VLAD算法浅析, BOF、FV比较
划重点
VLAD(Vector of Aggragate Locally Descriptor)算法
VLAD算法可以分为如下几步:
1、提取图像的SIFT描述子
2、利用提取到的SIFT描述子(是所有训练图像的SIFT)训练一本码书,训练方法是K-means
3、把一副图像所有的SIFT描述子按照最近邻原则分配到码书上(也即分配到K个聚类中心)
4、对每个聚类中心做残差和(即属于当前聚类中心的所有SIFT减去聚类中心然后求和)
5、对这个残差和做L2归一化,然后拼接成一个K*128的长向量。128是单条SIFT的长度
如果不考虑海量数据的话,这个训练和建库过程已经可以了,直接保存第五步的结果(图像库),然后对查询图像做上述的操作,之后计算和图像库中每一条向量的欧式距离,输出前5个最小距离,既是一次完整的检索过程。
一、简介
虽然现在深度学习已经基本统一了图像识别与分类这个江湖,但是我觉得在某些小型数据库上或者小型的算法上常规的如BoW,FV,VLAD,T-Embedding等还是有一定用处的,如果专门做图像检索的不知道这些常规算法也免得有点贻笑大方了。
如上所说的这些算法都大同小异,一般都是基于局部特征(如SIFT,SURF)等进行特征编码获得一个关于图像的feature,最后计算feature之间的距离,即使是CNN也是这个过程。下面主要就是介绍一下关于VLAD算法,它主要是得优点就是相比FV计算量较小,相比BoW码书规模很小,并且检索精度较高。
二、VLAD算法
- 第一步自然是提取局部特征,有了OpenCV这一步就仅仅是函数调用的问题了:
SurfFeatureDetector detector;
SurfDescriptorExtractor extractor;
detector.detect( image_0, keypoints );
extractor.compute( image_0, keypoints, descriptors );如果对特征有什么要求也可以根据OpenCV的源码或者网上的源码进行修改,最终的结果就是提取到了一幅图像的局部特征(还有关于局部特征参数的控制);
- 第二步本应是量化的过程,但是在量化之前需要事先训练一本码书,而码书同BoW一样是用K-means算法训练得到的,同样OpenCV里面也集成了这个算法,所以这个过程也再简单不过了:
kmeans(descriptors, numClusters, labels,
TermCriteria( CV_TERMCRIT_EPS+CV_TERMCRIT_ITER, , 0.01 ),
, KMEANS_PP_CENTERS, centers);需要做的就是定义一些参数,如果自己写的话就不清楚了。另外码书的大小从64-256甚至更大不等,理论上码书越大检索精度越高。
- 第三步就是量化每一幅图像的特征了,其实如果数据库较小,可以直接使用全部图像的特征作训练,然后Kmeans函数中的labels中存储的就是量化的结果:即每一个特征距离那一个聚类中心最近。但是通常训练和量化是分开的,在VLAD算法中使用的是KDTree算法,KDTree算法是一种快速检索算法,OpenCV里同样集成了KDTree算法:
const int k=, Emax=INT_MAX;<br>KDTree T(centers,false);
T.findNearest(descriptors_row, k, Emax, idx_t, noArray(), noArray());通过KDTree下的findNearest函数找到与之最近的聚类中心,需要注意的是输入的STL的vector类型,返回的是centers的索引值;
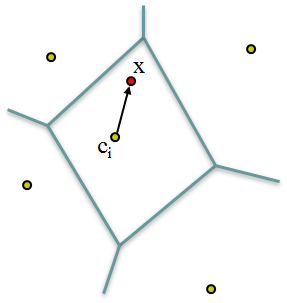
- 量化结束之后就是计算特征和中心的残差,并对每一幅图像落在同一个聚类中心上的残差进行累加求和,并进行归一化处理,最后每一个聚类中心上都会得到一个残差的累加和,进行归一化时需要注意正负号的问题(针对不同的特征)。假设有k个聚类中心,则每一个聚类中心上都有一个128维(SIFT)残差累加和向量;
- 把这k个残差累加和串联起来,获得一个超长向量,向量的长度为k*d(d=128),然后对这个超长矢量做一个power normolization处理可以稍微提升检索精度,然后对这个超长矢量再做一次归一化,现在这个超长矢量就可以保存起来了。
- 假设对N幅图像都进行了上面的编码处理之后就会得到N个超长矢量,为了加快距离计算的速度通常需要进行PCA降维处理,关于PCA降维的理论同KDTree一样都很成熟,OpenCV也有集成,没有时间自己写就可以调用了:
PCA pca( vlad, noArray(), CV_PCA_DATA_AS_ROW, );
pca.project(vlad,vlad_tt);输入训练矩阵,定义按照行或列进行降维,和降维之后的维度,经过训练之后就可以进行投影处理了,也可以直接调用特征向量进行矩阵乘法运算。这里有一点就是PCA的过程是比较费时的,进行查询的时候由于同样需要进行降维处理,所以可以直接保存投影矩阵(特征值矩阵),也可以把特征向量、特征值、均值都保存下来然后恢复出训练的pca,然后进行pca.project进行投影处理;
- 如果不考虑速度或者数据库规模不是很大时,就可以直接使用降维后的图像表达矢量进行距离计算了,常用的距离就是欧式距离和余弦距离,这里使用余弦距离速度更快。当然进行距离计算的基础就是已经设计好了训练过程和查询过程。
三、总结
可以看到,整个VLAD算法结合OpenCV实现起来还是非常简单的,并且小型数据库上的检索效果还可以,但是当数据库规模很大时只使用这一种检索算法检索效果会出现不可避免的下降。另外在作者的原文中,针对百万甚至千万级的数据库时单单使用PCA降维加速距离的计算仍然是不够的,所以还会使用称之为积量化或乘积量化(Product Quantization)的检索算法进行加速,这个也是一个很有意思的算法,以后有机会再介绍它。
VLAD算法浅析, BOF、FV比较的更多相关文章
- EM算法浅析(二)-算法初探
EM算法浅析,我准备写一个系列的文章: EM算法浅析(一)-问题引出 EM算法浅析(二)-算法初探 一.EM算法简介 在EM算法之一--问题引出中我们介绍了硬币的问题,给出了模型的目标函数,提到了这种 ...
