MapReduce和Tez对比
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)"。
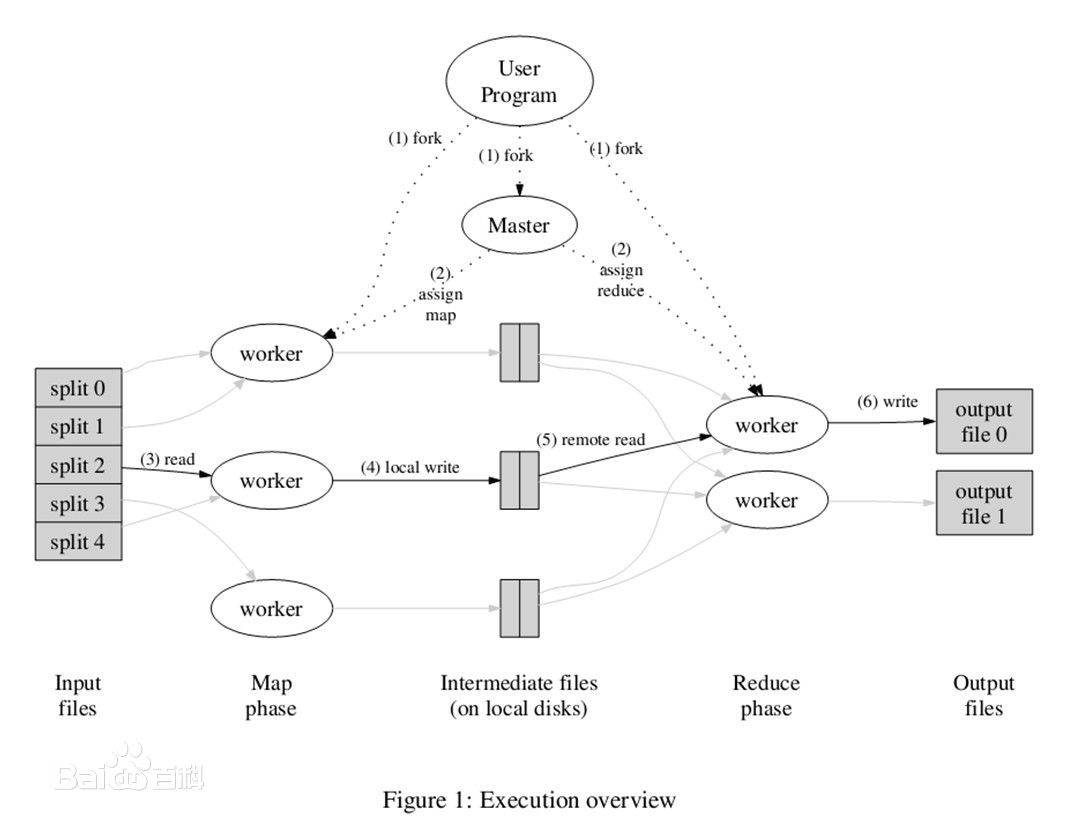
Tez是Apache开源的支持DAG作业的计算框架,它直接源于MapReduce框架,核心思想是将Map和Reduce两个操作进一步拆分,即Map被拆分成Input、Processor、Sort、Merge和Output, Reduce被拆分成Input、Shuffle、Sort、Merge、Processor和Output等,这样,这些分解后的元操作可以任意灵活组合,产生新的操作,这些操作经过一些控制程序组装后,可形成一个大的DAG作业。总结起来,Tez有以下特点:
(1)Apache二级开源项目(源代码今天发布的)
(2)运行在YARN之上
(3) 适用于DAG(有向图)应用(同Impala、Dremel和Drill一样,可用于替换Hive/Pig等)
对比举例:
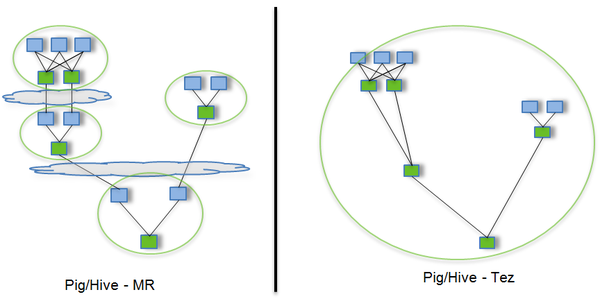
传统的MR(包括Hive,Pig和直接编写MR程序)。假设有四个有依赖关系的MR作业(1个较为复杂的Hive SQL语句或者Pig脚本可能被翻译成4个有依赖关系的MR作业)或者用Oozie描述的4个有依赖关系的作业,运行过程如下(其中,绿色是Reduce Task,需要写HDFS):
云状表示写屏蔽(write barrier,一种内核机制,持久写)
Tez可以将多个有依赖的作业转换为一个作业(这样只需写一次HDFS,且中间节点较少),从而大大提升DAG作业的性能
------------------------------
Hadoop是基础,其中的HDFS提供文件存储,Yarn进行资源管理。在这上面可以运行MapReduce、Spark、Tez等计算框架。
MapReduce:是一种离线计算框架,将一个算法抽象成Map和Reduce两个阶段进行处理,非常适合数据密集型计算。
Spark:Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于map reduce算法实现的分布式计算,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出和结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。
Storm:MapReduce也不适合进行流式计算、实时分析,比如广告点击计算等。Storm是一个免费开源、分布式、高容错的实时计算系统。Storm令持续不断的流计算变得容易,弥补了Hadoop批处理所不能满足的实时要求。Storm经常用于在实时分析、在线机器学习、持续计算、分布式远程调用和ETL等领域
Tez: 是基于Hadoop Yarn之上的DAG(有向无环图,Directed Acyclic Graph)计算框架。它把Map/Reduce过程拆分成若干个子过程,同时可以把多个Map/Reduce任务组合成一个较大的DAG任务,减少了Map/Reduce之间的文件存储。同时合理组合其子过程,也可以减少任务的运行时间
MapReduce和Tez对比的更多相关文章
- Spark的shuffle和MapReduce的shuffle对比
目录 MapperReduce的shuffle Spark的shuffle 总结 MapperReduce的shuffle shuffle阶段划分 Map阶段和Reduce阶段 任务 MapTask和 ...
