我们来分析一下这个代码:
if(delta <= 0) return true;
由于答案越小越优,因此当温度的变化量小于零(新答案减小)时,新解比旧解优,因此返回“接受”
return rand() <= exp((-delta) / temper) * RAND_MAX;
RAND_MAX是rand()的最大值。为了保证跨平台、跨编译器甚至跨版本时的正常运作,我们不对其作出任何假定。
我们把它移项:return (double)rand() / RAND_MAX <= exp((-delta) / temper)。在右边,temper是正数,delta是正数(delta是负数的已经return出去了),因此exp()中间的参数是负数。我们知道,指数函数在参数是负数时返回(0, 1)——这就是接受的概率。我们在左边随机一个实数,如果它比概率小,就接受,否则就不接受。
然后将RAND_MAX移到右边,以省下昂贵的除法成本和避免浮点数的各种陷阱。
有了接受函数,就可以写计算过程了:

double solve(){
const double max_temper = 10000;
double temp = max_temper;
double dec = 0.999;
Path p;
while(temp > 0.1){
Path p2(p);
if(accept(p2.dist() - p.dist(), temp)) p = p2;
temp *= dec;
}
return p.dist();
}
其中Path是路径,它有一个构造函数是接受另一个Path类型的对象,然后交换其中两个点的顺序。
1 struct Path{
2 City path[maxn];
3
4 Path(){
5 F(i, n) path[i] = citys[i];
6 }
7
8 Path(const Path& p):path(p.path){
9 swap(path[rand() % n], path[rand() % n]);
10 }
11
12 void shuffle(){
13 random_shuffle(path, path + n);
14 }
15
16 double dist(){
17 double ans = 0;
18 for(int i = 1; i < n; i++){
19 ans += path[i - 1].distTo(path[i]);
20 }
21 return ans;
22 }
23 };
上文的City是路径一个点。而void shuffle()是随机打乱整个序列(在本题没有用上)。
下面是City的定义:
1 struct City{
2 double x, y;
3 City(){}
4 City(double x, double y):x(x), y(y){}
5 double distTo(const City& rhs) const {
6 return hypot(x - rhs.x, y - rhs.y);
7 }
8 friend istream& operator >> (istream& in, City& c){
9 return in >> c.x >> c.y;
10 }
11 }citys[maxn];
最后是程序的主框架:
1 int main(){
2 srand(19260817U);
3 ios::sync_with_stdio(false);
4 cin >> n;
5 F(i, n) cin >> citys[i];
6 double ans = 1./0;
7 int T = 15;
8 while(T--){
9 ans = min(ans, solve());
10 }
11 printf("%.2lf", ans);
12 }
完整代码如下:
#define F(i, n) for(int i = 0; i < n; i++)
#define F1(i,n) for(int i = 1; i <=n; i++)
#include<cmath>
#include<algorithm>
#include<iostream>
#include<cstdio>
using namespace std; const int maxn = ; // 机器的数目
int n;
struct City{
double x, y;
City(){}
City(double x, double y):x(x), y(y){}
double distTo(const City& rhs) const {
return hypot(x - rhs.x, y - rhs.y);
}
friend istream& operator >> (istream& in, City& c){
return in >> c.x >> c.y;
}
}citys[maxn]; struct Path{
City path[maxn]; Path(){
F(i, n) path[i] = citys[i];
} Path(const Path& p):path(p.path){ // 生成新的path解时用,交换两个位置的数据
swap(path[rand() % n], path[rand() % n]);
} void shuffle(){
random_shuffle(path, path + n);
} double dist(){ // 求解总的距离
double ans = ;
for(int i = ; i < n; i++){
ans += path[i - ].distTo(path[i]);
}
return ans;
}
}; bool accept(double delta, double temper){
if(delta <= ) return true;
return rand() <= exp((-delta) / temper) * RAND_MAX;
} double solve(){
const double max_temper = ; // 初始温度
double temp = max_temper;
double dec = 0.999;
Path p;