- EM算法浅析(一)-问题引出
EM算法浅析,我准备写一个系列的文章: EM算法浅析(一)-问题引出 EM算法浅析(二)-算法初探 一.基本认识 EM(Expectation Maximization Algorithm)算法即期望 ...
- AtomicInteger的CAS算法浅析
之前浅析过自旋锁(自旋锁浅析),我们知道它的实现原理就是CAS算法.CAS(Compare and Swap)即比较并交换,作为著名的无锁算法,它也是乐观锁的实现方式之一.JDK并发包里也有许多代码中 ...
- KMP算法浅析
具体参见: KMP算法详解 背景: KMP算法之所以叫做KMP算法是因为这个算法是由三个人共同提出来的,就取三个人名字的首字母作为该算法的名字.其实KMP算法与BF算法的区别就在于KMP算法巧妙的消除 ...
- PCA算法浅析
最近频繁在论文中看到「PCA」的影子,所以今天决定好好把「PCA」的原理和算法过程弄清楚. 「PCA」是什么 PCA,又称主成分分析,英文全称「Principal Components Analysi ...
- 视觉SLAM之词袋(bag of words) 模型与K-means聚类算法浅析
原文地址:http://www.cnblogs.com/zjiaxing/p/5548265.html 在目前实际的视觉SLAM中,闭环检测多采用DBOW2模型https://github.com/d ...
- Paxos算法浅析
前言在文章2PC/3PC到底是啥中介绍了2PC这种一致性协议,从文中了解到2PC更多的被用在了状态一致性上(分布式事务),在数据一致性中很少被使用:而Paxos正是在数据一致性中被广泛使用,在过去十年 ...
- 视觉SLAM之词袋(bag of words) 模型与K-means聚类算法浅析(1)
在目前实际的视觉SLAM中,闭环检测多采用DBOW2模型https://github.com/dorian3d/DBoW2,而bag of words 又运用了数据挖掘的K-means聚类算法,笔者只 ...
- 图的最短路径---弗洛伊德(Floyd)算法浅析
算法介绍 和Dijkstra算法一样,Floyd算法也是为了解决寻找给定的加权图中顶点间最短路径的算法.不同的是,Floyd可以用来解决"多源最短路径"的问题. 算法思路 算法需要 ...
随机推荐
- 设计的一些kubernetes面试题
公司现在上了一部分的业务至k8s,老实说,我心里很慌,在项目改造中,每天都会遇到很多问题,好友找我出一份k8s面试题,参考了网上的一些,再加上自己公司遇到的一些问题,整理如下: 参考链接:http:/ ...
- Redhat下安装SAP的相关
Red Hat Enterprise Linux 6.x: Installation and Upgrade - SAP Note 1496410 Red Hat Enterprise Linux 7 ...
- jmeter学习笔记(二十二)——监听器插件之jp@gc系列
一.jp@gc - Actiive Threads Over Time 不同时间活动用户数量展示 下面是一个阶梯加压测试的图标 二.jp@gc - Transactions per Second ...
- 解决maven install报错:java.lang.NoClassDefFoundError: org/codehaus/plexus/compiler/util/scan/InclusionScanException
问题:maven install时,报错:java.lang.NoClassDefFoundError: org/codehaus/plexus/compiler/util/scan/Inclusio ...
- Linux DNS 分离解析
设置DNS分离解析可以对不同的客户端提供不同的域名解析记录.来自不同地址的客户机请求同一域名时,为其提供不同的解析结果. 安装 bind 包 [root@localhost ~]# yum insta ...
- etcd数据备份和恢复--转发
对于etcd api v3数据备份与恢复方法 # export ETCDCTL_API=3 # etcdctl --endpoints localhost:2379 snapshot save sna ...
- 推荐一个Web漏洞靶场
https://github.com/zhuifengshaonianhanlu/pikachu 暂时先空着 安装好是这样的 博主先去玩了,回来再写博客,2333
- beta版本——第七次冲刺
第七次冲刺 (1)SCRUM部分☁️ 成员描述: 姓名 李星晨 完成了哪个任务 编写个人信息修改界面的js 花了多少时间 3h 还剩余多少时间 0h 遇到什么困难 密码验证部分出现问题 这两天解决的进 ...
- spring cloud (六) 将一个普通的springcloud项目 非feign或ribbon项目,改造成turbine可聚合监听的项目
改造之前一个项目 service-a 1 pom.xml添加如下 <dependency> <groupId>org.springframework.cloud</gro ...
- 剑指Offer(二十):包含min函数的栈
剑指Offer(二十):包含min函数的栈 搜索微信公众号:'AI-ming3526'或者'计算机视觉这件小事' 获取更多算法.机器学习干货 csdn:https://blog.csdn.net/ba ...