- tez是什么?
[Apache Tez是什么?] http://dongxicheng.org/mapreduce-nextgen/apache-tez/ 浅谈Apache Tez中的优化技术 http://dong ...
- 重要 | Spark和MapReduce的对比,不仅仅是计算模型?
[前言:笔者将分上下篇文章进行阐述Spark和MapReduce的对比,首篇侧重于"宏观"上的对比,更多的是笔者总结的针对"相对于MapReduce我们为什么选择Spar ...
- 更快、更强——解析Hadoop新一代MapReduce框架Yarn(CSDN)
摘要:本文介绍了Hadoop 自0.23.0版本后新的MapReduce框架(Yarn)原理.优势.运作机制和配置方法等:着重介绍新的Yarn框架相对于原框架的差异及改进. 编者按:对于业界的大数据存 ...
- Spark环境搭建(五)-----------Spark生态圈概述与Hadoop对比
Spark:快速的通用的分布式计算框架 概述和特点: 1) Speed,(开发和执行)速度快.基于内存的计算:DAG(有向无环图)的计算引擎:基于线程模型: 2)Easy of use,易用 . 多语 ...
- Hadoop 新 MapReduce 框架 Yarn 详解【转】
[转自:http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/] 简介: 本文介绍了 Hadoop 自 0.23.0 版本 ...
- MapReduce 人个理解
1.MapReduce 理解 拆分成 map 过程与 reduce 过程: map 可以理解为sql 中的 group by 操作, reduce相当于group by 后的聚合计算 : 一个map ...
- HIVE执行引擎TEZ学习以及实际使用
概述 最近公司在使用Tez,今天写一篇关于Tez的学习和使用随笔.Tez是Apache最新的支持DAG作业的开源计算框架,它可以将多个有依赖的作业转换为一个作业从而大幅提升DAG作业的性能.Tez并不 ...
- Flink 剖析
1.概述 在如今数据爆炸的时代,企业的数据量与日俱增,大数据产品层出不穷.今天给大家分享一款产品—— Apache Flink,目前,已是 Apache 顶级项目之一.那么,接下来,笔者为大家介绍Fl ...
随机推荐
- 文件Copy和文件夹Copy
文件Copy和文件夹Copy using System.Collections.Generic; using System.Linq; using System.Text; using System. ...
- Android框架
http://blog.163.com/vicent_zxb/blog/static/1858861312011488262665/ (一)Android系统框架详解 Android采用分层的架构,分 ...
- Hibernate与MyBatis区别
Hibernate是当前主流的ORM框架,对数据库结构提供了较为完整的封装. MyBatis同样也是非常流行的ORM框架,主要在于pojo与SQL之间的映射关系. 区别: 1.两者最大的区别 针对简单 ...
- 黄聪:C#中WebClient自动判断编码是UTF-8还是GBK,并且有超时判断功能
public class WebDownload : WebClient { private int _timeout; /// <summary> /// 超时时间(毫秒) /// &l ...
- @synthesize obj = _obj 理解
在很多代码里可以看到类似得用法: @interface MyClass:NSObject{ MyObjecct *_object; } @property(nonamtic, retain) MyOb ...
- c++builder6.0 mdi窗体+自定义子窗体
- ASP.NET 中的 authentication(验证)与authorization(授权)
这两个东西很绕口,也绕脑袋. 一般来说,了解authentication(验证)的用法即可,用于自定义的用户验证. authorization(授权)主要通过计算机信息来控制. “*”:所有用户: “ ...
- spring2.5整合hibernate3.0整合Struts
首先:这是spring framework+hibernate+struts集成,spring主要用于aop和ioc,hibernate主要是用于持久层,struts主要是用于mvc. 同时关于spr ...
- c++学习-继承
继承 #include <iostream> using namespace std; class father{ public: void getHeight(){cout<< ...
- URI
1, URI (标识.定位任何资源的字符串) 在电脑术语中,统一资源标识符(Uniform Resource Identifier,或URI)是一个用于标识某一互联网资源名称的字符串. 该种标识允许用 ...