while(temp > 0.1){
Path p2(p); // p2是新的解, 通过Path p2(p)构造时, 会随意交换p中两个位置的数据生成p2
if(accept(p2.dist() - p.dist(), temp)) p = p2;
temp *= dec;
}
return p.dist();
} int main(){
srand(19260817U);
ios::sync_with_stdio(false);
cin >> n;
F(i, n) cin >> citys[i];
double ans = ./; // +inf大于任何数,https://www.cnblogs.com/dosrun/p/3908617.html
//cout << "ans" << ans << endl;
int T = ;
while(T--){
ans = min(ans, solve());
}
printf("%.2lf", ans);
}
其实本代码在很多地方写复杂了,比如累赘的City类。在比赛中,我们不会写得如此复杂。下面对其简化:
#include<cstring>
#include<cmath>
#include<algorithm>
#include<iostream>
#include<cstdio>
using namespace std; const int maxn = ;
int n;
double x[maxn], y[maxn];
double dist[maxn][maxn]; struct Path{
int path[maxn]; Path(){
for(int i = ; i < n; i++) path[i] = i;
} Path(const Path& p){
memcpy(path, p.path, sizeof path);
swap(path[rand() % n], path[rand() % n]);
} double dist(){
double ans = ;
for(int i = ; i < n; i++){
ans += ::dist[path[i - ]][path[i]];
}
return ans;
}
}; bool accept(double delta, double temper){
if(delta <= ) return true;
return rand() <= exp((-delta) / temper) * RAND_MAX;
} double solve(){
const double max_temper = ;
const double dec = 0.999;
double temp = max_temper;
Path p;
while(temp > 0.01){
Path p2(p);
if(accept(p2.dist() - p.dist(), temp)) p = p2;
temp *= dec;
}
return p.dist();
} int main(){
srand(19260817U);
cin >> n;
for(int i = ; i < n; i++) {
scanf("%lf%lf", x + i, y + i);
}
for(int i = ; i < n; i++){
dist[i][i] = ;
for(int j = i + ; j < n; j++){
dist[i][j] = dist[j][i] = hypot(x[i] - x[j], y[i] - y[j]);
}
}
double ans = ./;
int T = ;
while(T--){
ans = min(ans, solve());
}
printf("%.2lf", ans);
}
交上去就可以AC了。
由于随机化算法有一定不稳定性,这里要多次调用计算过程取最小值。T=155就是外循环次数。
值得注意的是,T=15就可以过80%的数据,T=42可以过完全部数据,此时最大数据运行时间为86ms。这里T取155是保险起见,毕竟时间足够。
上面的代码仍有改进的余地。比如,在solve()函数中,应当把最优解记下来,在返回解时返回记下的那个最优解,免得跳到了某些差解后返回差解。
下面是一张表供大家估算运行时间,左边是“降温系数”,上方是初温与末温的比值,表格内容是大致的迭代次数。

从上表可以看出,增加十倍的初温与末温比值只会增加约25%的迭代次数,而往0.9…99的后面加个9会增加十倍的运行时间。
除了记忆上表外,我们还可以通过记录退火次数(将tot初始化为零,每次产生新解时tot++,计算完后看看tot)或者使用计算器计算退火次数。计算后选择一个合适的外循环次数。
除此之外,我们还要根据数据规模,灵活地调整初温、末温与降温系数。一般来说,初温不宜太大,否则会让前几次迭代接受了很差的解,浪费时间;降温系数不宜过大,否则会让算法过早稳定,不能找到最优值;同样,降温系数也不宜太高(更不能大于1,不然温度越来越高),否则可能会超时。
在正式使用中还有些技巧,如每次降温后,做足够多次计算后才再次降温(内循环),这对算法准确性没有太大影响。
除了模拟退火外,还有不少随机化算法。比如遗传算法、蚁群算法,这些算法被称为“元启发算法”,有兴趣的读者可以查阅相关资料。
模拟退火算法c++的更多相关文章
- 模拟退火算法-[HDU1109]
模拟退火算法的原理模拟退火算法来源于固体退火原理,将固体加温至充分高,再让其徐徐冷却,加温时,固体内部粒子随温升变为无序状,内能增大,而徐徐冷却时粒子渐趋有序,在每个温度都达到平衡态,最后在常温时达到 ...
- 【高级算法】模拟退火算法解决3SAT问题(C++实现)
转载请注明出处:http://blog.csdn.net/zhoubin1992/article/details/46453761 ---------------------------------- ...
- 模拟退火算法(SA)求解TSP 问题(C语言实现)
这篇文章是之前写的智能算法(遗传算法(GA).粒子群算法(PSO))的补充.其实代码我老早之前就写完了,今天恰好重新翻到了,就拿出来给大家分享一下,也当是回顾与总结了. 首先介绍一下模拟退火算法(SA ...
