HDFS之SequenceFile和MapFile
http://blog.csdn.net/javaman_chen/article/details/7241087
Hadoop的HDFS和MapReduce子框架主要是针对大数据文件来设计的,在小文件的处理上不但效率低下,而且十分消耗内存资源(每一个小文件占用一个Block,每一个block的元数据都存储在namenode的内存里)。解决办法通常是选择一个容器,将这些小文件组织起来统一存储。HDFS提供了两种类型的容器,分别是SequenceFile和MapFile。
一、SequenceFile
SequenceFile的存储类似于Log文件,所不同的是Log File的每条记录的是纯文本数据,而SequenceFile的每条记录是可序列化的字符数组。
SequenceFile可通过如下API来完成新记录的添加操作:
fileWriter.append(key,value)
可以看到,每条记录以键值对的方式进行组织,但前提是Key和Value需具备序列化和反序列化的功能
Hadoop预定义了一些Key Class和Value Class,他们直接或间接实现了Writable接口,满足了该功能,包括:
Text 等同于Java中的String
IntWritable 等同于Java中的Int
BooleanWritable 等同于Java中的Boolean
.
.
在存储结构上,SequenceFile主要由一个Header后跟多条Record组成,如图所示:
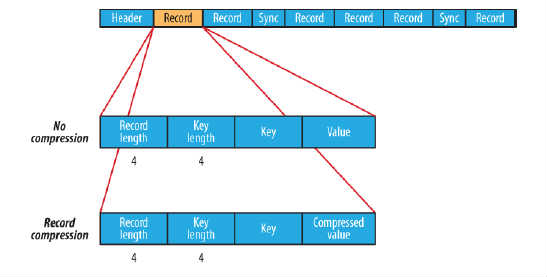
Header主要包含了Key classname,Value classname,存储压缩算法,用户自定义元数据等信息,此外,还包含了一些同步标识,用于快速定位到记录的边界。
每条Record以键值对的方式进行存储,用来表示它的字符数组可依次解析成:记录的长度、Key的长度、Key值和Value值,并且Value值的结构取决于该记录是否被压缩。
数据压缩有利于节省磁盘空间和加快网络传输,SeqeunceFile支持两种格式的数据压缩,分别是:record compression和block compression。
record compression如上图所示,是对每条记录的value进行压缩
block compression是将一连串的record组织到一起,统一压缩成一个block,如图所示:
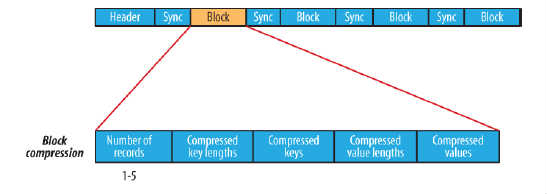
block信息主要存储了:块所包含的记录数、每条记录Key长度的集合、每条记录Key值的集合、每条记录Value长度的集合和每条记录Value值的集合
注:每个block的大小是可通过io.seqfile.compress.blocksize属性来指定的
示例:SequenceFile读/写 操作
- Configuration conf=new Configuration();
- FileSystem fs=FileSystem.get(conf);
- Path seqFile=new Path("seqFile.seq");
- //Reader内部类用于文件的读取操作
- SequenceFile.Reader reader=new SequenceFile.Reader(fs,seqFile,conf);
- //Writer内部类用于文件的写操作,假设Key和Value都为Text类型
- SequenceFile.Writer writer=new SequenceFile.Writer(fs,conf,seqFile,Text.class,Text.class);
- //通过writer向文档中写入记录
- writer.append(new Text("key"),new Text("value"));
- IOUtils.closeStream(writer);//关闭write流
- //通过reader从文档中读取记录
- Text key=new Text();
- Text value=new Text();
- while(reader.next(key,value)){
- System.out.println(key);
- System.out.println(value);
- }
- IOUtils.closeStream(reader);//关闭read流
二、MapFile
MapFile是排序后的SequenceFile,通过观察其目录结构可以看到MapFile由两部分组成,分别是data和index。
index作为文件的数据索引,主要记录了每个Record的key值,以及该Record在文件中的偏移位置。在MapFile被访问的时候,索引文件会被加载到内存,通过索引映射关系可迅速定位到指定Record所在文件位置,因此,相对SequenceFile而言,MapFile的检索效率是高效的,缺点是会消耗一部分内存来存储index数据。
需注意的是,MapFile并不会把所有Record都记录到index中去,默认情况下每隔128条记录存储一个索引映射。当然,记录间隔可人为修改,通过MapFIle.Writer的setIndexInterval()方法,或修改io.map.index.interval属性;
另外,与SequenceFile不同的是,MapFile的KeyClass一定要实现WritableComparable接口,即Key值是可比较的。
示例:MapFile读写操作
- Configuration conf=new Configuration();
- FileSystem fs=FileSystem.get(conf);
- Path mapFile=new Path("mapFile.map");
- //Reader内部类用于文件的读取操作
- MapFile.Reader reader=new MapFile.Reader(fs,mapFile.toString(),conf);
- //Writer内部类用于文件的写操作,假设Key和Value都为Text类型
- MapFile.Writer writer=new MapFile.Writer(conf,fs,mapFile.toString(),Text.class,Text.class);
- //通过writer向文档中写入记录
- writer.append(new Text("key"),new Text("value"));
- IOUtils.closeStream(writer);//关闭write流
- //通过reader从文档中读取记录
- Text key=new Text();
- Text value=new Text();
- while(reader.next(key,value)){
- System.out.println(key);
- System.out.println(key);
- }
- IOUtils.closeStream(reader);//关闭read流
注意:使用MapFile或SequenceFile虽然可以解决HDFS中小文件的存储问题,但也有一定局限性,如:
1.文件不支持复写操作,不能向已存在的SequenceFile(MapFile)追加存储记录
2.当write流不关闭的时候,没有办法构造read流。也就是在执行文件写操作的时候,该文件是不可读取的
HDFS之SequenceFile和MapFile的更多相关文章
- SequenceFile和MapFile
HDFS和MR主要针对大数据文件来设计,在小文件处理上效率低.解决方法是选择一个容器,将这些小文件包装起来,将整个文件作为一条记录,可以获取更高效率的储存和处理,避免多次打开关闭流耗费计算资源.hdf ...
- HDFS 文件格式——SequenceFile RCFile
 HDFS块内行存储的例子  HDFS块内列存储的例子  HDFS块内RCFile方式存储的例子
- Hadoop SequenceFile数据结构介绍及读写
在一些应用中,我们需要一种特殊的数据结构来存储数据,并进行读取,这里就分析下为什么用SequenceFile格式文件. Hadoop SequenceFile Hadoop提供的SequenceFil ...
- HDFS简介【全面讲解】
http://www.cnblogs.com/chinacloud/archive/2010/12/03/1895369.html [一]HDFS简介HDFS的基本概念1.1.数据块(block)HD ...
- MapReduce中使用SequenceFile的方式上传文件到集群中
如果有很多的小文件,上传到HDFS集群,每个文件都会对应一个block块,一个block块的大小默认是128M,对于很多的小文件来说占用了非常多的block数量,就会影响到内存的消耗, MapRedu ...
- 非常不错 Hadoop 的HDFS (Hadoop集群(第8期)_HDFS初探之旅)
1.HDFS简介 HDFS(Hadoop Distributed File System)是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开 ...
- HDFS存储系统
HDFS存储系统 一.基本概念 1.NameNode HDFS采用Master/Slave架构.namenode就是HDFS的Master架构.主要负责HDFS文件系统的管理工作,具体包括:名称空间( ...
- HDFS基本原理及数据存取实战
---------------------------------------------------------------------------------------------------- ...
- 【转载 Hadoop&Spark 动手实践 2】Hadoop2.7.3 HDFS理论与动手实践
简介 HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.是根据google发表的论文翻版的.论文为GFS(Google File System)Go ...
随机推荐
- Hadoop概念学习系列之例子形象再谈Client、NameNode、元数据(三十一)
Client相当于是送货人或提货人. NameNode相当于是仓库管理员. 元数据相当于是账本清单.
- 问题-在TreeView使用时,发现选中的树节点会闪烁或消失
问题:在工程中选中一个树节点,鼠标焦点在树上,做某种操作时发现选中的点会消失?原因:如果只是BeginUpdate后,没有调用EndUpdate,树会全空.应该是BeginUpdate方法会刷新树,但 ...
- 射频识别技术漫谈(9)——动物标签HDX【worldsing笔记】
半双工(HDX,Half Duplex)技术是ISO11784/11785中规定的另一种标签与读写器之间的通讯方式.读写器先打开射频场对标签充电以激活标签,然后关闭磁场,标签在读写器磁场关闭的情况下向 ...
- asp.net webservice 跨域解决方法
首先需要把[System.Web.Script.Services.ScriptService]前边的注释去掉,放开权限,其次需要在web.config 里<system.web节点下>添加 ...
- C# & SQLite - Storing Images
Download source code - 755 KB Introduction This article is to demonstrate how to load images into ...
- Linux下查看CPU型号,内存大小,硬盘空间命令
1 查看CPU 1.1 查看CPU个数 # cat /proc/cpuinfo | grep "physical id" | uniq | wc -l 2 **uniq命令:删除重 ...
- 网络子系统55_ip协议分片重组_加入ipq
//ip分片加入到正确的ipq结构 //调用路径:ip_defrag->ip_frag_queue // 处理过程: // 1.正在被释放的ipq,不处理新加入的分片(ipq正在被释放由last ...
- XAMPP环境下用phpStorm+XDebug进行断点调试的配置
具体过程: 服务器端(本地调试的情况下就是在本机)安装好XAMPP,停止apache服务(注意,如果直接退出XAMPP,是不会停止apache的) 在安装目录下找到php.ini,类似于D:\xamp ...
- IBM Rational ClearCase 部署指南
引言 随着时间的推移,可视化设计与软件配置管理(SCM)已经逐渐成为现代软件项目成功的关键因素.IBM Rational 是 IBM Rational XDE 和 IBM Rational Clear ...
- win7如何共享文件 图文教你设置win7文件共享
点评:win7文件共享已成为网友们之间的热议,接下来为大家分享下如何共享文件,首先开启guest账户( 开始菜单 → 运行 → services.msc → 双击 server 服务项 ,设置启动类型 ...