- 原创:工作指派问题解决方案---模拟退火算法C实现
本文忽略了对于模拟退火的算法的理论讲解,读者可参考相关的博文或者其他相关资料,本文着重于算法的实现: /************************************************ ...
- BZOJ 3680: 吊打XXX【模拟退火算法裸题学习,爬山算法学习】
3680: 吊打XXX Time Limit: 10 Sec Memory Limit: 128 MBSec Special JudgeSubmit: 3192 Solved: 1198[Sub ...
- OI骗分神器——模拟退火算法
前言&&为什么要学模拟退火 最近一下子学了一大堆省选算法,所以搞一个愉快一点的东西来让娱乐一下 其实是为了骗到更多的分,然后证明自己的RP. 说实话模拟退火是一个集物理与IT多方面知识 ...
- 模拟退火算法 R语言
0 引言 模拟退火算法是用来解决TSP问题被提出的,用于组合优化. 1 原理 一种通用的概率算法,用来在一个打的搜索空间内寻找命题的最优解.它的原理就是通过迭代更新当前值来得到最优解.模拟退火通常使用 ...
- 模拟退火算法(西安网选赛hdu5017)
Ellipsoid Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others) Total ...
- PKU 1379 Run Away(模拟退火算法)
题目大意:原题链接 给出指定的区域,以及平面内的点集,求出一个该区域内一个点的坐标到点集中所有点的最小距离最大. 解题思路:一开始想到用随机化算法解决,但是不知道如何实现.最后看了题解才知道原来是要用 ...
- 初探 模拟退火算法 POJ2420 HDU1109
模拟退火算法来源于固体退火原理,更多的化学物理公式等等这里不再废话,我们直接这么来看 模拟退火算法简而言之就是一种暴力搜索算法,用来在一定概率下查找全局最优解 找的过程和固体退火原理有所联系,一般来讲 ...
随机推荐
- java位运算笔记
位运算: ~(非)-->二进制数进行0和1的互换 样例: public class Test { public static void main(String[] args) { System. ...
- VB.net 捕获项目全局异常
在项目中添加如下代码:新建窗口来显示异常信息. Namespace My '全局错误处理,新的解决方案直接添加本ApplicationEvents.vb 到工程即可 '添加后还需要一个From用来显示 ...
- c# TextBox
1. text内容全选事件 textBox1.selectAll(); 2.失去与获取焦点事件 textox1.LostFocus += new EventHandler(txt_LostFocus) ...
- 将百度百科的机器学习词条中的一段关于机器学习的demo改用Java写了一遍
这是引用的百度百科中关于机器学习的一段示例,讲述了通过环境影响来进行学习的例子. 下面是代码: import java.io.BufferedReader; import java.io.IOExce ...
- Android DrawerLayout设置左右侧滑菜单为全屏
我们可以在MainActivity中获取屏幕宽度后动态赋值给侧滑菜单. 在oncreate时 DisplayMetrics metric = new DisplayMetrics(); getWind ...
- java和android文件加密小结
最近遇到一个文件加密的问题,自己读写的,安全性虽然还可以,但是速度慢,影响体验. Cipher虽然速度相当快,但是android和java有某些api存在不兼容: 问题解决: 方法引用自:https: ...
- JEE Spring-boot 简单的ioc写法。
什么是ioc,就是你可能会有一些生活必需品,这些东西你必须要用才能存活.但是你不是每天都回去买,去哪一家点去买.而这些用品会一直放在哪里,每一个商店就是一个容器,包裹着这些物品. 创建ioc项目,首先 ...
- net-speeder 安装
net-speeder net-speeder 在高延迟不稳定链路上优化单线程下载速度 项目由https://code.google.com/p/net-speeder/ 迁入 A program t ...
- MySQL构造测试数据
构造测试数据(笛卡尔积,6 次100 万) create table t1(id int, val varchar(80)); set @i := 0;create table tmp as sele ...
- 【node.js web项目】解决路由默认是hash模式(带#)
[概念讲述] 1.什么是hash模式 Vue+WebPack项目,本身是一个单页应用. vue-router 默认 hash 模式 —— 使用 URL 的 hash 来模拟一个完整的 URL,于是当 ...